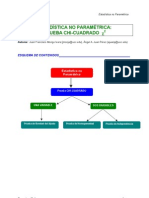
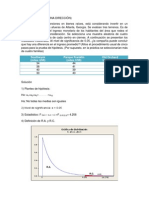
Vous aimerez peut-être aussi
- Unidad 5 Pruebas de Hipotesis Con Dos MuestrasDocument28 pagesUnidad 5 Pruebas de Hipotesis Con Dos MuestrasYamal SafrajPas encore d'évaluation
- Unidad 4 Pruebas de Bondad de Ajuste y Pruebas No ParametricasDocument7 pagesUnidad 4 Pruebas de Bondad de Ajuste y Pruebas No ParametricasJose Abraham Hernandez Mendez0% (2)
- Pruebas de Bondad de AjusteDocument6 pagesPruebas de Bondad de AjusteRobby Ryan100% (1)
- Pruebas de Bondad de AjusteDocument20 pagesPruebas de Bondad de AjusteLuis Fernando100% (1)
- Prueba de Ryan y ShapiroDocument2 pagesPrueba de Ryan y Shapiroabnermurico100% (3)
- Unidad 3 Pruebas de HipotesisDocument7 pagesUnidad 3 Pruebas de Hipotesiscarolina urbinaPas encore d'évaluation
- 4.2.4 Prueba de Anderson - DarlingDocument18 pages4.2.4 Prueba de Anderson - DarlingKaren Soledad Ruíz Jiménez100% (2)
- Pruebas de Bondad de AjusteDocument5 pagesPruebas de Bondad de AjusteDennis Chacón LópezPas encore d'évaluation
- Teorema Del Límite CentralDocument2 pagesTeorema Del Límite CentralMARIA100% (1)
- Distribución Muestral de Diferencia de Proporciones ExpoDocument4 pagesDistribución Muestral de Diferencia de Proporciones ExpoeverPas encore d'évaluation
- DiseñosexperimentalesejerciciosDocument5 pagesDiseñosexperimentalesejerciciosErik Ayala LeonPas encore d'évaluation
- Unidad 3 Estadistica Inferencial 1Document17 pagesUnidad 3 Estadistica Inferencial 1vivicann100% (2)
- Prueba de Bondad de AjusteDocument19 pagesPrueba de Bondad de AjusteEdsson MendezPas encore d'évaluation
- 2.9 Manejo de MaterialesDocument11 pages2.9 Manejo de MaterialesMartin German ValverdePas encore d'évaluation
- Pruebas de Bondad de Ajuste y Rpeubas No ParamétricasDocument38 pagesPruebas de Bondad de Ajuste y Rpeubas No ParamétricasGely Rosas100% (1)
- 1.4 Fundamentos LegalesDocument4 pages1.4 Fundamentos Legalesalejandro100% (1)
- Diseño de Cuadrados GrecolatinoDocument3 pagesDiseño de Cuadrados GrecolatinoEdgard Lazaro PalmaPas encore d'évaluation
- 4.1.2. Prueba de IndependenciaDocument20 pages4.1.2. Prueba de IndependenciaCristy Uicab67% (3)
- Analisis de Varianza Greco Latino 2Document9 pagesAnalisis de Varianza Greco Latino 2Johanna OrozcoPas encore d'évaluation
- 2.8 Intervalos de Confianza para Diferencias Entre ProporcionesDocument9 pages2.8 Intervalos de Confianza para Diferencias Entre ProporcionesLola CabreraPas encore d'évaluation
- Determinación Del Tamaño de La Muestra Basado en La Media PoblacionalDocument5 pagesDeterminación Del Tamaño de La Muestra Basado en La Media PoblacionalLuis Alias PeruciñoPas encore d'évaluation
- Unidad 4 Estadistica InferencialDocument6 pagesUnidad 4 Estadistica InferencialGilberto Efren Rodriguez LomeliPas encore d'évaluation
- ProblemasDocument3 pagesProblemasDaniel Carmine50% (4)
- Ejemplo de Caso Modelo de Efectos AleatoriosDocument6 pagesEjemplo de Caso Modelo de Efectos AleatoriosCory RamosPas encore d'évaluation
- 3.5 Formulación de Hipótesis 3.6 Prueba para La MediaDocument4 pages3.5 Formulación de Hipótesis 3.6 Prueba para La MediaGuillermo Regalado100% (1)
- En Qué Aspectos de La Vida Empresarial Puede Ser Utilizada La Estimación EstadísticaDocument2 pagesEn Qué Aspectos de La Vida Empresarial Puede Ser Utilizada La Estimación EstadísticaGaldinoMartinezGonzalezPas encore d'évaluation
- Estimación y Predicción Por Intervalo en Regresión Lineal Simple.Document8 pagesEstimación y Predicción Por Intervalo en Regresión Lineal Simple.Gely Rosas50% (2)
- 2.9 Intervalos de Confianza para Varianzas - Dr. Jose A. Sarricolea ValenciaDocument6 pages2.9 Intervalos de Confianza para Varianzas - Dr. Jose A. Sarricolea ValenciaJose Adalberto Sarricolea ValenciaPas encore d'évaluation
- Semana 5Document10 pagesSemana 5SantiagoToledo0% (2)
- Distribucion Muestral de VarianzaDocument4 pagesDistribucion Muestral de Varianzadavid calle alamo0% (1)
- 2.2.elaboracion e Interpretacion de Graficas para VariablesDocument18 pages2.2.elaboracion e Interpretacion de Graficas para VariablesLore FernándezPas encore d'évaluation
- Estadística Inferencial 1Document146 pagesEstadística Inferencial 1Benny Love83% (6)
- Actividades Unidad CuatroDocument4 pagesActividades Unidad CuatroJhonatan Bedolla100% (1)
- 1.2 Objetivos e Importancia de La Contabilidad FinancieraDocument5 pages1.2 Objetivos e Importancia de La Contabilidad FinancieraMario SandovalPas encore d'évaluation
- Analisis ResidualDocument3 pagesAnalisis ResidualRodrigo Cristóbal0% (1)
- Unidad 5.ing EconomicaDocument27 pagesUnidad 5.ing Economicasaul adriel0% (1)
- Tamaño de Muestra para Estimar Una Proporción.Document15 pagesTamaño de Muestra para Estimar Una Proporción.Wendy Copaja PortugalPas encore d'évaluation
- Unidad 4 Estadistica InferencialDocument6 pagesUnidad 4 Estadistica InferencialIzamar Garcia Rodriguez75% (4)
- Ensayo Regresion Lineal SimpleDocument6 pagesEnsayo Regresion Lineal SimplePedro RodriguezPas encore d'évaluation
- 3.7. Selección Del Tamaño de Muestra (Para Estimar La Proporción Poblacional) .Document4 pages3.7. Selección Del Tamaño de Muestra (Para Estimar La Proporción Poblacional) .rmateumartinezPas encore d'évaluation
- Ejemplos Resueltos de Intervalos de Confianza para La ProporciónDocument2 pagesEjemplos Resueltos de Intervalos de Confianza para La Proporciónpaola daryanaPas encore d'évaluation
- 2.7 Pronósticos Basados en Factores de Tendencia y EstacionalesDocument3 pages2.7 Pronósticos Basados en Factores de Tendencia y EstacionalesJOSE TRINIDAD CORRAL MENDOZAPas encore d'évaluation
- Prueba Ryan-Joiner Prueba Shappiro - WilkDocument23 pagesPrueba Ryan-Joiner Prueba Shappiro - WilkrobertoPas encore d'évaluation
- 2.9 Elaboración de Gráficas de ControlDocument4 pages2.9 Elaboración de Gráficas de ControlKaren Ortega GcíaPas encore d'évaluation
- Calidad Del Ajuste en Regresión Lineal SimpleDocument3 pagesCalidad Del Ajuste en Regresión Lineal SimpleHector UchihaPas encore d'évaluation
- ProblemasDocument9 pagesProblemasJose Cabrera RuizPas encore d'évaluation
- 2 Pruebas de Rango MúltiplesDocument15 pages2 Pruebas de Rango MúltiplesLeandro CastilloPas encore d'évaluation
- Prueba de Bondad de AjusteDocument23 pagesPrueba de Bondad de AjusteCARLA FABIOLA CHALLCO LOPINTAPas encore d'évaluation
- Prueba de Hipotesis en La Regresion Lineal SimpleDocument22 pagesPrueba de Hipotesis en La Regresion Lineal SimpleAlberto Carranza100% (4)
- Series de Tiempo Q1 2017Document21 pagesSeries de Tiempo Q1 2017Rodriguez Neva100% (2)
- Unidad 2 Sistemas de ManufacturaDocument6 pagesUnidad 2 Sistemas de ManufacturanooormaaahernaanndezPas encore d'évaluation
- TEMA 2.5 Determinacion Del Tamaño de MuestraDocument11 pagesTEMA 2.5 Determinacion Del Tamaño de Muestradoytchinova43% (7)
- Pruebas de Bondad de AjusteDocument28 pagesPruebas de Bondad de AjusteDanS100% (1)
- Diapositivas de Estadistica No ParametricaDocument33 pagesDiapositivas de Estadistica No ParametricaCARLOS DANIEL LOPEZ PEREZPas encore d'évaluation
- 1 I Test Non Parametrici Sono Costituiti Da Quelle Procedure Di Verifica Delle Ipotesi Che Accettano Che Le Variabili Dello Studio Siano Misurate Almeno Su Una Scala A IntervalliDocument4 pages1 I Test Non Parametrici Sono Costituiti Da Quelle Procedure Di Verifica Delle Ipotesi Che Accettano Che Le Variabili Dello Studio Siano Misurate Almeno Su Una Scala A IntervalliVISAMEL RPas encore d'évaluation
- Tarea 4 - Cuadro Comparativo - Manuel Daza.Document15 pagesTarea 4 - Cuadro Comparativo - Manuel Daza.WILLIAMPas encore d'évaluation
- Calidad IIDocument6 pagesCalidad IIArhianna AriasPas encore d'évaluation
- Estadístico: 4.2.3 Prueba de Kolmogorov - SmirnovDocument4 pagesEstadístico: 4.2.3 Prueba de Kolmogorov - SmirnovkiravsnaoPas encore d'évaluation
- PWH59KcNR1eh FSNDDDXWG - Cual Es La Definicion de Prueba de HipotesisDocument9 pagesPWH59KcNR1eh FSNDDDXWG - Cual Es La Definicion de Prueba de Hipotesistg4pmv67qvPas encore d'évaluation
- Marco TeoricoDocument4 pagesMarco TeoricoDianaAlfaroB100% (1)
- Evaluacion de La Inteligencia EmocionalDocument35 pagesEvaluacion de La Inteligencia EmocionalLorenitaca100% (1)
- Ejercicios Simulacion GerencialDocument8 pagesEjercicios Simulacion Gerenciallaura ximena tovar amayaPas encore d'évaluation
- Manual de Usuario - Cubicadora de Carne - Marca BBG - Ref - Cube-500 PDFDocument7 pagesManual de Usuario - Cubicadora de Carne - Marca BBG - Ref - Cube-500 PDFSara MarinPas encore d'évaluation
- Mecanismo de Corte y Fabricación Del Cortador PDCDocument26 pagesMecanismo de Corte y Fabricación Del Cortador PDCLESCANO GABRIEL100% (1)
- Caso Clínico Coloprocto 2Document3 pagesCaso Clínico Coloprocto 2Joel RJPas encore d'évaluation
- EXAMEN 1 2017 ComentadoDocument7 pagesEXAMEN 1 2017 ComentadoCarlos ArriazaPas encore d'évaluation
- Asimilación Steelmaster 1200WF - Sep 2019Document19 pagesAsimilación Steelmaster 1200WF - Sep 2019Sergio RovedyPas encore d'évaluation
- Sistema AporticadoDocument8 pagesSistema AporticadoKarla Cárdenas MazanettPas encore d'évaluation
- Manual Uso NewDocument33 pagesManual Uso Newjoaking1992Pas encore d'évaluation
- Trabajo de Laboratorio de Electroneumatica-10 Practicas, ModificadoDocument46 pagesTrabajo de Laboratorio de Electroneumatica-10 Practicas, ModificadoWalter Jesus100% (1)
- Ingeniería de TransporteDocument20 pagesIngeniería de TransporteEDY JHONATAN AYQUIPA CHIPAPas encore d'évaluation
- Resultados Obtenidos & Análisis de ResultadosDocument10 pagesResultados Obtenidos & Análisis de ResultadosPedro VenturaPas encore d'évaluation
- Contrato de Arrendamiento de Vivienda en Aplicación Del SubsidioDocument4 pagesContrato de Arrendamiento de Vivienda en Aplicación Del SubsidioJulián Andrés Posada100% (1)
- Guía #2 FraccionesDocument8 pagesGuía #2 FraccionesBernardo Andres Tello LopezPas encore d'évaluation
- Evidencia 3 MichelinDocument6 pagesEvidencia 3 Michelintournat madridPas encore d'évaluation
- AJO TDocument75 pagesAJO TAnonymous 12HZ5qUkPas encore d'évaluation
- Competencias Docentes 2Document21 pagesCompetencias Docentes 2Eduardo QuevedoPas encore d'évaluation
- Capìtulo 6 E-050Document19 pagesCapìtulo 6 E-050jhany montoyaPas encore d'évaluation
- PERFIL DEL PUESTO - MergedDocument4 pagesPERFIL DEL PUESTO - MergedDaniela FlorezPas encore d'évaluation
- CREACION de Carrito de Compras Parte 3 - CREACIÓN DEL CONTROLADORDocument6 pagesCREACION de Carrito de Compras Parte 3 - CREACIÓN DEL CONTROLADOReduardoPas encore d'évaluation
- Economía Colonial en VenezuelaDocument4 pagesEconomía Colonial en VenezuelaRafaeduard Luque0% (1)
- Vect. y Ser.Document13 pagesVect. y Ser.Jessica Pereira33% (3)
- Resumen 1g Comunicaciones MovilesDocument2 pagesResumen 1g Comunicaciones MovilesRider Juan Dela Cruz CoaquiraPas encore d'évaluation
- Cooperativa Fernando DaquilemaDocument3 pagesCooperativa Fernando Daquilemaandrea vizuetaPas encore d'évaluation
- Instructivo de Memoria Tecnica de Pasantias o Practicas Pre-ProfesionalesDocument10 pagesInstructivo de Memoria Tecnica de Pasantias o Practicas Pre-ProfesionalesAlfredo TenelemaPas encore d'évaluation
- Manual de Archivo de Gestión de La Ugda PDFDocument26 pagesManual de Archivo de Gestión de La Ugda PDFLUCASPas encore d'évaluation
- Auditoria Energetica 11Document9 pagesAuditoria Energetica 11LanyxEmirYTPas encore d'évaluation
- Concentrum, Plus y Orbit - Equipamiento Modular para GinecologíaDocument72 pagesConcentrum, Plus y Orbit - Equipamiento Modular para GinecologíaSamantha LópezPas encore d'évaluation
- Tres Componentes de GobernabilidadDocument2 pagesTres Componentes de Gobernabilidadedwar salgadoPas encore d'évaluation
- Inr - TDR Elaboracion Del Expediente TecnicoDocument55 pagesInr - TDR Elaboracion Del Expediente TecnicoElton Chumbimuni Tenicela100% (1)