Vous aimerez peut-être aussi
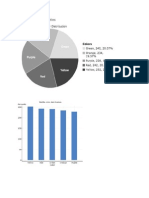
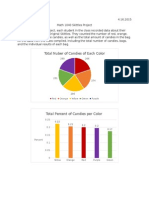
- Skittles ProDocument9 pagesSkittles Proapi-241124972Pas encore d'évaluation
- Math 1040 Term ProjectDocument7 pagesMath 1040 Term Projectapi-340188424Pas encore d'évaluation
- Skittles Project Stats 1040Document8 pagesSkittles Project Stats 1040api-301336765Pas encore d'évaluation
- Skittle Pareto ChartDocument7 pagesSkittle Pareto Chartapi-272391081Pas encore d'évaluation
- Term Project - EportfolioDocument7 pagesTerm Project - Eportfolioapi-251981709Pas encore d'évaluation
- StatsfinalprojectDocument7 pagesStatsfinalprojectapi-325102852Pas encore d'évaluation
- Final ProjectDocument6 pagesFinal Projectapi-283261340Pas encore d'évaluation
- Skittles 2 FinalDocument12 pagesSkittles 2 Finalapi-242194552Pas encore d'évaluation
- Math 1040 Statistics Term Project: Blake FreemanDocument10 pagesMath 1040 Statistics Term Project: Blake Freemanapi-252919218Pas encore d'évaluation
- Term Project ReportDocument9 pagesTerm Project Reportapi-238585685Pas encore d'évaluation
- Final ProjectDocument9 pagesFinal Projectapi-262329757Pas encore d'évaluation
- Math 1040 Skittles Term Project EportfolioDocument7 pagesMath 1040 Skittles Term Project Eportfolioapi-260817278Pas encore d'évaluation
- Skittles Project 1Document7 pagesSkittles Project 1api-299868669100% (2)
- Stats ProjectDocument14 pagesStats Projectapi-302666758Pas encore d'évaluation
- Final Math ProjectDocument7 pagesFinal Math Projectapi-316775963Pas encore d'évaluation
- Math 1040 Skittles Term ProjectDocument9 pagesMath 1040 Skittles Term Projectapi-319881085Pas encore d'évaluation
- Skittles FinalDocument12 pagesSkittles Finalapi-241861434Pas encore d'évaluation
- Skittles ProjectDocument9 pagesSkittles Projectapi-242873849Pas encore d'évaluation
- The Skittles Project FinalDocument8 pagesThe Skittles Project Finalapi-316760667Pas encore d'évaluation
- SkittlesdataclassprojectDocument8 pagesSkittlesdataclassprojectapi-399586872Pas encore d'évaluation
- The Science of Collecting, Organizing, Summarizing, and Analyzing Information To Draw Conclusions or Answer QuestionsDocument7 pagesThe Science of Collecting, Organizing, Summarizing, and Analyzing Information To Draw Conclusions or Answer Questionsapi-438148756Pas encore d'évaluation
- Skittles Term Project 11 9 14Document5 pagesSkittles Term Project 11 9 14api-192489685Pas encore d'évaluation
- Croot Part6 EportfolioDocument16 pagesCroot Part6 Eportfolioapi-276896975Pas encore d'évaluation
- The Full Skittles ProjectDocument6 pagesThe Full Skittles Projectapi-340271527100% (1)
- Final Stats ProjectDocument8 pagesFinal Stats Projectapi-238717717100% (2)
- Skittles Project FinalDocument5 pagesSkittles Project Finalapi-271348941Pas encore d'évaluation
- Skittles Project With ReflectionDocument7 pagesSkittles Project With Reflectionapi-234712126100% (1)
- Skittles WordDocument5 pagesSkittles Wordapi-285645725Pas encore d'évaluation
- Skittles AssignmentDocument8 pagesSkittles Assignmentapi-291800396Pas encore d'évaluation
- Skittles ProjectDocument4 pagesSkittles Projectapi-287735026Pas encore d'évaluation
- Final ProjectDocument3 pagesFinal Projectapi-265661554Pas encore d'évaluation
- EportfolioDocument8 pagesEportfolioapi-242211470Pas encore d'évaluation
- Term Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1Document8 pagesTerm Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1api-303044832Pas encore d'évaluation
- EportfolioDocument12 pagesEportfolioapi-251934892Pas encore d'évaluation
- TP 2 StatsDocument5 pagesTP 2 Statsapi-240850453Pas encore d'évaluation
- Math 1040 Skittles Term Project AynoaDocument15 pagesMath 1040 Skittles Term Project Aynoaapi-301347675Pas encore d'évaluation
- Team Project Part 6 Final ReportDocument8 pagesTeam Project Part 6 Final Reportapi-316794103Pas encore d'évaluation
- Statistics Project 17Document13 pagesStatistics Project 17api-271978152Pas encore d'évaluation
- Skittles Project 2Document10 pagesSkittles Project 2api-316655135Pas encore d'évaluation
- Skittles Final ProjectDocument5 pagesSkittles Final Projectapi-251571777Pas encore d'évaluation
- Skittles ProjectDocument6 pagesSkittles Projectapi-319345408Pas encore d'évaluation
- Full Skittles ProjectDocument13 pagesFull Skittles Projectapi-537189505Pas encore d'évaluation
- Math 1030 Skittles Term ProjectDocument8 pagesMath 1030 Skittles Term Projectapi-340538273Pas encore d'évaluation
- Skittles Term Project - Kai Galbiso Stat1040Document6 pagesSkittles Term Project - Kai Galbiso Stat1040api-316758771Pas encore d'évaluation
- 1040 Term ProjectDocument8 pages1040 Term Projectapi-316127151Pas encore d'évaluation
- Stats StuffDocument7 pagesStats Stuffapi-242298926Pas encore d'évaluation
- Statistics Term Project E-Portfolio ReflectionDocument8 pagesStatistics Term Project E-Portfolio Reflectionapi-258147701Pas encore d'évaluation
- Math ProfileDocument9 pagesMath Profileapi-454376679Pas encore d'évaluation
- Skittles Project 2Document5 pagesSkittles Project 2api-355504623Pas encore d'évaluation
- Math 1040Document3 pagesMath 1040api-219553415Pas encore d'évaluation
- Skittles Term ProjectDocument10 pagesSkittles Term Projectapi-273060240Pas encore d'évaluation
- Group Project #1 - SkittlesDocument9 pagesGroup Project #1 - Skittlesapi-245266056Pas encore d'évaluation
- Skittles Project 5-02Document8 pagesSkittles Project 5-02api-354040698Pas encore d'évaluation
- Skittles Project Part 1Document6 pagesSkittles Project Part 1api-457501806Pas encore d'évaluation
- Skittles Term Project StatsDocument8 pagesSkittles Term Project Statsapi-302549779Pas encore d'évaluation
- Skittles Project Group Final WordDocument6 pagesSkittles Project Group Final Wordapi-316239273Pas encore d'évaluation
- Skittles ProjectDocument9 pagesSkittles Projectapi-252747849Pas encore d'évaluation
- 1040 Skittles ProjectDocument4 pages1040 Skittles Projectapi-279941094Pas encore d'évaluation
- Service PersonalDocument14 pagesService PersonalquadranteRDPas encore d'évaluation
- The Glass Menagerie Genre Tragedy Family Drama SettingDocument3 pagesThe Glass Menagerie Genre Tragedy Family Drama Settingchaha26Pas encore d'évaluation
- Generating Effective Discussion QuestionsDocument12 pagesGenerating Effective Discussion QuestionsDanika BarkerPas encore d'évaluation
- Edpg 5 - Greeting Others and Introducing Yourself - New Techlgy Lesson PlanDocument3 pagesEdpg 5 - Greeting Others and Introducing Yourself - New Techlgy Lesson Planapi-346196685Pas encore d'évaluation
- Oral Presentations RubricDocument1 pageOral Presentations RubricMohd Idris Shah IsmailPas encore d'évaluation
- Decision MakingDocument2 pagesDecision MakingXJLiewJingWen100% (1)
- Grade 1 1who We Are Sy14-15Document6 pagesGrade 1 1who We Are Sy14-15api-256382279100% (2)
- The Gnostic Book of Changes Chapter Five: Consulting the Oracle GuideDocument11 pagesThe Gnostic Book of Changes Chapter Five: Consulting the Oracle GuideKenneth Anderson100% (2)
- When Destiny Calls (Michael Jex) Voyager MagazineDocument72 pagesWhen Destiny Calls (Michael Jex) Voyager MagazineNathan100% (1)
- A CV - Exercises 1 PDFDocument2 pagesA CV - Exercises 1 PDFkadriyePas encore d'évaluation
- What Exactly Is Game TheoryDocument3 pagesWhat Exactly Is Game TheorycursogsuitePas encore d'évaluation
- Prof Ed (Let Reviewer)Document50 pagesProf Ed (Let Reviewer)Hanna Grace Honrade75% (8)
- Southern Mindanao Institute of Technology IncDocument3 pagesSouthern Mindanao Institute of Technology IncMascardo Benj MarlPas encore d'évaluation
- SWIB Intern Application 13-14Document3 pagesSWIB Intern Application 13-14greblocPas encore d'évaluation
- Activity 2Document4 pagesActivity 2ДашаPas encore d'évaluation
- Test Bank For Keeping The Republic Power and Citizenship in American Politics, 9th Edition, Christine Barbour, Gerald C. WrightDocument36 pagesTest Bank For Keeping The Republic Power and Citizenship in American Politics, 9th Edition, Christine Barbour, Gerald C. Wrighthung.umbrette.h8gdpg100% (20)
- The American Dream in The Great Gatsby and The Joy Luck ClubDocument6 pagesThe American Dream in The Great Gatsby and The Joy Luck ClubFarah TahirPas encore d'évaluation
- mghb02 Chapter 1 NotesDocument1 pagemghb02 Chapter 1 NotesVansh JainPas encore d'évaluation
- Psychiatric Interview Professor Safeya Effat: I History Taking 1. Personal DataDocument4 pagesPsychiatric Interview Professor Safeya Effat: I History Taking 1. Personal DataAcha Angel BebexzPas encore d'évaluation
- Henry Stapp - QuantumDocument35 pagesHenry Stapp - Quantummet3311100% (2)
- The New Story of The Hare and The TortoiseDocument4 pagesThe New Story of The Hare and The Tortoisefurqanhaider31100% (2)
- Bound by HatredDocument235 pagesBound by HatredVenkat100% (1)
- Proceedings of The XXV Scientific ConferenceDocument137 pagesProceedings of The XXV Scientific ConferenceAdriana MeloPas encore d'évaluation
- Table of Contents and Class DescriptionsDocument80 pagesTable of Contents and Class DescriptionsLandrel LonePas encore d'évaluation
- Althusser's Marxist Theory of IdeologyDocument2 pagesAlthusser's Marxist Theory of IdeologyCecilia Gutiérrez Di LandroPas encore d'évaluation
- Retail Marketing Communications Mix GuideDocument9 pagesRetail Marketing Communications Mix GuideSushil SatyarthiPas encore d'évaluation
- Mindset The New Psychology of Success by Carol Dweck PDFDocument292 pagesMindset The New Psychology of Success by Carol Dweck PDFAlexandra Smith95% (59)
- Creative Writing Techniques for Imagery, Figures of Speech, and DictionDocument2 pagesCreative Writing Techniques for Imagery, Figures of Speech, and DictionMam U De Castro100% (5)
- Explain The Barrow's Three General Motor Fitness Test in DetailDocument4 pagesExplain The Barrow's Three General Motor Fitness Test in Detailswagat sahuPas encore d'évaluation
- Communicating EffectivelyDocument3 pagesCommunicating EffectivelyChong Hong SiaPas encore d'évaluation