Vous aimerez peut-être aussi
- Mixture Models and ApplicationsD'EverandMixture Models and ApplicationsNizar BouguilaPas encore d'évaluation
- Cluster and Stratified Sampling: 1. The Linear Model With Cluster EffectsDocument31 pagesCluster and Stratified Sampling: 1. The Linear Model With Cluster Effectsnono85Pas encore d'évaluation
- Maximum Likelihood Estimation of Limited and Discrete Dependent Variable Models With Nested Random EffectsDocument23 pagesMaximum Likelihood Estimation of Limited and Discrete Dependent Variable Models With Nested Random EffectsJaime NavarroPas encore d'évaluation
- Wooldridge Slides 10 Diff in DiffsDocument31 pagesWooldridge Slides 10 Diff in DiffsAsrafuzzaman RobinPas encore d'évaluation
- 545 ProjectDocument10 pages545 ProjectYifu WuPas encore d'évaluation
- Algorithm 2Document27 pagesAlgorithm 2lalaxlalaPas encore d'évaluation
- Within-And Between-Cluster Effects in Generalized Linear Mixed Models: A Discussion of Approaches and The Xthybrid CommandDocument27 pagesWithin-And Between-Cluster Effects in Generalized Linear Mixed Models: A Discussion of Approaches and The Xthybrid CommandChakale1Pas encore d'évaluation
- Grou Diff ModerationDocument15 pagesGrou Diff ModerationCristian RamosPas encore d'évaluation
- Generalized Models For High-Throughput Analysis of Uncertain Nonlinear SystemsDocument4 pagesGeneralized Models For High-Throughput Analysis of Uncertain Nonlinear SystemsTunggul SagalaPas encore d'évaluation
- Joint Estimation and Inference For Data Integration Problems Based On Multiple Multi-Layered Gaussian Graphical ModelsDocument53 pagesJoint Estimation and Inference For Data Integration Problems Based On Multiple Multi-Layered Gaussian Graphical Modelsantonio peixotoPas encore d'évaluation
- Tugas BiostatDocument24 pagesTugas BiostatOla MjnPas encore d'évaluation
- Robust RegressionDocument7 pagesRobust Regressionharrison9Pas encore d'évaluation
- GMM in R - Jan2021Document19 pagesGMM in R - Jan2021BluedenWavePas encore d'évaluation
- Wald Tests When Restrictions Are Locally SingularDocument48 pagesWald Tests When Restrictions Are Locally SingularMasudul ICPas encore d'évaluation
- Structural Equation ModelingDocument14 pagesStructural Equation ModelingFerra YanuarPas encore d'évaluation
- American Statistical AssociationDocument5 pagesAmerican Statistical AssociationshahriarsadighiPas encore d'évaluation
- Geographically Weighted Regression Modelling Spatial NonstationarityDocument14 pagesGeographically Weighted Regression Modelling Spatial NonstationarityDanang AriyantoPas encore d'évaluation
- Dickens 1990Document7 pagesDickens 1990Dũng VũPas encore d'évaluation
- Schamberger2020 Article RobustPartialLeastSquaresPathMDocument28 pagesSchamberger2020 Article RobustPartialLeastSquaresPathMManoraj NatarajanPas encore d'évaluation
- Moment-Based Estimation of Nonlinear Regression Models Under Unobserved Heterogeneity, With Applications To Non-Negative and Fractional ResponsesDocument29 pagesMoment-Based Estimation of Nonlinear Regression Models Under Unobserved Heterogeneity, With Applications To Non-Negative and Fractional ResponsesVigneshRamakrishnanPas encore d'évaluation
- The VGAM Package For Categorical Data Analysis: Thomas W. YeeDocument30 pagesThe VGAM Package For Categorical Data Analysis: Thomas W. YeeGilberto Martinez BuitragoPas encore d'évaluation
- Mediation With Structural Equations Modeling: The Measurement ModelDocument15 pagesMediation With Structural Equations Modeling: The Measurement ModelruddenPas encore d'évaluation
- Balazsi-Matyas: The Estimation of Multi-Dimensional FixedEffects Panel Data ModelsDocument38 pagesBalazsi-Matyas: The Estimation of Multi-Dimensional FixedEffects Panel Data Modelsrapporter.netPas encore d'évaluation
- Domaining by Clustering Multivariate Geostatistical DataDocument12 pagesDomaining by Clustering Multivariate Geostatistical DataKasse VarillasPas encore d'évaluation
- Functional Models For Regression Tree Leaves: Luís TorgoDocument9 pagesFunctional Models For Regression Tree Leaves: Luís TorgoLoh Jia SinPas encore d'évaluation
- 19 Aos1924Document22 pages19 Aos1924sherlockholmes108Pas encore d'évaluation
- Modeling Idealized Bounding Cases of Parallel Genetic AlgorithmsDocument9 pagesModeling Idealized Bounding Cases of Parallel Genetic AlgorithmsMarco PulvirentiPas encore d'évaluation
- The Multivariate Social ScientistDocument14 pagesThe Multivariate Social ScientistTeuku RazyPas encore d'évaluation
- Applications of Generalized Method of Moments Estimation: Jeffrey M. WooldridgeDocument14 pagesApplications of Generalized Method of Moments Estimation: Jeffrey M. WooldridgeLuca SomigliPas encore d'évaluation
- Jep 15 4 87Document26 pagesJep 15 4 87Frann AraPas encore d'évaluation
- Can We Make Genetic Algorithms Work in High-Dimensionality Problems?Document17 pagesCan We Make Genetic Algorithms Work in High-Dimensionality Problems?kilo929756Pas encore d'évaluation
- Nested Generalized Linear Model With Ordinal Response For Correlated DataDocument11 pagesNested Generalized Linear Model With Ordinal Response For Correlated DataarifPas encore d'évaluation
- SCH Luc HterDocument21 pagesSCH Luc HterlindaPas encore d'évaluation
- The General Considerations and Implementation In: K-Means Clustering Technique: MathematicaDocument10 pagesThe General Considerations and Implementation In: K-Means Clustering Technique: MathematicaMario ZamoraPas encore d'évaluation
- Cluster Cat VarsDocument17 pagesCluster Cat Varsfab101Pas encore d'évaluation
- Generalized Ordered Logit/partial Proportional Odds Models For Ordinal Dependent VariablesDocument25 pagesGeneralized Ordered Logit/partial Proportional Odds Models For Ordinal Dependent VariablesCristopher Brandon Paucar TorrePas encore d'évaluation
- Does Model-Free Forecasting Really Outperform The True Model?Document5 pagesDoes Model-Free Forecasting Really Outperform The True Model?Peer TerPas encore d'évaluation
- Object Risk Position Paper Mixture Models in Operational RiskDocument5 pagesObject Risk Position Paper Mixture Models in Operational RiskAlexandre MarinhoPas encore d'évaluation
- Flex MG ArchDocument44 pagesFlex MG ArchsdfasdfkksfjPas encore d'évaluation
- FferDocument6 pagesFferlhzPas encore d'évaluation
- Ward Clustering AlgorithmDocument4 pagesWard Clustering AlgorithmBehrang Saeedzadeh100% (1)
- Utad 016Document36 pagesUtad 016cao xiuzhenPas encore d'évaluation
- Statistical Treatment of Data, Data Interpretation, and ReliabilityDocument6 pagesStatistical Treatment of Data, Data Interpretation, and Reliabilitydraindrop8606Pas encore d'évaluation
- Spatial Probit Model in RDocument14 pagesSpatial Probit Model in RMauricio OyarzoPas encore d'évaluation
- Introductory Overview - Basic IdeasDocument14 pagesIntroductory Overview - Basic Ideasrachit86kharePas encore d'évaluation
- 14 Aos1260Document31 pages14 Aos1260Swapnaneel BhattacharyyaPas encore d'évaluation
- General-to-Specific Reductions of Vector Autoregressive ProcessesDocument20 pagesGeneral-to-Specific Reductions of Vector Autoregressive ProcessesAhmed H ElsayedPas encore d'évaluation
- Generalized Linear Models: Simon Jackman Stanford UniversityDocument7 pagesGeneralized Linear Models: Simon Jackman Stanford UniversityababacarbaPas encore d'évaluation
- When Will Gradient Methods Converge To Max Margin Classifier Under Relu Models PDFDocument23 pagesWhen Will Gradient Methods Converge To Max Margin Classifier Under Relu Models PDFphilo guyPas encore d'évaluation
- McCulloch and Neuhaus 2005 Generalized Linear Mixed ModelsDocument5 pagesMcCulloch and Neuhaus 2005 Generalized Linear Mixed ModelsCarlos AndradePas encore d'évaluation
- Q.1 Explain The Underlying Ideas Behind The Log It Model. Explain On What Grounds Log It Model Is An Improvement Over Linear Probability Model. AnsDocument17 pagesQ.1 Explain The Underlying Ideas Behind The Log It Model. Explain On What Grounds Log It Model Is An Improvement Over Linear Probability Model. AnsBinyamin AlamPas encore d'évaluation
- When Should You Adjust Standard Errors For Clustering?Document29 pagesWhen Should You Adjust Standard Errors For Clustering?Hana C.Pas encore d'évaluation
- 1 C. Fraley and A. E. Raftery Technical Report No. 329 Department of Statistics University of Washington Box 354322 Seattle, WA 98195-4322 USA February 27, 1998Document18 pages1 C. Fraley and A. E. Raftery Technical Report No. 329 Department of Statistics University of Washington Box 354322 Seattle, WA 98195-4322 USA February 27, 1998giulio_giammuss9856Pas encore d'évaluation
- Statistical ModelDocument9 pagesStatistical ModelRae SecretariaPas encore d'évaluation
- Feasible Generalized Least Squares For Panel Data With Cross-Sectional and Serial CorrelationsDocument18 pagesFeasible Generalized Least Squares For Panel Data With Cross-Sectional and Serial CorrelationsAngel R ShereenPas encore d'évaluation
- Data200 W5Document11 pagesData200 W5ashutosh karkiPas encore d'évaluation
- Maximum GenerationDocument8 pagesMaximum GenerationDeepak WasgePas encore d'évaluation
- Cross-Sectional DependenceDocument5 pagesCross-Sectional DependenceIrfan UllahPas encore d'évaluation
- Ensemble LearningDocument24 pagesEnsemble LearningAbel DemelashPas encore d'évaluation
- Botakoz Kasumbekova European Resttlement in TJK 2011Document18 pagesBotakoz Kasumbekova European Resttlement in TJK 2011amudaryoPas encore d'évaluation
- Fritz Strengthening PFM 2014Document55 pagesFritz Strengthening PFM 2014amudaryoPas encore d'évaluation
- John Keats PoemsDocument5 pagesJohn Keats PoemsamudaryoPas encore d'évaluation
- Scholarforum Migrationcentral Asia and Mongolia 20160603Document24 pagesScholarforum Migrationcentral Asia and Mongolia 20160603amudaryoPas encore d'évaluation
- Brexit and UK 2017Document50 pagesBrexit and UK 2017amudaryoPas encore d'évaluation
- Kiingdom of CaubulDocument461 pagesKiingdom of CaubulamudaryoPas encore d'évaluation
- The World Bank Group - Tajikistan Partnership Program SnapshotDocument31 pagesThe World Bank Group - Tajikistan Partnership Program SnapshotamudaryoPas encore d'évaluation
- Do Balanced Budget Laws Matter in Recessions?: Friday, October 7Document1 pageDo Balanced Budget Laws Matter in Recessions?: Friday, October 7amudaryoPas encore d'évaluation
- Botakoz Kasumbekova Understanding Stalinism 2017Document19 pagesBotakoz Kasumbekova Understanding Stalinism 2017amudaryoPas encore d'évaluation
- ODI Budget Credibility 2014Document38 pagesODI Budget Credibility 2014amudaryoPas encore d'évaluation
- PHD Econ HandbookDocument8 pagesPHD Econ HandbookamudaryoPas encore d'évaluation
- Foreign AID FOR Tajikistan IN FiguresDocument2 pagesForeign AID FOR Tajikistan IN FiguresamudaryoPas encore d'évaluation
- So, What Did You Do Last Night? The Economics of Infidelity: KYKLOS, Vol. 61 - 2008 - No. 3, 391-410Document20 pagesSo, What Did You Do Last Night? The Economics of Infidelity: KYKLOS, Vol. 61 - 2008 - No. 3, 391-410amudaryoPas encore d'évaluation
- The Theory of Economic GrowthDocument409 pagesThe Theory of Economic Growthabdullah5502100% (5)
- Lewis Econ Dev't and Supply of LaborDocument30 pagesLewis Econ Dev't and Supply of LaboramudaryoPas encore d'évaluation
- Summer School in TJKDocument1 pageSummer School in TJKamudaryoPas encore d'évaluation
- Belev 2003Document44 pagesBelev 2003amudaryoPas encore d'évaluation
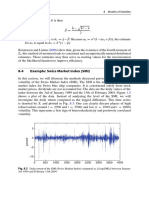
- 8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityDocument3 pages8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityNickesh ShahPas encore d'évaluation
- Cost Drydock PDFDocument10 pagesCost Drydock PDFJorge Lafontant100% (3)
- Corruption and Economic Development New Evidence From The Middle Eastern and North African CountriesDocument13 pagesCorruption and Economic Development New Evidence From The Middle Eastern and North African CountriesLobel T. TranPas encore d'évaluation
- Factor Influencing On Hanu Students' House Rent: Econometrics ProjectDocument23 pagesFactor Influencing On Hanu Students' House Rent: Econometrics ProjectNguyễn Gia Phương AnhPas encore d'évaluation
- Censoring Truncation SurveyDocument40 pagesCensoring Truncation SurveyTrianto Budi UtamaPas encore d'évaluation
- Anderson 1997 Decision Support SystemsDocument18 pagesAnderson 1997 Decision Support SystemsIim MucharamPas encore d'évaluation
- Multicollinearity AND HeteroskedasticityDocument75 pagesMulticollinearity AND HeteroskedasticitynhungPas encore d'évaluation
- Our Blog: Solving The Problem of Heteroscedasticity Through Weighted RegressionDocument21 pagesOur Blog: Solving The Problem of Heteroscedasticity Through Weighted RegressionZelalem TadelePas encore d'évaluation
- Hypothesis Testing in The Multiple RegressionDocument23 pagesHypothesis Testing in The Multiple RegressionShabbir WahabPas encore d'évaluation
- Analisis Perilaku Konsumen Pada Pembelian Daging BabiDocument15 pagesAnalisis Perilaku Konsumen Pada Pembelian Daging BabiMaikhel Abraham100% (1)
- 1911 en The Influence of Brand Image Brand Personality and Brand Awareness On Consumer PDocument9 pages1911 en The Influence of Brand Image Brand Personality and Brand Awareness On Consumer PFendy Ahmad ZaenullahPas encore d'évaluation
- Multiple Choice Test Bank Questions No Feedback - Chapter 5Document7 pagesMultiple Choice Test Bank Questions No Feedback - Chapter 5Đức NghĩaPas encore d'évaluation
- Post Graduate Diploma in Management: Narsee Monjee Institute of Management StudiesDocument4 pagesPost Graduate Diploma in Management: Narsee Monjee Institute of Management StudiesprachiPas encore d'évaluation
- Harvard EconDocument47 pagesHarvard Econscribewriter1990Pas encore d'évaluation
- Econometric Computing With HC An HACDocument21 pagesEconometric Computing With HC An HAClquerovPas encore d'évaluation
- SyllabusDocument2 pagesSyllabusJohn SmythePas encore d'évaluation
- ECON 141 Problem Set 4Document3 pagesECON 141 Problem Set 4dnlmsgnPas encore d'évaluation
- An Estimation of Technical Efficiency of Garlic Production in Khyber Pakhtunkhwa PakistanDocument10 pagesAn Estimation of Technical Efficiency of Garlic Production in Khyber Pakhtunkhwa Pakistanazni herasaPas encore d'évaluation
- Cambodia Hotel SatisfactionDocument18 pagesCambodia Hotel SatisfactionTrần Thành ĐạtPas encore d'évaluation
- HeteroscedasticityDocument12 pagesHeteroscedasticityarmailgmPas encore d'évaluation
- The Influence of Classroom Climate, Learning Interest, Learning Discipline and Learning Motivation To Learning Outcomes On Productive SubjectsDocument12 pagesThe Influence of Classroom Climate, Learning Interest, Learning Discipline and Learning Motivation To Learning Outcomes On Productive Subjectsakua galonPas encore d'évaluation
- V01-Analysis of VarianceDocument991 pagesV01-Analysis of Varianceasg_rus100% (1)
- The Effect of Leverage, Capital Intensity and Deferred TaxDocument8 pagesThe Effect of Leverage, Capital Intensity and Deferred TaxChristin AgapePas encore d'évaluation
- Advanced Forecasting Models Using Sas SoftwareDocument10 pagesAdvanced Forecasting Models Using Sas SoftwareSarbani DasguptsPas encore d'évaluation
- Solutions For Chapter 8Document23 pagesSolutions For Chapter 8reloadedmemoryPas encore d'évaluation
- Solutions Chapter 4 PDFDocument31 pagesSolutions Chapter 4 PDFNaresh SehdevPas encore d'évaluation
- BA H DSEC IiApplied Econometrics 5th SemDocument7 pagesBA H DSEC IiApplied Econometrics 5th Semthanks navedPas encore d'évaluation
- Pro Touch: HR Generalist AND HR AnalyticsDocument25 pagesPro Touch: HR Generalist AND HR AnalyticsKaranPas encore d'évaluation
- Applications of Econometrics Group Project 2016Document18 pagesApplications of Econometrics Group Project 2016Anton BochkovPas encore d'évaluation
- Course Plans of Department of Economics, University of DhakaDocument63 pagesCourse Plans of Department of Economics, University of Dhakablakmetal56% (18)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsD'EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsÉvaluation : 4.5 sur 5 étoiles4.5/5 (3)
- Calculus Made Easy: Being a Very-Simplest Introduction to Those Beautiful Methods of Reckoning Which are Generally Called by the Terrifying Names of the Differential Calculus and the Integral CalculusD'EverandCalculus Made Easy: Being a Very-Simplest Introduction to Those Beautiful Methods of Reckoning Which are Generally Called by the Terrifying Names of the Differential Calculus and the Integral CalculusÉvaluation : 4.5 sur 5 étoiles4.5/5 (2)
- Limitless Mind: Learn, Lead, and Live Without BarriersD'EverandLimitless Mind: Learn, Lead, and Live Without BarriersÉvaluation : 4 sur 5 étoiles4/5 (6)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)D'EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)Pas encore d'évaluation
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.D'EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Évaluation : 5 sur 5 étoiles5/5 (1)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeD'EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeÉvaluation : 4 sur 5 étoiles4/5 (2)
- Math Workshop, Grade K: A Framework for Guided Math and Independent PracticeD'EverandMath Workshop, Grade K: A Framework for Guided Math and Independent PracticeÉvaluation : 5 sur 5 étoiles5/5 (1)
- Images of Mathematics Viewed Through Number, Algebra, and GeometryD'EverandImages of Mathematics Viewed Through Number, Algebra, and GeometryPas encore d'évaluation
- Geometric Patterns from Patchwork Quilts: And how to draw themD'EverandGeometric Patterns from Patchwork Quilts: And how to draw themÉvaluation : 5 sur 5 étoiles5/5 (1)
- Classroom-Ready Number Talks for Third, Fourth and Fifth Grade Teachers: 1,000 Interactive Math Activities that Promote Conceptual Understanding and Computational FluencyD'EverandClassroom-Ready Number Talks for Third, Fourth and Fifth Grade Teachers: 1,000 Interactive Math Activities that Promote Conceptual Understanding and Computational FluencyPas encore d'évaluation
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormD'EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormÉvaluation : 5 sur 5 étoiles5/5 (5)