Vous aimerez peut-être aussi
- Autism SpeechLanguageDocument24 pagesAutism SpeechLanguageampiccaPas encore d'évaluation
- Giesecke, Kay - Co-Articulation - Essential To Therapy For CAS and Helpful To Phonology TherapyDocument4 pagesGiesecke, Kay - Co-Articulation - Essential To Therapy For CAS and Helpful To Phonology TherapyampiccaPas encore d'évaluation
- Giesecke, Kay - 3-D Apraxic Therapy For KidsDocument6 pagesGiesecke, Kay - 3-D Apraxic Therapy For KidsampiccaPas encore d'évaluation
- Science7 - q1 - Mod1 - Scientific Ways of Acquiring Knowledge and Solving Problesm - FINAL08032020Document25 pagesScience7 - q1 - Mod1 - Scientific Ways of Acquiring Knowledge and Solving Problesm - FINAL08032020ruff81% (69)
- Form 4 Science Chapter 1 NotesDocument2 pagesForm 4 Science Chapter 1 NotesCheah Foo Kit58% (12)
- Decoding Speech Prosody in Five LanguagesDocument18 pagesDecoding Speech Prosody in Five LanguagesmarkosPas encore d'évaluation
- Articulation, Acoustics and Perception of Mandarin Chinese Emotional SpeechDocument16 pagesArticulation, Acoustics and Perception of Mandarin Chinese Emotional SpeechJulsPas encore d'évaluation
- A Catalogue of 1,759 Basic Emotions TermsDocument27 pagesA Catalogue of 1,759 Basic Emotions TermsZivagoPas encore d'évaluation
- Human Non-Linguistic Vocal Repertoire: Call Types and Their MeaningDocument28 pagesHuman Non-Linguistic Vocal Repertoire: Call Types and Their MeaningMorlaPas encore d'évaluation
- The Strange Stories Test: A Replication With High-Functioning Adults With Autism or Asperger SyndromeDocument33 pagesThe Strange Stories Test: A Replication With High-Functioning Adults With Autism or Asperger Syndromeflower21Pas encore d'évaluation
- Engl 1302 Essay 1 Draft 2Document5 pagesEngl 1302 Essay 1 Draft 2api-609763320Pas encore d'évaluation
- Is The Perception of Dysphonia Severity Language-Dependent A Comparison of French and Italian Voice Assessments GHIO 2015Document9 pagesIs The Perception of Dysphonia Severity Language-Dependent A Comparison of French and Italian Voice Assessments GHIO 2015Aude JihelPas encore d'évaluation
- Age Differences in The PronunciationDocument9 pagesAge Differences in The PronunciationMarie MardaleishviliPas encore d'évaluation
- + 2002 ART - Boal-Palheiros - Hargreaves-BCMREDocument7 pages+ 2002 ART - Boal-Palheiros - Hargreaves-BCMREBirgita Solange SantosPas encore d'évaluation
- Paper0001 0001 0028Document5 pagesPaper0001 0001 0028qwer963Pas encore d'évaluation
- Second LanguageDocument14 pagesSecond LanguageMariangelaPas encore d'évaluation
- Eimas1975 Article AuditoryAndPhoneticCodingOfTheDocument7 pagesEimas1975 Article AuditoryAndPhoneticCodingOfThePev27Pas encore d'évaluation
- 005 The Effects of Music On Language AcquisitionDocument11 pages005 The Effects of Music On Language AcquisitionNabilah Mohd NorPas encore d'évaluation
- Acoustic and Perceptual Measurement of Expressive Prosody in Hig-Functioning ASD. Increased Pitch RangeDocument13 pagesAcoustic and Perceptual Measurement of Expressive Prosody in Hig-Functioning ASD. Increased Pitch RangeTomas Torres BarberoPas encore d'évaluation
- Prosody AnalysisDocument8 pagesProsody AnalysisupanddownfilePas encore d'évaluation
- REFERENCIARSE EN ESTE TRABAJAO PARA PITCH 14 - Nadig - Shaw2012 - JADD - AAMDocument41 pagesREFERENCIARSE EN ESTE TRABAJAO PARA PITCH 14 - Nadig - Shaw2012 - JADD - AAMTomas Torres BarberoPas encore d'évaluation
- Research Plan EMOTIONAL RESPONSES TO MUSICDocument5 pagesResearch Plan EMOTIONAL RESPONSES TO MUSICVishal SeksariaPas encore d'évaluation
- Lim - TEADocument25 pagesLim - TEAMarce MazzucchelliPas encore d'évaluation
- The Arts Psychotherapy. A Music Therapy Clinical Case Study of A Girl With Childhood Apraxia of Speech... (Beathard Et Al.)Document10 pagesThe Arts Psychotherapy. A Music Therapy Clinical Case Study of A Girl With Childhood Apraxia of Speech... (Beathard Et Al.)Guillermo PortilloPas encore d'évaluation
- Speech and LanguagueDocument6 pagesSpeech and LanguagueBeckinha CardosoPas encore d'évaluation
- 1 s2.0 S0010945274800249 MainDocument14 pages1 s2.0 S0010945274800249 MainDushyant SoniPas encore d'évaluation
- An Experiment in Judging Intelligence by The VoiceDocument8 pagesAn Experiment in Judging Intelligence by The VoiceMonta TupčijenkoPas encore d'évaluation
- 2016JPSPLaukkaetalLensModelAcrossFiveCultures R2 FINALDocument61 pages2016JPSPLaukkaetalLensModelAcrossFiveCultures R2 FINALBlack ToasterPas encore d'évaluation
- Unige 102028 Attachment01Document15 pagesUnige 102028 Attachment01supiboboPas encore d'évaluation
- The Effect of Music On Second Language Vocabulary AcquisitionDocument8 pagesThe Effect of Music On Second Language Vocabulary AcquisitionForefront PublishersPas encore d'évaluation
- Lima2013 Article WhenVoicesGetEmotionalACorpusODocument12 pagesLima2013 Article WhenVoicesGetEmotionalACorpusObordian georgePas encore d'évaluation
- Cimpanezi Si Exprimare EmotiiDocument11 pagesCimpanezi Si Exprimare Emotiimyhaela_marculescuPas encore d'évaluation
- Cross 7&8Document9 pagesCross 7&8mekit bekelePas encore d'évaluation
- The Figurative and Literal Senses o F Idioms, or All Idioms Are Not Used EquallyDocument13 pagesThe Figurative and Literal Senses o F Idioms, or All Idioms Are Not Used EquallyNatalia MoskvinaPas encore d'évaluation
- Updated The Effects of Music On StudyingDocument6 pagesUpdated The Effects of Music On Studyingapi-609763320Pas encore d'évaluation
- #Moon (1993) Two-Day-Olds Prefer Their Native LanguageDocument6 pages#Moon (1993) Two-Day-Olds Prefer Their Native LanguageGaby BazánPas encore d'évaluation
- Cross-Linguistic Aspects of Literacy Development and DyslexiaDocument24 pagesCross-Linguistic Aspects of Literacy Development and DyslexiaFrancisco Jesús Martínez MurciaPas encore d'évaluation
- Phillips Borodistky 2003 Replication Spring 2022Document19 pagesPhillips Borodistky 2003 Replication Spring 2022httPas encore d'évaluation
- 2007 Hunter-Smith Sarah PDFDocument58 pages2007 Hunter-Smith Sarah PDFRand AlashqerPas encore d'évaluation
- Cross-Cultural Perspectives On Pitch Memory: Sandra E. Trehub, E. Glenn Schellenberg, Takayuki NakataDocument13 pagesCross-Cultural Perspectives On Pitch Memory: Sandra E. Trehub, E. Glenn Schellenberg, Takayuki NakataKhristianKraouliPas encore d'évaluation
- AngerDocument20 pagesAngerLaurentiu IonPas encore d'évaluation
- Disfluence in KannadaDocument124 pagesDisfluence in KannadaSai KumarPas encore d'évaluation
- tmp17B TMPDocument8 pagestmp17B TMPFrontiersPas encore d'évaluation
- Werker1984 PDFDocument15 pagesWerker1984 PDFEnzo AlarconPas encore d'évaluation
- The Spanish Adaptation of ANEW (Affective Norms For English Words)Document6 pagesThe Spanish Adaptation of ANEW (Affective Norms For English Words)catalina_serbanPas encore d'évaluation
- Music Therapy in The EcholaliaDocument14 pagesMusic Therapy in The EcholaliaKPas encore d'évaluation
- Age-Related Changes in The Anatomy of Language Regions in Autism Spectrum DisorderDocument13 pagesAge-Related Changes in The Anatomy of Language Regions in Autism Spectrum DisorderSimona MariaPas encore d'évaluation
- Facial RecognitionDocument14 pagesFacial RecognitionGeorge BaciuPas encore d'évaluation
- 1986 - Wallbott - JPSP Cues and Channels in Emotion RecognitionDocument10 pages1986 - Wallbott - JPSP Cues and Channels in Emotion RecognitionGeorge BaciuPas encore d'évaluation
- Markó Alexandra-A Diszfónia Terápiájának Hatékonysága A Beteg Beszédtechnikai Képzettségének FüggvényébenDocument21 pagesMarkó Alexandra-A Diszfónia Terápiájának Hatékonysága A Beteg Beszédtechnikai Képzettségének FüggvényébenCecília BarthaPas encore d'évaluation
- Dev 20229Document5 pagesDev 20229Dillei CaraPas encore d'évaluation
- Lorette Dewaele 2018Document24 pagesLorette Dewaele 2018Cla RiiTaPas encore d'évaluation
- Electro LarynxDocument14 pagesElectro LarynxvivekPas encore d'évaluation
- Research Plan: Investigating The Role of X in ( ) Among UniversityDocument3 pagesResearch Plan: Investigating The Role of X in ( ) Among UniversityVishal SeksariaPas encore d'évaluation
- Commentary On Why Does Music Therapy Hel PDFDocument5 pagesCommentary On Why Does Music Therapy Hel PDFMatt SuiPas encore d'évaluation
- Prosody in Autism Spectrum Disorders: A Critical Review: Joanne Mccann and Sue PeppeDocument26 pagesProsody in Autism Spectrum Disorders: A Critical Review: Joanne Mccann and Sue PeppedistanceprepPas encore d'évaluation
- Rhymes and Brain ActivitiesDocument11 pagesRhymes and Brain ActivitiesSyugo HottaPas encore d'évaluation
- Articulo Disartria y Paralisis CerebralDocument6 pagesArticulo Disartria y Paralisis CerebralHaizea MuñozPas encore d'évaluation
- Lalain Nguyen HabibDocument4 pagesLalain Nguyen HabibMichel HabibPas encore d'évaluation
- A Cross-Linguistic Comparison of Generic Noun Phrases in English and MandarinDocument34 pagesA Cross-Linguistic Comparison of Generic Noun Phrases in English and MandarinIker SalaberriPas encore d'évaluation
- Language and Understanding Minds Connections in AutismDocument46 pagesLanguage and Understanding Minds Connections in AutismRaisa CoppolaPas encore d'évaluation
- Doupe, A. J., & Kuhl, P. K. (1999) - Birdsong and Human Speech - Common Themes and Mechanisms. Annual Review of Neuroscience, 22 (1), 567-631.Document66 pagesDoupe, A. J., & Kuhl, P. K. (1999) - Birdsong and Human Speech - Common Themes and Mechanisms. Annual Review of Neuroscience, 22 (1), 567-631.goni56509Pas encore d'évaluation
- 1996 Word Association Emotional IndicatorsDocument10 pages1996 Word Association Emotional IndicatorsGuillermo E Arias MPas encore d'évaluation
- Coversheet For Submission of Coursework (Undergraduate & Taught Postgraduate)Document7 pagesCoversheet For Submission of Coursework (Undergraduate & Taught Postgraduate)Liz IslesPas encore d'évaluation
- Academic VocabularyDocument2 pagesAcademic VocabularyampiccaPas encore d'évaluation
- Speech InventoryDocument3 pagesSpeech InventoryampiccaPas encore d'évaluation
- What Should - Abstract ConceptsDocument20 pagesWhat Should - Abstract Conceptsampicca100% (1)
- TSHA - Texas Eligibility GuidelinesDocument40 pagesTSHA - Texas Eligibility GuidelinesampiccaPas encore d'évaluation
- Law and Research in Regards To Students Who Are English Language LearnersDocument91 pagesLaw and Research in Regards To Students Who Are English Language LearnersampiccaPas encore d'évaluation
- 5781 Brother BC2100 Sewing Machine Manual in EnglishDocument68 pages5781 Brother BC2100 Sewing Machine Manual in EnglishCornelia IonitaPas encore d'évaluation
- Chapter 6-Phonation II - PrintVersionDocument8 pagesChapter 6-Phonation II - PrintVersionampiccaPas encore d'évaluation
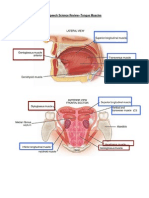
- Speech Science Review - Tongue MusclesDocument5 pagesSpeech Science Review - Tongue MusclesampiccaPas encore d'évaluation
- Chapters 1, 2, 12Document4 pagesChapters 1, 2, 12ampiccaPas encore d'évaluation
- Monogrammed Ipad Charger Wraps Signed1Document2 pagesMonogrammed Ipad Charger Wraps Signed1ampiccaPas encore d'évaluation
- Sonnemann Camerer Fox Langer 2013 - Behavioral FinanceDocument6 pagesSonnemann Camerer Fox Langer 2013 - Behavioral FinancevallePas encore d'évaluation
- Improving Speaking Ability For Grade XIDocument202 pagesImproving Speaking Ability For Grade XIArfan Agus SaputraPas encore d'évaluation
- 1.1 Strategy of ExperimentationDocument4 pages1.1 Strategy of Experimentationdann hernandezPas encore d'évaluation
- 10 Assess ValidationDocument9 pages10 Assess ValidationchemtabPas encore d'évaluation
- Lab-Thermal Energy Transfer-Student GuideDocument8 pagesLab-Thermal Energy Transfer-Student GuideCyrusquinonesPas encore d'évaluation
- Unit V Reporting To Management Objectives of The StudyDocument32 pagesUnit V Reporting To Management Objectives of The StudyShinchana KPas encore d'évaluation
- Taste Test Lab InstructionsDocument12 pagesTaste Test Lab Instructionsapi-282787386Pas encore d'évaluation
- Science 2 ANBU & 2 ARAM 13.10.2022Document3 pagesScience 2 ANBU & 2 ARAM 13.10.2022Shamala SilvakumarPas encore d'évaluation
- Research Topic 2Document9 pagesResearch Topic 2JE RI COPas encore d'évaluation
- DACs GROUPDANIEL ALFANTE CAGUICLA With AbstractDocument8 pagesDACs GROUPDANIEL ALFANTE CAGUICLA With AbstractJacob LawrencePas encore d'évaluation
- ExperimentDocument3 pagesExperimentChong Chee SianPas encore d'évaluation
- PGCDR18Document68 pagesPGCDR18Santosh PaplePas encore d'évaluation
- Chapter 2 Statistical Data and SamplingDocument8 pagesChapter 2 Statistical Data and SamplingKent Ivan Delpaz CamposPas encore d'évaluation
- Lady Lara Sati - 15101156110032 PDFDocument230 pagesLady Lara Sati - 15101156110032 PDFm lutfi apuriPas encore d'évaluation
- Principle of TeachingDocument43 pagesPrinciple of TeachingBoyet Aluan100% (1)
- EP09A2IRDocument78 pagesEP09A2IRHassab Saeed100% (1)
- GENERAL-EDUCATION 1st BatchDocument7 pagesGENERAL-EDUCATION 1st BatchDarrell CabudolPas encore d'évaluation
- Cognitive Therapy Scale Rating ManualDocument24 pagesCognitive Therapy Scale Rating ManualumibrahimPas encore d'évaluation
- Introduction To Modern Biology: Learning OutcomesDocument28 pagesIntroduction To Modern Biology: Learning OutcomesDanielle GuerraPas encore d'évaluation
- HaruyamaDocument10 pagesHaruyamabarros6Pas encore d'évaluation
- School Trip EssayDocument3 pagesSchool Trip Essayafhevpkzk100% (2)
- Eva Yang - Capstone ProjectDocument32 pagesEva Yang - Capstone ProjectHI :DPas encore d'évaluation
- Aserinsky and KleitmanDocument2 pagesAserinsky and KleitmanEmily MartinPas encore d'évaluation
- Module 10 - Strategy2 - ExperimentationDocument11 pagesModule 10 - Strategy2 - ExperimentationMaui Francine EnormePas encore d'évaluation
- Chapter-2 Review of Related LiteratureDocument14 pagesChapter-2 Review of Related LiteratureQueeny Fe Aberilla TinayPas encore d'évaluation
- PHYS AM 04 Newtons Second LawDocument12 pagesPHYS AM 04 Newtons Second LawSvetlana ChichikalovaPas encore d'évaluation
- The Experimentation Field Book A Step by Step Project Guide Jeanne Liedtka Full ChapterDocument67 pagesThe Experimentation Field Book A Step by Step Project Guide Jeanne Liedtka Full Chaptergerardo.munoz362100% (4)
- Mastering Statistical Quality Control With MinitabDocument7 pagesMastering Statistical Quality Control With MinitabBrian PrestonPas encore d'évaluation