Vous aimerez peut-être aussi
- Image To Text Conversion, Character RecognitionDocument3 pagesImage To Text Conversion, Character RecognitionNAJIB GHATTEPas encore d'évaluation
- Kannada Character Recognition System A Review: January 2010Document13 pagesKannada Character Recognition System A Review: January 2010SHAHBAZ M MAINUDDINPas encore d'évaluation
- A Structural Approach For Segmentation of Handwritten Hindi TextDocument9 pagesA Structural Approach For Segmentation of Handwritten Hindi TextBharat BaghelPas encore d'évaluation
- Recognition of English Characters by Codes Generated Using Neighbour IdentificationDocument5 pagesRecognition of English Characters by Codes Generated Using Neighbour IdentificationInternational Journal of Application or Innovation in Engineering & ManagementPas encore d'évaluation
- Recognition of On-Line Arabic Handwritten Characters Using Structural FeaturesDocument15 pagesRecognition of On-Line Arabic Handwritten Characters Using Structural FeaturesDiaa MustafaPas encore d'évaluation
- Detection of Bold and Italic Character in Gurmukhi Script: Harjit SinghDocument4 pagesDetection of Bold and Italic Character in Gurmukhi Script: Harjit SinghInternational Organization of Scientific Research (IOSR)Pas encore d'évaluation
- Hindi OCRDocument12 pagesHindi OCRAndrea GriffinPas encore d'évaluation
- Detection of Bold Italic and Underline Fonts For Hindi OCRDocument4 pagesDetection of Bold Italic and Underline Fonts For Hindi OCRseventhsensegroupPas encore d'évaluation
- Ijcet: International Journal of Computer Engineering & Technology (Ijcet)Document11 pagesIjcet: International Journal of Computer Engineering & Technology (Ijcet)IAEME PublicationPas encore d'évaluation
- An Approach On Recognition of Hand-Written Letters: Ahmet ÇINAR, Erdal ÖZBAYDocument7 pagesAn Approach On Recognition of Hand-Written Letters: Ahmet ÇINAR, Erdal ÖZBAYUbiquitous Computing and Communication JournalPas encore d'évaluation
- Rec Pa MiDocument14 pagesRec Pa MiAnand MishraPas encore d'évaluation
- Quantifying Scripts: Defining Metrics of Characters For Quantitative and Descriptive AnalysisDocument21 pagesQuantifying Scripts: Defining Metrics of Characters For Quantitative and Descriptive AnalysisPhạm TuấnPas encore d'évaluation
- Final A Two Stage Character Segmentation TechniqueDocument31 pagesFinal A Two Stage Character Segmentation Techniquechandanaramadugu100% (1)
- Word & Character Segmentation For Bangla Handwriting Analysis & RecognitionDocument4 pagesWord & Character Segmentation For Bangla Handwriting Analysis & RecognitionChayan HalderPas encore d'évaluation
- The Graphology Applied To Signature VerificationDocument6 pagesThe Graphology Applied To Signature VerificationputeraadamPas encore d'évaluation
- Ejemplo de Estructura SolicitadaDocument6 pagesEjemplo de Estructura SolicitadaPIERO ALEXANDER MARINES VEGAPas encore d'évaluation
- Character Extraction Algorithm For Handwritten Character Recognition SystemsDocument8 pagesCharacter Extraction Algorithm For Handwritten Character Recognition SystemsRakeshconclavePas encore d'évaluation
- Development of An Automated Handwriting Analysis SystemDocument6 pagesDevelopment of An Automated Handwriting Analysis SystemRodrigoFaríasVelosoPas encore d'évaluation
- Handwritten Devanagari Word Recognition: A Curvelet Transform Based ApproachDocument8 pagesHandwritten Devanagari Word Recognition: A Curvelet Transform Based ApproachAratiKothariPas encore d'évaluation
- Text Line Segmentation and Word Recognition in A System For General Writer Independent Handwriting RecognitionDocument11 pagesText Line Segmentation and Word Recognition in A System For General Writer Independent Handwriting RecognitionPriya D MelloPas encore d'évaluation
- Graphology PDFDocument5 pagesGraphology PDFpuneeth87Pas encore d'évaluation
- Determine Characters by Mathematical Model For Segmentation Arabic WordsDocument7 pagesDetermine Characters by Mathematical Model For Segmentation Arabic Wordsjibrel.ambarkPas encore d'évaluation
- Detection and Segmentation of Touching Characters in Mathematical ExpressionsDocument5 pagesDetection and Segmentation of Touching Characters in Mathematical ExpressionsArpit MalhotraPas encore d'évaluation
- Segmentation of Handwritten Text in Gurmukhi Script: Rajiv K. SharmaDocument6 pagesSegmentation of Handwritten Text in Gurmukhi Script: Rajiv K. SharmaRay ZxPas encore d'évaluation
- Optical Character Segmentation and Recognition From A Rochester FlagDocument10 pagesOptical Character Segmentation and Recognition From A Rochester FlagDr MohammedPas encore d'évaluation
- Research Paper On Character RecognitionDocument8 pagesResearch Paper On Character RecognitionArijit PramanickPas encore d'évaluation
- Recognition of English Characters by Codes Generated Using Neighbour IdentificationDocument7 pagesRecognition of English Characters by Codes Generated Using Neighbour IdentificationEn VyPas encore d'évaluation
- A Novel Approach For Structural Feature Extraction: Contour vs. DirectionDocument15 pagesA Novel Approach For Structural Feature Extraction: Contour vs. DirectionRachit GoelPas encore d'évaluation
- Text Pre-Processing and Text Segmentation For OCRDocument3 pagesText Pre-Processing and Text Segmentation For OCRAkai ShuichiPas encore d'évaluation
- Implementation of A Statistical Based Arabic Character Recognition SystemDocument4 pagesImplementation of A Statistical Based Arabic Character Recognition Systemapi-3754855Pas encore d'évaluation
- Zone Segmentation and Thinning Based Algorithm For Segmentation of Devnagari TextDocument4 pagesZone Segmentation and Thinning Based Algorithm For Segmentation of Devnagari TextEditor IJRITCCPas encore d'évaluation
- A Novel InvariantDocument12 pagesA Novel InvariantKing Abdul HarizPas encore d'évaluation
- Importance of Engineering GraphicsDocument52 pagesImportance of Engineering GraphicsSathishPas encore d'évaluation
- Character Complexity and Redundancy in Writing Systems Over Human HistoryDocument9 pagesCharacter Complexity and Redundancy in Writing Systems Over Human HistoryTom SlistsPas encore d'évaluation
- Telugu Script Achanta Hastie 2015.2805047Document32 pagesTelugu Script Achanta Hastie 2015.2805047JheanPas encore d'évaluation
- Overview of Tesseract OCR EngineDocument5 pagesOverview of Tesseract OCR Enginerrs_1988Pas encore d'évaluation
- January 5, 2007 21:8 WSPC/115-IJPRAI SPI-J068 00534Document21 pagesJanuary 5, 2007 21:8 WSPC/115-IJPRAI SPI-J068 00534PradeepPas encore d'évaluation
- A System For Reading USA Census Hand-Written FieldsDocument6 pagesA System For Reading USA Census Hand-Written FieldsMrinaljit BorahPas encore d'évaluation
- Line Segmentation of Handwritten Documents Written in Gurumukhi ScriptDocument4 pagesLine Segmentation of Handwritten Documents Written in Gurumukhi ScriptInternational Journal of Application or Innovation in Engineering & ManagementPas encore d'évaluation
- Arabic Character Segmenta Ation Using Projection-Based Approach Amplitude Filter H With Profile'sDocument5 pagesArabic Character Segmenta Ation Using Projection-Based Approach Amplitude Filter H With Profile'sSharon KellerPas encore d'évaluation
- Solange Trujillo Design & TypographyDocument9 pagesSolange Trujillo Design & TypographysolangetrujilloPas encore d'évaluation
- An Approach To Offline Handwritten Chinese Character Recognition Based On Segment Evaluation of Adaptive DurationDocument6 pagesAn Approach To Offline Handwritten Chinese Character Recognition Based On Segment Evaluation of Adaptive Durationapi-3806049Pas encore d'évaluation
- Development of An Automated Handwriting Analysis SystemDocument9 pagesDevelopment of An Automated Handwriting Analysis SystemInstituto de Ciencias del Grafismo GrafosPas encore d'évaluation
- Thresholding, Noise Reduction and Skew Correction of Sinhala Handwritten W OrdsDocument4 pagesThresholding, Noise Reduction and Skew Correction of Sinhala Handwritten W OrdsKosala HandapangodaPas encore d'évaluation
- A Multiset Approach For Recognition of Handwritten Characters Using Puzzle PiecesDocument9 pagesA Multiset Approach For Recognition of Handwritten Characters Using Puzzle PiecesCS & ITPas encore d'évaluation
- The Anatomy of TypeDocument11 pagesThe Anatomy of TypeCenza Della DonnaPas encore d'évaluation
- Basic Character Spacing in Type DesignDocument5 pagesBasic Character Spacing in Type Designcorina_pePas encore d'évaluation
- Tesseract I CD Ar 2007Document5 pagesTesseract I CD Ar 2007Nick HuPas encore d'évaluation
- 17 97 102 PDFDocument6 pages17 97 102 PDFlambanaveenPas encore d'évaluation
- Modified Syntactic Method To Recognize Bengali Handwritten CharactersDocument11 pagesModified Syntactic Method To Recognize Bengali Handwritten CharactersMohammad Nazrul IslamPas encore d'évaluation
- Free-Scale Magnification For Single-Pixel-Width Alphabetic Typeface CharactersDocument7 pagesFree-Scale Magnification For Single-Pixel-Width Alphabetic Typeface CharactersinventionjournalsPas encore d'évaluation
- HA and PaperDocument5 pagesHA and PaperPradeep Uday K UPas encore d'évaluation
- Transfer Learning in Sign LanguageDocument8 pagesTransfer Learning in Sign LanguageRam NicePas encore d'évaluation
- EdrawDocument3 pagesEdrawAedrian M LopezPas encore d'évaluation
- Arabic Handwriting Recognition ThesisDocument7 pagesArabic Handwriting Recognition ThesisMaria Perkins100% (2)
- Image Histogram: Unveiling Visual Insights, Exploring the Depths of Image Histograms in Computer VisionD'EverandImage Histogram: Unveiling Visual Insights, Exploring the Depths of Image Histograms in Computer VisionPas encore d'évaluation
- Scale Invariant Feature Transform: Unveiling the Power of Scale Invariant Feature Transform in Computer VisionD'EverandScale Invariant Feature Transform: Unveiling the Power of Scale Invariant Feature Transform in Computer VisionPas encore d'évaluation
- String Algorithms in C: Efficient Text Representation and SearchD'EverandString Algorithms in C: Efficient Text Representation and SearchPas encore d'évaluation
- ST Learning Task 10Document6 pagesST Learning Task 10Jermaine DoloritoPas encore d'évaluation
- Several Terms Redirect Here. For Other Uses, See,, and - This Article Is About Jinn in Islam. For Other Uses, See andDocument2 pagesSeveral Terms Redirect Here. For Other Uses, See,, and - This Article Is About Jinn in Islam. For Other Uses, See andEduard Loberez ReyesPas encore d'évaluation
- Sacred Books of The East Series, Volume 47: Pahlavi Texts, Part FiveDocument334 pagesSacred Books of The East Series, Volume 47: Pahlavi Texts, Part FiveJimmy T.100% (1)
- PM Plan Template For PresentationDocument3 pagesPM Plan Template For Presentationjamal123456Pas encore d'évaluation
- Performance AnalyticsDocument193 pagesPerformance AnalyticsGPas encore d'évaluation
- LESSON 1 Overview of Toeic Speaking WritingDocument29 pagesLESSON 1 Overview of Toeic Speaking WritingPhạm Thị HuyềnPas encore d'évaluation
- Chapter 11Document25 pagesChapter 11Marjorie PuzoPas encore d'évaluation
- Camisole No.8 Pattern by MyFavoriteThingsKnitwearDocument7 pagesCamisole No.8 Pattern by MyFavoriteThingsKnitwearGarlicPas encore d'évaluation
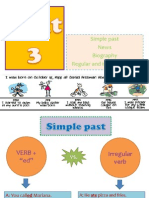
- Simple Past News Biography Regular and Irregular VerbsDocument15 pagesSimple Past News Biography Regular and Irregular VerbsDaniela MontemayorPas encore d'évaluation
- Quezon City University 673 Quirino Highway, San Bartolome, Novaliches Quezon City College of Engineering Industrial Engineering DepartmentDocument10 pagesQuezon City University 673 Quirino Highway, San Bartolome, Novaliches Quezon City College of Engineering Industrial Engineering DepartmentKavin Dela CruzPas encore d'évaluation
- Kutuzov A Life in War and Peace Alexander Mikaberidze 2 Full ChapterDocument67 pagesKutuzov A Life in War and Peace Alexander Mikaberidze 2 Full Chapterjanice.brooks978100% (6)
- R15 Aerodynamics Notes PDFDocument61 pagesR15 Aerodynamics Notes PDFRahil MpPas encore d'évaluation
- Role of Communication in BusinessDocument3 pagesRole of Communication in Businessmadhu motkur100% (2)
- Introduction To Qualitative ResearchDocument19 pagesIntroduction To Qualitative ResearchAnonymous LToOBqDPas encore d'évaluation
- Gripped by The Mystery: Franziska Carolina Rehbein SspsDocument70 pagesGripped by The Mystery: Franziska Carolina Rehbein SspsdonteldontelPas encore d'évaluation
- The Impact of Digitalization On Business ModelsDocument20 pagesThe Impact of Digitalization On Business ModelsFaheemullah HaddadPas encore d'évaluation
- LifeSkills - Role PlayDocument7 pagesLifeSkills - Role Playankit boxerPas encore d'évaluation
- 08 03 Runge-Kutta 2nd Order MethodDocument11 pages08 03 Runge-Kutta 2nd Order MethodJohn Bofarull GuixPas encore d'évaluation
- SVFC BS Accountancy - 2nd Set Online Resources SY20-19 2nd Semester PDFDocument14 pagesSVFC BS Accountancy - 2nd Set Online Resources SY20-19 2nd Semester PDFLorraine TomasPas encore d'évaluation
- 5 Methods: Mark Bevir Jason BlakelyDocument21 pages5 Methods: Mark Bevir Jason BlakelyGiulio PalmaPas encore d'évaluation
- Hunt v. United States, 4th Cir. (2004)Document7 pagesHunt v. United States, 4th Cir. (2004)Scribd Government DocsPas encore d'évaluation
- How Is The Frog's Stomach Adapted To Provide An Increased Digestive Surface?Document6 pagesHow Is The Frog's Stomach Adapted To Provide An Increased Digestive Surface?Jemuel Bucud LagartoPas encore d'évaluation
- Morality and Pedophilia in LolitaDocument5 pagesMorality and Pedophilia in LolitaDiana Alexa0% (1)
- Brand Relevance - 1Document2 pagesBrand Relevance - 1Ayan PandaPas encore d'évaluation
- Consent For MTP PDFDocument4 pagesConsent For MTP PDFMajid SheikhPas encore d'évaluation
- Opening Evolution by Bill WallDocument11 pagesOpening Evolution by Bill WallKartik ShroffPas encore d'évaluation
- RB September 2014 The One Thing Kekuatan Fokus Untuk Mendorong ProduktivitasDocument2 pagesRB September 2014 The One Thing Kekuatan Fokus Untuk Mendorong ProduktivitasRifat TaopikPas encore d'évaluation
- The Spiritist Review - Journal of Psychological Studies - 1864 - January - Healing MediumsDocument5 pagesThe Spiritist Review - Journal of Psychological Studies - 1864 - January - Healing MediumsWayne BritoPas encore d'évaluation
- Ejercicios de Relative ClausesDocument1 pageEjercicios de Relative ClausesRossyPas encore d'évaluation
- Lesson Plan - Special Right Triangles ReteachDocument1 pageLesson Plan - Special Right Triangles Reteachapi-448318028Pas encore d'évaluation