Vous aimerez peut-être aussi
- ASME B16.5 - 2009 (Parcial)Document27 pagesASME B16.5 - 2009 (Parcial)Cristiano Martinez100% (1)
- Compressor Power Calculator 28-05-20Document2 pagesCompressor Power Calculator 28-05-20Khánh ĐặngPas encore d'évaluation
- FARMATIC Biogasanlagen English PDFDocument12 pagesFARMATIC Biogasanlagen English PDFJulio TovarPas encore d'évaluation
- Journal of Computer and System Sciences: Daniel Hsu, Sham M. Kakade, Tong ZhangDocument21 pagesJournal of Computer and System Sciences: Daniel Hsu, Sham M. Kakade, Tong ZhangAqsaPas encore d'évaluation
- ZZZ 2019 Samir2019Document8 pagesZZZ 2019 Samir2019joshPas encore d'évaluation
- Hidden Markov ModelsDocument10 pagesHidden Markov Modelstbmcmullen+foobartothemax5718100% (2)
- Lopes2017 Article IdentificationOfState-spaceSwiDocument9 pagesLopes2017 Article IdentificationOfState-spaceSwinetero fricksPas encore d'évaluation
- Ijcse11 03 02 133Document7 pagesIjcse11 03 02 133hquynhPas encore d'évaluation
- Applications of Hidden Markov Models To Detecting Multi-Stage Network AttacksDocument10 pagesApplications of Hidden Markov Models To Detecting Multi-Stage Network AttacksPramono PramonoPas encore d'évaluation
- Multivariable Identification of An Activated Sludge Process With Subspace-Based AlgorithmsDocument9 pagesMultivariable Identification of An Activated Sludge Process With Subspace-Based Algorithmsmmm4b9a6Pas encore d'évaluation
- The Implementation of A Hidden Markov MoDocument14 pagesThe Implementation of A Hidden Markov MoFito RhPas encore d'évaluation
- Inlining of Virtual Methods: AbstractDocument21 pagesInlining of Virtual Methods: AbstractfirefoxextslurperPas encore d'évaluation
- A Hierarchical Approach For Discrete-Event Model Identification Incorporating Expert KnowledgeDocument7 pagesA Hierarchical Approach For Discrete-Event Model Identification Incorporating Expert Knowledge夏宇辰Pas encore d'évaluation
- AsalahDocument4 pagesAsalahNA MEPas encore d'évaluation
- crf2 PDFDocument10 pagescrf2 PDFPanji Nur HidayatPas encore d'évaluation
- Conditional Random FieldsDocument10 pagesConditional Random FieldsPanji Nur HidayatPas encore d'évaluation
- Modeling Error Sources in Digital ChannelsDocument8 pagesModeling Error Sources in Digital ChannelsFatih AltunozPas encore d'évaluation
- Reliability Engineering and System SafetyDocument9 pagesReliability Engineering and System Safetygsreis1Pas encore d'évaluation
- Analysis and Comparison of Machine Learning Approaches For Transmission Line Fault Prediction in Power SystemsDocument8 pagesAnalysis and Comparison of Machine Learning Approaches For Transmission Line Fault Prediction in Power Systemsዛላው መናPas encore d'évaluation
- A Comparison of Hmms and Dynamic Bayesian Networks For Recognizing O Ce ActivitiesDocument10 pagesA Comparison of Hmms and Dynamic Bayesian Networks For Recognizing O Ce ActivitiesKanchan GawandePas encore d'évaluation
- CG 10 402 PDFDocument14 pagesCG 10 402 PDFAndres GonzalesPas encore d'évaluation
- Escape Analysis For JavaDocument19 pagesEscape Analysis For JavaAlexanderPas encore d'évaluation
- A Spark-Based Parallel Distributed Posterior Decoding Algorithm For Big Data Hidden Markov Models Decoding ProblemDocument12 pagesA Spark-Based Parallel Distributed Posterior Decoding Algorithm For Big Data Hidden Markov Models Decoding ProblemIAES IJAIPas encore d'évaluation
- Using Singular Value Decomposition Approximation For CollaboratiDocument8 pagesUsing Singular Value Decomposition Approximation For CollaboratiSindy Chairunisa 02Pas encore d'évaluation
- Human Activity Monitoring Based On Hidden Markov Models Using A SmartphoneDocument5 pagesHuman Activity Monitoring Based On Hidden Markov Models Using A SmartphoneCharmi JobanputraPas encore d'évaluation
- A Tutorial On Hidden Markov Models and Selected Applications in Speech RecognitionDocument30 pagesA Tutorial On Hidden Markov Models and Selected Applications in Speech Recognitionazizd15Pas encore d'évaluation
- Unit - 2 - Mathematical Preliminaries For Lossless Compression ModelsDocument12 pagesUnit - 2 - Mathematical Preliminaries For Lossless Compression ModelsJanvi PatelPas encore d'évaluation
- A Pattern Is An Abstract Object, Such As A Set of Measurements Describing A Physical ObjectDocument12 pagesA Pattern Is An Abstract Object, Such As A Set of Measurements Describing A Physical Objectriddickdanish1Pas encore d'évaluation
- Hidden Markov Models in Univariate GaussiansDocument34 pagesHidden Markov Models in Univariate GaussiansIvoTavaresPas encore d'évaluation
- Classification System For Handwritten Devnagari Numeral With A Neural Network ApproachDocument8 pagesClassification System For Handwritten Devnagari Numeral With A Neural Network Approacheditor_ijarcssePas encore d'évaluation
- Using Operational Research and Advanced Informatics For C - 2003 - IFAC ProceediDocument6 pagesUsing Operational Research and Advanced Informatics For C - 2003 - IFAC ProceediNGUYEN MANHPas encore d'évaluation
- Assignment 2, EDAP01: 1 StatementDocument4 pagesAssignment 2, EDAP01: 1 StatementAxel RosenqvistPas encore d'évaluation
- Imprtant Hof-Wil-04-hybridDiagnosisDocument14 pagesImprtant Hof-Wil-04-hybridDiagnosisboucharebPas encore d'évaluation
- 2.3. Mining Graph DataDocument6 pages2.3. Mining Graph DataNaresh ReddyPas encore d'évaluation
- Realtime Gesture Following and RecognitionDocument12 pagesRealtime Gesture Following and Recognition姚熙Pas encore d'évaluation
- The Expectation-Maximization Algorithm: IEEE Signal Processing Magazine December 1996Document15 pagesThe Expectation-Maximization Algorithm: IEEE Signal Processing Magazine December 1996Anca DragoiPas encore d'évaluation
- Segmentation of Connected Arabic Characters Using Hidden Markov ModelsDocument5 pagesSegmentation of Connected Arabic Characters Using Hidden Markov Modelsapi-3754855Pas encore d'évaluation
- Introduction To Monte Carlo MethodsDocument30 pagesIntroduction To Monte Carlo Methodscrisevelise100% (1)
- Site - Sherry TowersDocument5 pagesSite - Sherry TowersThiago MPPas encore d'évaluation
- Escape Analysis For JavaDocument19 pagesEscape Analysis For JavapostscriptPas encore d'évaluation
- A Tutorial On Hidden Markov Models and Selected Applications in Speech RecognitionDocument30 pagesA Tutorial On Hidden Markov Models and Selected Applications in Speech Recognitionsarthak shahPas encore d'évaluation
- Hidden Markov Models For Modeling and Recognizing Gesture Under VariationDocument36 pagesHidden Markov Models For Modeling and Recognizing Gesture Under Variationjesus1843Pas encore d'évaluation
- Feature Selection For SVMS: J. Weston, S. Mukherjee, O. Chapelle, M. Pontil T. Poggio, V. VapnikDocument7 pagesFeature Selection For SVMS: J. Weston, S. Mukherjee, O. Chapelle, M. Pontil T. Poggio, V. VapnikaaayoubPas encore d'évaluation
- Use of Informational UncertaintyDocument6 pagesUse of Informational UncertaintyGennady MankoPas encore d'évaluation
- Comment Toxicity ReportDocument6 pagesComment Toxicity ReportPallavi BottuPas encore d'évaluation
- The Expectation-Maximization Algorithm: IEEE Signal Processing Magazine December 1996Document15 pagesThe Expectation-Maximization Algorithm: IEEE Signal Processing Magazine December 1996Omar Lopez-RinconPas encore d'évaluation
- A Fault Detection Approach Based On Machine Learning Models: (Legarza, RMM, Rramirez) @itesm - MXDocument2 pagesA Fault Detection Approach Based On Machine Learning Models: (Legarza, RMM, Rramirez) @itesm - MXsachinPas encore d'évaluation
- Formal Analysis of Fault Tree Using Probabilistic Model Checking: A Solar Array Case StudyDocument6 pagesFormal Analysis of Fault Tree Using Probabilistic Model Checking: A Solar Array Case StudyKazim RazaPas encore d'évaluation
- ProofDocument2 pagesProofanand vihariPas encore d'évaluation
- On-Line Handwritten English Word Recognition Based On Cascade Connection CharacterDocument4 pagesOn-Line Handwritten English Word Recognition Based On Cascade Connection CharacterPradeepPas encore d'évaluation
- Enhanced Profile Hidden Markov Model For Metamorphic Malware DetectionDocument7 pagesEnhanced Profile Hidden Markov Model For Metamorphic Malware DetectionInternational Journal of Innovative Science and Research TechnologyPas encore d'évaluation
- Robot Reliability Through Fuzzy Markov Models: February 1998Document7 pagesRobot Reliability Through Fuzzy Markov Models: February 1998StanislavPas encore d'évaluation
- Journal of Statistical Software: Multiple Imputation With Diagnostics (Mi) in R: Opening Windows Into The Black BoxDocument31 pagesJournal of Statistical Software: Multiple Imputation With Diagnostics (Mi) in R: Opening Windows Into The Black BoxAbi ZuñigaPas encore d'évaluation
- Bootstrapping and Learning PDFA in Data Streams: JMLR: Workshop and Conference Proceedings 21: - , 2012 The 11th ICGIDocument15 pagesBootstrapping and Learning PDFA in Data Streams: JMLR: Workshop and Conference Proceedings 21: - , 2012 The 11th ICGIKevin MondragonPas encore d'évaluation
- Automatic Reparameterisation of Probabilistic ProgramsDocument10 pagesAutomatic Reparameterisation of Probabilistic ProgramsdperepolkinPas encore d'évaluation
- Exploiting Transitivity For Learning Person Re-Identification Models On A BudgetDocument9 pagesExploiting Transitivity For Learning Person Re-Identification Models On A BudgetRoman PerezPas encore d'évaluation
- Genetic Algorithm Optimization For Selecting The Best Architecture of A Multi-Layer Perceptron Neural Network: A Credit Scoring CaseDocument8 pagesGenetic Algorithm Optimization For Selecting The Best Architecture of A Multi-Layer Perceptron Neural Network: A Credit Scoring Caseazrim02Pas encore d'évaluation
- An Introduction To Conditional Random Fields: Charles Sutton and Andrew MccallumDocument90 pagesAn Introduction To Conditional Random Fields: Charles Sutton and Andrew Mccallumgirishkulkarni008Pas encore d'évaluation
- Survey SummaryDocument8 pagesSurvey SummaryK VENKATA SRAVANIPas encore d'évaluation
- Mixture Models and ApplicationsD'EverandMixture Models and ApplicationsNizar BouguilaPas encore d'évaluation
- Color + Design Blog / History of The ColorDocument11 pagesColor + Design Blog / History of The Colorapi-8348981Pas encore d'évaluation
- Google App Engine Phonenumberproperty No ValueDocument2 pagesGoogle App Engine Phonenumberproperty No Valueapi-8348981Pas encore d'évaluation
- DNS System TopologyDocument1 pageDNS System TopologyAbe LiPas encore d'évaluation
- Ddo Article RittelDocument20 pagesDdo Article RitteldiarysapoPas encore d'évaluation
- Open Uniform B Spline DelphiDocument8 pagesOpen Uniform B Spline Delphiapi-8348981Pas encore d'évaluation
- Second Order CyberneticsDocument23 pagesSecond Order Cyberneticsapi-8348981Pas encore d'évaluation
- Anatomy of GoogleDocument26 pagesAnatomy of GoogleSerge100% (2)
- Even Enri Fun Is Play's Raison D'être: Play NeedsDocument1 pageEven Enri Fun Is Play's Raison D'être: Play Needsapi-6282867Pas encore d'évaluation
- Marketing Management Human-Computer Interface Public Affairs Middle Eastern StudiesDocument1 pageMarketing Management Human-Computer Interface Public Affairs Middle Eastern Studiesapi-8348981Pas encore d'évaluation
- Experience CycleDocument7 pagesExperience Cyclefakkurudeen.arPas encore d'évaluation
- Notes On The Synthesis of FormDocument5 pagesNotes On The Synthesis of Formapi-8348981Pas encore d'évaluation
- Stages in Organizational MaturityDocument14 pagesStages in Organizational Maturityapi-8348981Pas encore d'évaluation
- Sustainable Solutions For Ending Hunger and Poverty Supported byDocument4 pagesSustainable Solutions For Ending Hunger and Poverty Supported byapi-8348981Pas encore d'évaluation
- Innovation A Model of Innovation But What Is It?Document1 pageInnovation A Model of Innovation But What Is It?api-8348981Pas encore d'évaluation
- Fluid Mechanics Circuits Material Engineering Tribology Computer Science OperationsDocument1 pageFluid Mechanics Circuits Material Engineering Tribology Computer Science Operationsapi-8348981Pas encore d'évaluation
- The Measurement of Intellectual in Uence Ignacio Palacios-Huerta and OscarDocument35 pagesThe Measurement of Intellectual in Uence Ignacio Palacios-Huerta and Oscarapi-8348981Pas encore d'évaluation
- Michael PolanyiDocument17 pagesMichael Polanyiapi-8348981100% (1)
- Consider Online Shopping Site, Identify Vulnerability, Threat, and Controls. AnsDocument5 pagesConsider Online Shopping Site, Identify Vulnerability, Threat, and Controls. AnsPhenoमिनल IdiotsPas encore d'évaluation
- (Cornelius Lanczos) Linear Differential OperatorsDocument582 pages(Cornelius Lanczos) Linear Differential Operatorsmichel.walz01Pas encore d'évaluation
- Solution For P2Document8 pagesSolution For P2유준우Pas encore d'évaluation
- Interpretability With Diversified-By-Design Rules Skope-Rules A Python PackageDocument1 pageInterpretability With Diversified-By-Design Rules Skope-Rules A Python PackageHao OuYangPas encore d'évaluation
- Determinants by NV Sir - JEE BriefDocument48 pagesDeterminants by NV Sir - JEE BriefdahaleswaroopPas encore d'évaluation
- (I.smith D.griffiths) Programming The Finite Element MethodDocument478 pages(I.smith D.griffiths) Programming The Finite Element MethodIgor Alarcón100% (4)
- SP14 CS188 Lecture 3 - Informed SearchDocument69 pagesSP14 CS188 Lecture 3 - Informed Searchimoptra143Pas encore d'évaluation
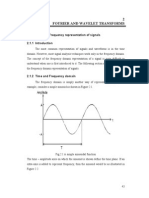
- 2 Fourier and Wavelet Transforms: 2.1. Time and Frequency Representation of SignalsDocument25 pages2 Fourier and Wavelet Transforms: 2.1. Time and Frequency Representation of SignalszvjpPas encore d'évaluation
- Several NP-Hard Problems Arising in Robust Stability AnalysisDocument7 pagesSeveral NP-Hard Problems Arising in Robust Stability AnalysisSilvia TruşcăPas encore d'évaluation
- Lecture 0Document33 pagesLecture 0Devyansh GuptaPas encore d'évaluation
- SMS Assignement 2016 BATCHDocument1 pageSMS Assignement 2016 BATCHYogesh KumarPas encore d'évaluation
- Bernoulli's Equation: Dy Pxy Qxy N N DXDocument13 pagesBernoulli's Equation: Dy Pxy Qxy N N DXZulqarnain KhanPas encore d'évaluation
- Cryptography, Winter Term 16/17: Sample Solution To Assignment 6Document3 pagesCryptography, Winter Term 16/17: Sample Solution To Assignment 6Safenat SafenatPas encore d'évaluation
- Lecture - CAPITAL ALLOCATION TO RISKY ASSESTSDocument40 pagesLecture - CAPITAL ALLOCATION TO RISKY ASSESTSНаиль ИсхаковPas encore d'évaluation
- Regno: Name: Cse 102 - Data Structures and Algorithms - D1 & D2Document12 pagesRegno: Name: Cse 102 - Data Structures and Algorithms - D1 & D2mansurPas encore d'évaluation
- Data Driven ControlDocument6 pagesData Driven ControlShivan BiradarPas encore d'évaluation
- Avinash K. Dixit) Optimization in Economic Theory (BookFi - Org) - 1Document101 pagesAvinash K. Dixit) Optimization in Economic Theory (BookFi - Org) - 1presi_studentPas encore d'évaluation
- UNIT III TheoryDocument6 pagesUNIT III TheoryRanchuPas encore d'évaluation
- Support Vector MachinesDocument19 pagesSupport Vector MachinesJimsy JohnsonPas encore d'évaluation
- CIT 891 TMA 2 Quiz QuestionDocument3 pagesCIT 891 TMA 2 Quiz QuestionjohnPas encore d'évaluation
- Chapter 4 ClassificationDocument78 pagesChapter 4 ClassificationMohamedsultan AwolPas encore d'évaluation
- Playfair Cipher With ExamplesDocument4 pagesPlayfair Cipher With ExamplesRicha SharmaPas encore d'évaluation
- 04a-Local and Global OptimaDocument16 pages04a-Local and Global OptimaFahad ZiaPas encore d'évaluation
- Physics 831 Quiz #1 - Friday, Sep. 7: GC V N, V GCDocument1 pagePhysics 831 Quiz #1 - Friday, Sep. 7: GC V N, V GCmohamedPas encore d'évaluation
- Generative AiDocument13 pagesGenerative Aiworshipndlovu580Pas encore d'évaluation
- Pre Synthesis and Post Synthesis Power Estimation of VLSI Circuits Using Machine Learning ApproachDocument15 pagesPre Synthesis and Post Synthesis Power Estimation of VLSI Circuits Using Machine Learning Approachsohan kamblePas encore d'évaluation
- Performance Evaluation of Non-Latin Characters Based (Arabic) Symmetric Encryption AlgorithmDocument9 pagesPerformance Evaluation of Non-Latin Characters Based (Arabic) Symmetric Encryption AlgorithmInternational Journal of Innovative Science and Research TechnologyPas encore d'évaluation
- Quantum Data Compression, Quantum Information Generation, and The Density-Matrix Renormalization Group MethodDocument8 pagesQuantum Data Compression, Quantum Information Generation, and The Density-Matrix Renormalization Group MethodLathish KumarPas encore d'évaluation
- Encryption and Decryption in CryptographyDocument12 pagesEncryption and Decryption in CryptographyTanmay SarkarPas encore d'évaluation
- Proportional Control For Set Point Change (Servo Problem) Proportional Control For Load Change (Regulatory Problem)Document19 pagesProportional Control For Set Point Change (Servo Problem) Proportional Control For Load Change (Regulatory Problem)Imran UnarPas encore d'évaluation