Vous aimerez peut-être aussi
- Comparison of Density-Based Clustering Algorithms: Mariam RehmanDocument5 pagesComparison of Density-Based Clustering Algorithms: Mariam RehmansuserPas encore d'évaluation
- Overset Grids Literature Review - OvertureDocument11 pagesOverset Grids Literature Review - OvertureSomdeb BandopadhyayPas encore d'évaluation
- CENG3300 Lecture 10Document20 pagesCENG3300 Lecture 10huichloemailPas encore d'évaluation
- ShortingDocument27 pagesShortingRatnakarVarunPas encore d'évaluation
- 05 K-Nearest NeighborsDocument15 pages05 K-Nearest NeighborsLalaloopsie The GreatPas encore d'évaluation
- 10.introduction To Data-Parallel ArchitecturesDocument21 pages10.introduction To Data-Parallel ArchitecturesAshok AshokbyadavPas encore d'évaluation
- CSE4014 - High Performance Computing (EPJ) : Submitted by Project GuideDocument12 pagesCSE4014 - High Performance Computing (EPJ) : Submitted by Project GuideAshish PaudelPas encore d'évaluation
- Pres 0911 Regrid UpdateDocument9 pagesPres 0911 Regrid UpdateSalam FaithPas encore d'évaluation
- 05 NetworksDocument48 pages05 NetworksNg Yiu FaiPas encore d'évaluation
- Lecture Slides-Week15,16Document50 pagesLecture Slides-Week15,16moazzam kianiPas encore d'évaluation
- Algorithms For Fast Vector Quantization: Proc. Data Compression Conference, J. A. StorerDocument17 pagesAlgorithms For Fast Vector Quantization: Proc. Data Compression Conference, J. A. StorerRex JimPas encore d'évaluation
- Introduction To Parallel Algorithms and Parallel Program DesignDocument91 pagesIntroduction To Parallel Algorithms and Parallel Program DesignGanesh GajengiPas encore d'évaluation
- Random Graph Models of Social Networks: Paper Authors: M.E. Newman, D.J. Watts, S.H. StrogatzDocument21 pagesRandom Graph Models of Social Networks: Paper Authors: M.E. Newman, D.J. Watts, S.H. StrogatzsmjainPas encore d'évaluation
- 03-Task Decomposition and MappingDocument62 pages03-Task Decomposition and MappingHouri melkonianPas encore d'évaluation
- Dendro: Parallel Algorithms For Multigrid and AMR Methods On 2:1 Balanced OctreesDocument20 pagesDendro: Parallel Algorithms For Multigrid and AMR Methods On 2:1 Balanced OctreeslanwatchPas encore d'évaluation
- IntroductionDocument10 pagesIntroductionBoul chandra GaraiPas encore d'évaluation
- A Multi-Block Orthogonal Grid Generation Using Cad SystemDocument8 pagesA Multi-Block Orthogonal Grid Generation Using Cad SystemMohammad HaddadiPas encore d'évaluation
- Using Area Hierarchy For Multi-Resolution Storage and Search in Large Wireless Sensor NetworksDocument27 pagesUsing Area Hierarchy For Multi-Resolution Storage and Search in Large Wireless Sensor NetworksIonela NeacsuPas encore d'évaluation
- Interpolation: Dr. B. Santhosh Department of Mechanical EngineeringDocument21 pagesInterpolation: Dr. B. Santhosh Department of Mechanical EngineeringAchyuth G SPas encore d'évaluation
- Overview of 3D Object Representations: ModelingDocument16 pagesOverview of 3D Object Representations: Modelingmbhuvana_eshwariPas encore d'évaluation
- 3d Shape Analysis-Machine LearningDocument41 pages3d Shape Analysis-Machine LearningAlexander SaldarriagaPas encore d'évaluation
- Dimensionality Reduction: Principal Component Analysis (PCA)Document11 pagesDimensionality Reduction: Principal Component Analysis (PCA)tanmayi nandirajuPas encore d'évaluation
- Sequence AlignmentDocument92 pagesSequence AlignmentarsalanPas encore d'évaluation
- Unit 3: Databases & SQL: Developed By: Ms. Nita Arora Kulachi Hansraj Model School Ashok ViharDocument18 pagesUnit 3: Databases & SQL: Developed By: Ms. Nita Arora Kulachi Hansraj Model School Ashok ViharAthira SomanPas encore d'évaluation
- Final ClusteringDocument21 pagesFinal ClusteringNEEL GHADIYAPas encore d'évaluation
- Introduction To Data Science Unsupervised Learning: CS 194 Fall 2015 John CannyDocument54 pagesIntroduction To Data Science Unsupervised Learning: CS 194 Fall 2015 John CannyPedro Jesús García RamosPas encore d'évaluation
- (KtabPDF Com) xrwA7TEBGpDocument32 pages(KtabPDF Com) xrwA7TEBGpشجن الزبيرPas encore d'évaluation
- EC657 Digital System Design (3 - 0 - 0) 3 Pre-Requisite: EC209 Digital Circuits and Systems Course ObjectiveDocument2 pagesEC657 Digital System Design (3 - 0 - 0) 3 Pre-Requisite: EC209 Digital Circuits and Systems Course ObjectiveAvinash KumarPas encore d'évaluation
- Mesh Generation: Advances and Applications in Computer Vision Mesh GenerationD'EverandMesh Generation: Advances and Applications in Computer Vision Mesh GenerationPas encore d'évaluation
- Printed Circuit Board Design Flow: CS194-5, Spring 2008Document24 pagesPrinted Circuit Board Design Flow: CS194-5, Spring 2008KaranSinghPas encore d'évaluation
- Constructing Suitable PlanarDocument38 pagesConstructing Suitable Planarsmarttelgroup1Pas encore d'évaluation
- Graph500 BigData2016 PaperDocument8 pagesGraph500 BigData2016 PaperMiguel AngelPas encore d'évaluation
- Web Graphs: Modeling The Internet and The WebDocument40 pagesWeb Graphs: Modeling The Internet and The WebShamna KrishnanPas encore d'évaluation
- Lecture 3: Handwriting Recognition and ClassificationDocument51 pagesLecture 3: Handwriting Recognition and Classificationkunal13Pas encore d'évaluation
- Social Network Analysis Unit-2Document24 pagesSocial Network Analysis Unit-2Guribilli VaraprasadPas encore d'évaluation
- Graph DBDocument63 pagesGraph DBVinod ReddyPas encore d'évaluation
- Parallel & Distributed Databases: C S 5 6 1 - S P R I N G 2 0 1 2 Wpi, Mohamed EltabakhDocument23 pagesParallel & Distributed Databases: C S 5 6 1 - S P R I N G 2 0 1 2 Wpi, Mohamed EltabakhDibas SilPas encore d'évaluation
- Comp422 534 2020 Lecture1 IntroductionDocument49 pagesComp422 534 2020 Lecture1 IntroductionSadia MughalPas encore d'évaluation
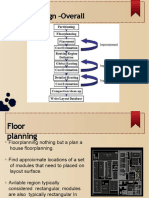
- Physical Design - Overall FlowDocument40 pagesPhysical Design - Overall Flowshabbir470Pas encore d'évaluation
- Towards Efficient Routing WSNDocument34 pagesTowards Efficient Routing WSNajyshowPas encore d'évaluation
- FLANN Presnetation For GroupDocument26 pagesFLANN Presnetation For GroupFirma Firmansyah AdiPas encore d'évaluation
- ML Application in Signal Processing and Communication EngineeringDocument27 pagesML Application in Signal Processing and Communication Engineeringaniruddh nainPas encore d'évaluation
- Custer Analysis: Prepared by Navin NinamaDocument20 pagesCuster Analysis: Prepared by Navin NinamaNishith LakhlaniPas encore d'évaluation
- Structured Pruning of Deep Convolutional Neural Netw Orks: Sajid Anwar, Kyuyeon Hwang and Wonyong SungDocument11 pagesStructured Pruning of Deep Convolutional Neural Netw Orks: Sajid Anwar, Kyuyeon Hwang and Wonyong Sungali shaarawyPas encore d'évaluation
- Multi-Level Bézier Extraction For Hierarchical Local Refinement of Isogeometric AnalysisDocument28 pagesMulti-Level Bézier Extraction For Hierarchical Local Refinement of Isogeometric AnalysisLuis Alberto FuentesPas encore d'évaluation
- Lecture 1Document18 pagesLecture 1wmanjonjoPas encore d'évaluation
- GIS Data ModelDocument46 pagesGIS Data ModelFAizal AbdillahPas encore d'évaluation
- MR DatabasesDocument52 pagesMR Databasesraj9523493430Pas encore d'évaluation
- ParallelDBs PDFDocument23 pagesParallelDBs PDFheyramzzPas encore d'évaluation
- DuongToGiangSon 517H0162 HW2 Nov-26Document17 pagesDuongToGiangSon 517H0162 HW2 Nov-26Son TranPas encore d'évaluation
- Classification Algorithms in Achieving Partitioning Optimization For VLSI ApplicationsDocument3 pagesClassification Algorithms in Achieving Partitioning Optimization For VLSI ApplicationsSudheer ReddyPas encore d'évaluation
- 1 s2.0 S0031320317303497 MainDocument14 pages1 s2.0 S0031320317303497 MainajgallegoPas encore d'évaluation
- Parallel AlgorithmsDocument21 pagesParallel AlgorithmsMvm FatehpurPas encore d'évaluation
- CUDPP SlidesDocument26 pagesCUDPP SlidesbkrPas encore d'évaluation
- Data Analytics CSE704 Module-2Document42 pagesData Analytics CSE704 Module-2suryanshmishra425Pas encore d'évaluation
- SQLDM - Implementing K-Means Clustering Using SQL: Jay B.SimhaDocument5 pagesSQLDM - Implementing K-Means Clustering Using SQL: Jay B.SimhaMoh Ali MPas encore d'évaluation
- PST 02Document37 pagesPST 02sergiosvieiraPas encore d'évaluation
- Bicubic Interpolation Wiki PDFDocument4 pagesBicubic Interpolation Wiki PDFbraulio.dantasPas encore d'évaluation
- Analisa Spasial Data Vektor Sederhana: Pertemuan 7Document60 pagesAnalisa Spasial Data Vektor Sederhana: Pertemuan 7ratihokebgtPas encore d'évaluation
- 3-D Stream Restoration Design, Monitoring and BeyondDocument93 pages3-D Stream Restoration Design, Monitoring and BeyondacnonPas encore d'évaluation
- Data Visualization Using STEP Lothar KleinDocument31 pagesData Visualization Using STEP Lothar KleinacnonPas encore d'évaluation
- Chapter7 NewDocument22 pagesChapter7 NewacnonPas encore d'évaluation
- Current and Emerging Trends Transparencies: © Pearson Education Limited, 2004 1Document85 pagesCurrent and Emerging Trends Transparencies: © Pearson Education Limited, 2004 1acnonPas encore d'évaluation
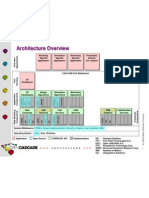
- Architecture Overview: W W W - C o MDocument3 pagesArchitecture Overview: W W W - C o MacnonPas encore d'évaluation
- R2 Imagechecker CT Cad Pma: Clinical Results: Nicholas Petrick, Ph.D. Office of Science and TechnologyDocument25 pagesR2 Imagechecker CT Cad Pma: Clinical Results: Nicholas Petrick, Ph.D. Office of Science and TechnologyacnonPas encore d'évaluation