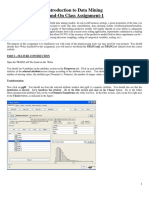
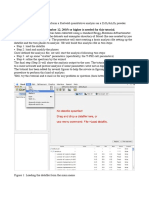
Vous aimerez peut-être aussi
- 02 Econ115a Mod2 Lesson4 WorkingWithVarsAndDataDocument53 pages02 Econ115a Mod2 Lesson4 WorkingWithVarsAndDatalyriemaecutara0Pas encore d'évaluation
- 7 Data Pre-Processing in ClementineDocument7 pages7 Data Pre-Processing in ClementineVũ Tuấn HưngPas encore d'évaluation
- SAS Programming TIPS To Be Used in DevelopmentDocument16 pagesSAS Programming TIPS To Be Used in DevelopmentGiri BalaPas encore d'évaluation
- Plot XYDocument10 pagesPlot XYbubo28Pas encore d'évaluation
- Aggregator Stage: The Stage Editor Has Three PagesDocument8 pagesAggregator Stage: The Stage Editor Has Three PagesmaddhisrikanthreddyPas encore d'évaluation
- Data Analytics 02: Pivoting of Data. You Might Be Familiar With The Concept of Pivoting From BI Tools or Excel: RotateDocument2 pagesData Analytics 02: Pivoting of Data. You Might Be Familiar With The Concept of Pivoting From BI Tools or Excel: RotateJhon Rey BalbastroPas encore d'évaluation
- SPSS Creating New VariablesDocument0 pageSPSS Creating New VariablesthlroPas encore d'évaluation
- Visual Basic Variable: Variable: Provide Temporary Storage of DataDocument6 pagesVisual Basic Variable: Variable: Provide Temporary Storage of DataTharindu ChathurangaPas encore d'évaluation
- SCD StageDocument11 pagesSCD Stagesam2sung2Pas encore d'évaluation
- DWDM Record With AlignmentDocument69 pagesDWDM Record With AlignmentnavyaPas encore d'évaluation
- Assignment 1-Preprocessing HandonDocument6 pagesAssignment 1-Preprocessing HandonCh Ubaid WarraichPas encore d'évaluation
- Instruction: Difficulty With Minimal WithoutDocument13 pagesInstruction: Difficulty With Minimal WithoutZia F RahmanPas encore d'évaluation
- Beta Distribution Fitting: Reliability FunctionDocument15 pagesBeta Distribution Fitting: Reliability Functiongore_11Pas encore d'évaluation
- MC0717 Lab ManualDocument42 pagesMC0717 Lab ManualArun ReddyPas encore d'évaluation
- FINAL RM Lab FileDocument9 pagesFINAL RM Lab FilevinodPas encore d'évaluation
- Interest of Procedural Programming: Solution: IdeaDocument7 pagesInterest of Procedural Programming: Solution: IdeaYesmine MakkesPas encore d'évaluation
- SPSS Course Session II: Describing DataDocument12 pagesSPSS Course Session II: Describing DataaltleoPas encore d'évaluation
- Processing of Diffraction Data With The HIGH SCORE PLUS ProgramDocument23 pagesProcessing of Diffraction Data With The HIGH SCORE PLUS Programbasco costasPas encore d'évaluation
- Plot XYDocument8 pagesPlot XYumairnaeem_90Pas encore d'évaluation
- Matlab Activity 2.1Document7 pagesMatlab Activity 2.1roseleenPas encore d'évaluation
- Consommer Une Calculation View Avec Procedure StockéeDocument5 pagesConsommer Une Calculation View Avec Procedure StockéefiotuiPas encore d'évaluation
- Static VariablesDocument4 pagesStatic VariablesAnjan KumarPas encore d'évaluation
- Guide Lecture NotesDocument19 pagesGuide Lecture NotesMeron MogesPas encore d'évaluation
- Lab 2 - Hierarchical Design and Linear SystemsDocument7 pagesLab 2 - Hierarchical Design and Linear SystemsErcanŞişkoPas encore d'évaluation
- SV 4 Variables Database ENUDocument72 pagesSV 4 Variables Database ENUspctinPas encore d'évaluation
- Data Warehousing and Data Mining LabDocument53 pagesData Warehousing and Data Mining LabAman JollyPas encore d'évaluation
- Product Development Process of Carpentry Shop by Using IDEF and ArenaDocument8 pagesProduct Development Process of Carpentry Shop by Using IDEF and ArenaHassan TalhaPas encore d'évaluation
- Customized Post Processing Using The Result Template ConceptDocument13 pagesCustomized Post Processing Using The Result Template ConceptshochstPas encore d'évaluation
- Session 3,4Document4 pagesSession 3,4Rahul kumarPas encore d'évaluation
- Lectures On Spss 2010Document94 pagesLectures On Spss 2010Superstar_13Pas encore d'évaluation
- Variables Selection and Transformation SAS EMDocument12 pagesVariables Selection and Transformation SAS EMJennifer ParkerPas encore d'évaluation
- QPA TrainingDocument13 pagesQPA TrainingsenthilkumarPas encore d'évaluation
- Stata Application Part IDocument27 pagesStata Application Part Iዮናታን ዓለሙ ዮርዳኖስPas encore d'évaluation
- Basic Selectivity: Jonathan Lewis JL Computer Consultancy London, UKDocument7 pagesBasic Selectivity: Jonathan Lewis JL Computer Consultancy London, UKJack WangPas encore d'évaluation
- Analyze and Select Features For Pump DiagnosticsDocument15 pagesAnalyze and Select Features For Pump DiagnosticsPierpaolo VergatiPas encore d'évaluation
- Sap Abap Interview QuestionsDocument17 pagesSap Abap Interview QuestionsUpendra KumarPas encore d'évaluation
- VB - Unit IiiDocument7 pagesVB - Unit IiiNallsPas encore d'évaluation
- DatapreprocessingDocument8 pagesDatapreprocessingNAVYA TadisettyPas encore d'évaluation
- Reporting Aggregated Data Using The Group FunctionsDocument6 pagesReporting Aggregated Data Using The Group FunctionsFlorin NedelcuPas encore d'évaluation
- Value Set Basics in Oracle Apps R12Document7 pagesValue Set Basics in Oracle Apps R12SuneelTejPas encore d'évaluation
- ReportingquesDocument28 pagesReportingquesanushaPas encore d'évaluation
- Data Mining 2Document40 pagesData Mining 2Piyush RajputPas encore d'évaluation
- Apunts BLOC 1 EstadísticaDocument15 pagesApunts BLOC 1 EstadísticaMayssae EssabbarPas encore d'évaluation
- Chapter 4: SPSS: Spss Overview The SPSS EnvironmentDocument10 pagesChapter 4: SPSS: Spss Overview The SPSS EnvironmentRoi TrawonPas encore d'évaluation
- Tutorial #5: Analyzing Ranking Data: Bank Segmentation ExampleDocument19 pagesTutorial #5: Analyzing Ranking Data: Bank Segmentation ExamplejaninePas encore d'évaluation
- Done - Best A Interview Questions & Answers by Saurav MitraDocument28 pagesDone - Best A Interview Questions & Answers by Saurav Mitraswapna3183100% (1)
- Differential EvolutionDocument11 pagesDifferential EvolutionDuško TovilovićPas encore d'évaluation
- Sorter Transformation 2Document7 pagesSorter Transformation 2DEEPAK KUMAR ARORAPas encore d'évaluation
- Reports & AgentsDocument49 pagesReports & AgentsSrikanthPas encore d'évaluation
- How To Configure ODBC Connection For EXCEL: Informatica 7.x Vs 8.x An SDocument22 pagesHow To Configure ODBC Connection For EXCEL: Informatica 7.x Vs 8.x An Samar_annavarapu1610Pas encore d'évaluation
- Lab Manual Ee-319 Lab Xi (Control Systems Using Matlab)Document38 pagesLab Manual Ee-319 Lab Xi (Control Systems Using Matlab)Parul ThaparPas encore d'évaluation
- PRACTICAL NOTES STATA (Using Version 8 and 10) Stata Is One of The Sophisticated Statistical Software Used in Data Analysis. It Is More UserDocument30 pagesPRACTICAL NOTES STATA (Using Version 8 and 10) Stata Is One of The Sophisticated Statistical Software Used in Data Analysis. It Is More UserMuwanguzi DavidPas encore d'évaluation
- SPREADSHEETDocument10 pagesSPREADSHEETShah MuhammadPas encore d'évaluation
- MODEST MANUAL in EnglishDocument21 pagesMODEST MANUAL in EnglishNikhilPas encore d'évaluation
- Demonstration of Preprocessing On Dataset Student - Arff Aim: This Experiment Illustrates Some of The Basic Data Preprocessing Operations That Can BeDocument4 pagesDemonstration of Preprocessing On Dataset Student - Arff Aim: This Experiment Illustrates Some of The Basic Data Preprocessing Operations That Can BePavan Sankar KPas encore d'évaluation
- Data Mining Problem 2 ReportDocument13 pagesData Mining Problem 2 ReportBabu ShaikhPas encore d'évaluation
- Engo 645Document10 pagesEngo 645sree vishnupriyqPas encore d'évaluation
- ALE SequenceDocument3 pagesALE Sequencesweetu.mPas encore d'évaluation
- Clustering Analysis ProjectDocument16 pagesClustering Analysis ProjectBiaziPas encore d'évaluation
- Anthony Vaccaro MATH 264 Winter 2023 Assignment Assignment 9 Due 04/02/2023 at 11:59pm EDTDocument2 pagesAnthony Vaccaro MATH 264 Winter 2023 Assignment Assignment 9 Due 04/02/2023 at 11:59pm EDTAnthony VaccaroPas encore d'évaluation
- I Sem MathsDocument4 pagesI Sem MathsChandana ChandanaPas encore d'évaluation
- Applying The Normal Curve Concepts in Problem SolvingDocument2 pagesApplying The Normal Curve Concepts in Problem SolvingMaricel Tiongson PiccioPas encore d'évaluation
- MidtermDocument6 pagesMidtermJerland Ocster YaboPas encore d'évaluation
- Sms2309 Intro To Statistics OutlineDocument6 pagesSms2309 Intro To Statistics OutlineSiti SyurieyatiPas encore d'évaluation
- Design Optimization in Pro/ENGINEER Wildfire 2.0: MECH410/520 Pro/E WF2Motion Animation TutorialDocument6 pagesDesign Optimization in Pro/ENGINEER Wildfire 2.0: MECH410/520 Pro/E WF2Motion Animation TutorialAmit RoyPas encore d'évaluation
- Simulation of Diffusion: Steady-State Diffusion Transient DiffusionDocument16 pagesSimulation of Diffusion: Steady-State Diffusion Transient DiffusionSai PreethamPas encore d'évaluation
- ICNAAM 2005: T. E. Simos, G. Psihoyios, Ch. Tsitouras (Eds.)Document13 pagesICNAAM 2005: T. E. Simos, G. Psihoyios, Ch. Tsitouras (Eds.)Vínãy KumarPas encore d'évaluation
- Icomaa 2018 Abstract Book RevisedDocument179 pagesIcomaa 2018 Abstract Book RevisedMUSTAFA BAYRAMPas encore d'évaluation
- M3001 Cheat SheetDocument4 pagesM3001 Cheat SheetVincent KohPas encore d'évaluation
- Tutorial 3 PMC 500 Vigneswery ThangarajDocument6 pagesTutorial 3 PMC 500 Vigneswery ThangarajVigneswery ThangarajPas encore d'évaluation
- Marshall 1997Document13 pagesMarshall 1997Feñita Isabêl Arce NuñezPas encore d'évaluation
- hw3 5Document3 pageshw3 5物理系小薯Pas encore d'évaluation
- Cronbach & T Test AnalysisDocument3 pagesCronbach & T Test AnalysisLohith KumarPas encore d'évaluation
- Advanced Structural Analysis: Felix V. Garde, JR., MsceDocument11 pagesAdvanced Structural Analysis: Felix V. Garde, JR., MsceJAYSON BANTAYANPas encore d'évaluation
- Comparison of Quantitative Techniques of Risk Assessment in Underground Mines (Case Studies)Document16 pagesComparison of Quantitative Techniques of Risk Assessment in Underground Mines (Case Studies)Hafiz Umair AliPas encore d'évaluation
- Group 9 - Tbes 7 Prefinal ExamDocument25 pagesGroup 9 - Tbes 7 Prefinal ExamJD Endaya Jr.Pas encore d'évaluation
- Explanation (Arithmetic and Geometric)Document7 pagesExplanation (Arithmetic and Geometric)Jemyr Ann NavarroPas encore d'évaluation
- 2 CS-C, Course Orientation Materials - CS2614Document8 pages2 CS-C, Course Orientation Materials - CS2614angelo hizonPas encore d'évaluation
- Translation Analysis of Irony in Tenggelamnya Kapal Van Der Wijck by Hamka (Skripsi Okta) Final - OkDocument81 pagesTranslation Analysis of Irony in Tenggelamnya Kapal Van Der Wijck by Hamka (Skripsi Okta) Final - Okktaviankhairy4Pas encore d'évaluation
- MCQS of SeriesDocument14 pagesMCQS of SeriesRamesh Kumar B L100% (3)
- 3 ArguementDocument26 pages3 ArguementMohammad huzaifaPas encore d'évaluation
- Material Point Method: Theory and Applica3onsDocument35 pagesMaterial Point Method: Theory and Applica3onsyin hoe ongPas encore d'évaluation
- Multi Variable Function Test FunctionDocument56 pagesMulti Variable Function Test FunctionJaydeep PatelPas encore d'évaluation
- Critical Thinking WorksheetDocument4 pagesCritical Thinking WorksheetNguyen AnPas encore d'évaluation
- Method of Finite Elements I: Shape Functions: Adrian EggerDocument12 pagesMethod of Finite Elements I: Shape Functions: Adrian EggerheinsteinzPas encore d'évaluation
- ImgDocument1 pageImgmonicacxiPas encore d'évaluation
- Chapter 5: Relations, Functions, and Matrices: Tannaz R.Damavandi Cal Poly PomonaDocument52 pagesChapter 5: Relations, Functions, and Matrices: Tannaz R.Damavandi Cal Poly PomonaCL100% (1)
- Engineering Mathematics 4Document18 pagesEngineering Mathematics 4Mohd Sollahu FikriPas encore d'évaluation
- Trigonometric Limits PDFDocument5 pagesTrigonometric Limits PDFPhil Saraspe0% (1)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsD'EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsÉvaluation : 4.5 sur 5 étoiles4.5/5 (3)
- Dark Data: Why What You Don’t Know MattersD'EverandDark Data: Why What You Don’t Know MattersÉvaluation : 4.5 sur 5 étoiles4.5/5 (3)
- Optimizing DAX: Improving DAX performance in Microsoft Power BI and Analysis ServicesD'EverandOptimizing DAX: Improving DAX performance in Microsoft Power BI and Analysis ServicesPas encore d'évaluation
- Grokking Algorithms: An illustrated guide for programmers and other curious peopleD'EverandGrokking Algorithms: An illustrated guide for programmers and other curious peopleÉvaluation : 4 sur 5 étoiles4/5 (16)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)D'EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)Pas encore d'évaluation
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeD'EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeÉvaluation : 4 sur 5 étoiles4/5 (2)
- Blockchain Basics: A Non-Technical Introduction in 25 StepsD'EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsÉvaluation : 4.5 sur 5 étoiles4.5/5 (24)
- Images of Mathematics Viewed Through Number, Algebra, and GeometryD'EverandImages of Mathematics Viewed Through Number, Algebra, and GeometryPas encore d'évaluation
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormD'EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormÉvaluation : 5 sur 5 étoiles5/5 (5)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.D'EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Évaluation : 5 sur 5 étoiles5/5 (1)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingD'EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingÉvaluation : 4.5 sur 5 étoiles4.5/5 (21)
- Fusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureD'EverandFusion Strategy: How Real-Time Data and AI Will Power the Industrial FuturePas encore d'évaluation
- Calculus Workbook For Dummies with Online PracticeD'EverandCalculus Workbook For Dummies with Online PracticeÉvaluation : 3.5 sur 5 étoiles3.5/5 (8)
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldD'EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldÉvaluation : 3 sur 5 étoiles3/5 (80)
- Mental Math Secrets - How To Be a Human CalculatorD'EverandMental Math Secrets - How To Be a Human CalculatorÉvaluation : 5 sur 5 étoiles5/5 (3)