Fundamentals of Multimedia, Chapter 7
Chapter 7
Lossless Compression Algorithms 7.1 Introduction 7.2 Basics of Information Theory 7.3 Run-Length Coding 7.4 Variable-Length Coding (VLC) 7.5 Dictionary-based Coding 7.6 Arithmetic Coding 7.7 Lossless Image Compression 7.8 Further Exploration
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
7.1 Introduction
Compression: the process of coding that will eectively reduce the total number of bits needed to represent certain information.
Input data
Encoder (compression)
Storage or networks
Decoder (decompression)
Output data
Fig. 7.1: A General Data Compression Scheme.
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Introduction (contd)
If the compression and decompression processes induce no information loss, then the compression scheme is lossless; otherwise, it is lossy.
Compression ratio: B0 compression ratio = B1 B0 number of bits before compression B1 number of bits after compression
(7.1)
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
7.2 Basics of Information Theory
The entropy of an information source with alphabet S = {s1, s2, . . . , sn} is:
n
= H (S ) =
i=1 n
pi log2
1 pi
(7.2)
pi log2 pi
i=1
(7.3)
pi probability that symbol si will occur in S .
1 indicates the amount of information ( self-information log2 p i as dened by Shannon) contained in si, which corresponds to the number of bits needed to encode si.
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Distribution of Gray-Level Intensities
pi
1 1/256 2/3 1/3
pi
i
0 (a) 255 0 (b) 255
Fig. 7.2 Histograms for Two Gray-level Images. Fig. 7.2(a) shows the histogram of an image with uniform distribution of gray-level intensities, i.e., i pi = 1/256. Hence, the entropy of this image is: log2 256 = 8 (7.4)
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Entropy and Code Length
As can be seen in Eq. (7.3): the entropy is a weighted-sum 1 ; hence it represents the average amount of of terms log2 p i information contained per symbol in the source S . The entropy species the lower bound for the average number of bits to code each symbol in S , i.e., l
(7.5)
l - the average length (measured in bits) of the codewords produced by the encoder.
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
7.3 Run-Length Coding
Memoryless Source: an information source that is independently distributed. Namely, the value of the current symbol does not depend on the values of the previously appeared symbols. Instead of assuming memoryless source, Run-Length Coding (RLC) exploits memory present in the information source. Rationale for RLC: if the information source has the property that symbols tend to form continuous groups, then such symbol and the length of the group can be coded.
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
7.4 Variable-Length Coding (VLC)
Shannon-Fano Algorithm a top-down approach 1. Sort the symbols according to the frequency count of their occurrences. 2. Recursively divide the symbols into two parts, each with approximately the same number of counts, until all parts contain only one symbol. An Example: coding of HELLO Symbol Count H 1 E 1 L 2 O 1
Frequency count of the symbols in HELLO. 8
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
(5) 0 L:(2) 1 H,E,O:(3) L:(2) 0
(5) 1 (3) 0 H:(1) 1 E,O:(2) (b) (5) 0 1 (3) 0 H:(1) 1 (2) 0 E:(1) (c) 1 O:(1)
(a)
L:(2)
Fig. 7.3: Coding Tree for HELLO by Shannon-Fano.
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Table 7.1:
Result of Performing Shannon-Fano on HELLO Count 2 1 1 1
1 log2 p
Symbol L H E O
Code 0 10 110 111
# of bits used 2 2 3 3 10
1.32 2.32 2.32 2.32
TOTAL number of bits:
10
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
(5) 0 L,H:(3) 1 E,O:(2) 0 L:(2) (a) (2) 0 1 H:(1)
(5) 1 0 E:(1) (b) (3) 1 O:(1)
Fig. 7.4 Another coding tree for HELLO by Shannon-Fano.
11
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Table 7.2: Another Result of Performing Shannon-Fano on HELLO (see Fig. 7.4) Symbol L H E O Count 2 1 1 1
1 log2 p
Code 00 01 10 11
# of bits used 4 2 2 2 10
1.32 2.32 2.32 2.32
TOTAL number of bits:
12
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Human Coding
ALGORITHM 7.1 Human Coding Algorithm a bottomup approach 1. Initialization: Put all symbols on a list sorted according to their frequency counts. 2. Repeat until the list has only one symbol left:
(1) From the list pick two symbols with the lowest frequency counts. Form a Human subtree that has these two symbols as child nodes and create a parent node. (2) Assign the sum of the childrens frequency counts to the parent and insert it into the list such that the order is maintained. (3) Delete the children from the list.
3. Assign a codeword for each leaf based on the path from the root. 13
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
P1:(2) 0 E:(1) 1 O:(1) H:(1) 0
P2:(3) 1 P1:(2) 0 E:(1) 1 O:(1) (b) P3:(5) 0 1 P2:(3) 0 H:(1) 1 0 E:(1) (c) P1:(2) 1 O:(1)
(a)
L:(2)
Fig. 7.5: Coding Tree for HELLO using the Human Algorithm.
14
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Human Coding (contd)
In Fig. 7.5, new symbols P1, P2, P3 are created to refer to the parent nodes in the Human coding tree. The contents in the list are illustrated below: After After After After initialization: iteration (a): iteration (b): iteration (c): L H E O L P1 H L P2 P3
15
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Properties of Human Coding
1. Unique Prex Property: No Human code is a prex of any other Human code - precludes any ambiguity in decoding. 2. Optimality: minimum redundancy code - proved optimal for a given data model (i.e., a given, accurate, probability distribution): The two least frequent symbols will have the same length for their Human codes, diering only at the last bit. Symbols that occur more frequently will have shorter Human codes than symbols that occur less frequently. The average code length for an information source S is strictly less than + 1. Combined with Eq. (7.5), we have: l<+1 16
(7.6)
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Extended Human Coding
Motivation: All codewords in Human coding have integer bit lengths. It is wasteful when pi is very large and hence 1 is close to 0. log2 p
i
Why not group several symbols together and assign a single codeword to the group as a whole? Extended Alphabet: For alphabet S = {s1, s2, . . . , sn}, if k symbols are grouped together, then the extended alphabet is:
k symbols ( k ) = {s1s1 . . . s1, s1s1 . . . s2, . . . , s1s1 . . . sn, S
s1s1 . . . s2s1, . . . , snsn . . . sn}. the size of the new alphabet S (k) is nk . 17
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Extended Human Coding (contd)
It can be proven that the average # of bits for each symbol is:
l<+
1 k
(7.7)
An improvement over the original Human coding, but not much.
Problem: If k is relatively large (e.g., k 3), then for most practical applications where n 1, nk implies a huge symbol table impractical.
18
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Adaptive Human Coding
Adaptive Human Coding: statistics are gathered and updated dynamically as the data stream arrives. ENCODER ------Initial_code(); while not EOF { get(c); encode(c); update_tree(c); } 19 DECODER ------Initial_code(); while not EOF { decode(c); output(c); update_tree(c); }
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Adaptive Human Coding (Contd)
Initial code assigns symbols with some initially agreed upon codes, without any prior knowledge of the frequency counts. update tree constructs an Adaptive Human tree. It basically does two things: (a) increments the frequency counts for the symbols (including any new ones). (b) updates the conguration of the tree. The encoder and decoder must use exactly the same initial code and update tree routines.
20
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Notes on Adaptive Human Tree Updating
Nodes are numbered in order from left to right, bottom to top. The numbers in parentheses indicates the count. The tree must always maintain its sibling property, i.e., all nodes (internal and leaf) are arranged in the order of increasing counts. If the sibling property is about to be violated, a swap procedure is invoked to update the tree by rearranging the nodes. When a swap is necessary, the farthest node with count N is swapped with the node whose count has just been increased to N + 1.
21
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
9. (9) 7. (4) 8. P:(5) 5. (2) 6. (2) 5. (2) 7. (5)
9. (10)
8. P:(5) 6. (3)
1. A:(1)
2. B:(1)
3. C:(1)
4. D:(1)
1. D:(1)
2. B:(1)
3. C:(1)
4. A:(2)
(a) A Huffman tree
(b) Receiving 2nd A triggered a swap
9. (10) 9. (10) 7. (5) 8. P:(5) 5. (2) 6. (3) 3. C:(1) 1. D:(1) 2. B:(1) 3. C:(1) 4. A:(2+1) 1. D:(1) 2. B:(1) 5. A:(3) 4. (2) 7. (5+1) 8. P:(5) 6. (3) 7. P:(5)
9. (11)
8. (6) 6. (3) 5. A:(3) 4. (2) 3. C:(1) 1. D:(1) 2. B:(1)
(c1) A swap is needed after receiving 3rd A
(c2) Another swap is needed
(c3) The Huffman tree after receiving 3rd A
Fig. 7.6: Node Swapping for Updating an Adaptive Human Tree
22
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Another Example: Adaptive Human Coding
This is to clearly illustrate more implementation details. We show exactly what bits are sent, as opposed to simply stating how the tree is updated.
An additional rule: if any character/symbol is to be sent the rst time, it must be preceded by a special symbol, NEW. The initial code for NEW is 0. The count for NEW is always kept as 0 (the count is never increased); hence it is always denoted as NEW:(0) in Fig. 7.7.
23
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Table 7.3: Initial code assignment for AADCCDD using adaptive Human coding. Initial Code NEW: A: B: C: D: . . . 0 00001 00010 00011 00100 . . .
24
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
(1) 0 NEW:(0) "A" 1 A:(1) 0 NEW:(0)
(2) 1 A:(2) "AA"
(3) (1) 0 NEW:(0) 0 1 D:(1) "AAD" 1 A:(2) 0 NEW:(0) (1) 0 1 C:(1) (2) 0 1
(4) 1 A:(2) D:(1)
"AADC"
Fig. 7.7 Adaptive Human tree for AADCCDD.
25
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
(4) (2) (1) 0 0 NEW:(0) 1 C:(1+1) "AADCC" Step 1 0 1 D:(1) 1 A:(2) 0 NEW:(0) (2+1) (1) 0 1 D:(1) 0 1
(4) 1 A:(2) C:(2)
"AADCC" Step 2
(5) 0 A:(2) 0 NEW:(0) (1) 1 0 1 D:(1) (3) 1 C:(2) A:(2) 0
(6) 1 (2) 0 NEW:(0) 0 1 D:(2) (4) 1 C:(2) D:(3) 0
(7) 1 (2) 0 NEW:(0) 0 1 A:(2) (4) 1 C:(2)
"AADCC" Step 3
"AADCCD"
"AADCCDD"
Fig. 7.7 (contd) Adaptive Human tree for AADCCDD. 26
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Table 7.4 decoder
Symbol Code
Sequence of symbols and codes sent to the
NEW 0
A 00001
A 1
NEW 0
D 00100
NEW 00
C 00011
C 001
D 101
D 101
It is important to emphasize that the code for a particular symbol changes during the adaptive Human coding process. For example, after AADCCDD, when the character D overtakes A as the most frequent symbol, its code changes from 101 to 0.
The Squeeze Page on this books web site provides a Java applet for adaptive Human coding.
27
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
7.5 Dictionary-based Coding
LZW uses xed-length codewords to represent variable-length strings of symbols/characters that commonly occur together, e.g., words in English text. the LZW encoder and decoder build up the same dictionary dynamically while receiving the data. LZW places longer and longer repeated entries into a dictionary, and then emits the code for an element, rather than the string itself, if the element has already been placed in the dictionary.
28
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
ALGORITHM 7.2 LZW Compression BEGIN s = next input character; while not EOF { c = next input character; if s + c exists in the dictionary s = s + c; else { output the code for s; add string s + c to the dictionary with a new code; s = c; } } output the code for s; END 29
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Example 7.2 CABABBA
LZW compression for string ABABBAB-
Lets start with a very simple dictionary (also referred to as a string table), initially containing only 3 characters, with codes as follows: code string --------------1 A 2 B 3 C Now if the input string is ABABBABCABABBA, the LZW compression algorithm works as follows: 30
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
s c output code string --------------------------------1 A 2 B 3 C --------------------------------A B 1 4 AB B A 2 5 BA A B AB B 4 6 ABB B A BA B 5 7 BAB B C 2 8 BC C A 3 9 CA A B AB A 4 10 ABA A B AB B ABB A 6 11 ABBA A EOF 1 The output codes are: 1 2 4 5 2 3 4 6 1. Instead of sending 14 characters, only 9 codes need to be sent (compression ratio = 14/9 = 1.56).
31
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
ALGORITHM 7.3 LZW Decompression (simple version)
BEGIN s = NIL; while not EOF { k = next input code; entry = dictionary entry for k; output entry; if (s != NIL) add string s + entry[0] to dictionary with a new code; s = entry; } END
Example 7.3: LZW decompression for string ABABBABCABABBA. Input codes to the decoder are 1 2 4 5 2 3 4 6 1. The initial string table is identical to what is used by the encoder.
32
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
The LZW decompression algorithm then works as follows:
s k entry/output code string -------------------------------------1 A 2 B 3 C -------------------------------------NIL 1 A A 2 B 4 AB B 4 AB 5 BA AB 5 BA 6 ABB BA 2 B 7 BAB B 3 C 8 BC C 4 AB 9 CA AB 6 ABB 10 ABA ABB 1 A 11 ABBA A EOF
Apparently, the output string is ABABBABCABABBA, a truly lossless result! 33
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
ALGORITHM 7.4 LZW Decompression (modied) BEGIN s = NIL; while not EOF { k = next input code; entry = dictionary entry for k; /* exception handler */ if (entry == NULL) entry = s + s[0]; output entry; if (s != NIL) add string s + entry[0] to dictionary with a new code; s = entry; } END 34
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
LZW Coding (contd)
In real applications, the code length l is kept in the range of [l0, lmax]. The dictionary initially has a size of 2l0 . When it is lled up, the code length will be increased by 1; this is allowed to repeat until l = lmax. When lmax is reached and the dictionary is lled up, it needs to be ushed (as in Unix compress, or to have the LRU (least recently used) entries removed.
35
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
7.6 Arithmetic Coding
Arithmetic coding is a more modern coding method that usually out-performs Human coding. Human coding assigns each symbol a codeword which has an integral bit length. Arithmetic coding can treat the whole message as one unit. A message is represented by a half-open interval [a, b) where a and b are real numbers between 0 and 1. Initially, the interval is [0, 1). When the message becomes longer, the length of the interval shortens and the number of bits needed to represent the interval increases.
36
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
ALGORITHM 7.5 Arithmetic Coding Encoder BEGIN low = 0.0;
high = 1.0;
range = 1.0;
while (symbol != terminator) { get (symbol); low = low + range * Range_low(symbol); high = low + range * Range_high(symbol); range = high - low; } output a code so that low <= code < high; END 37
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Example: Encoding in Arithmetic Coding
Symbol A B C D E F $ Probability 0.2 0.1 0.2 0.05 0.3 0.05 0.1 Range [0, 0.2) [0.2, 0.3) [0.3, 0.5) [0.5, 0.55) [0.55, 0.85) [0.85, 0.9) [0.9, 1.0)
(a) Probability distribution of symbols. Fig. 7.8: Arithmetic Coding: Encode Symbols CAEE$
38
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
1.0 $ 0.9 0.85 F 0.5 $ F 0.34 $ F 0.334 $ F 0.3322 $ F 0.3322 $ F
0.55 0.5
C 0.3 B 0.2 A
0.3
0.3
0.322
0.3286
0.33184
Fig. 7.8(b) Graphical display of shrinking ranges. 39
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Symbol C A E E $
low 0 0.3 0.30 0.322 0.3286 0.33184
high 1.0 0.5 0.34 0.334 0.3322 0.33220
range 1.0 0.2 0.04 0.012 0.0036 0.00036
(c) New low, high, and range generated.
Fig. 7.8 (contd): Arithmetic Coding: Encode Symbols CAEE$
40
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
PROCEDURE 7.2 Generating Codeword for Encoder BEGIN code = 0; k = 1; while (value(code) < low) { assign 1 to the kth binary fraction bit if (value(code) > high) replace the kth bit by 0 k = k + 1; } END The nal step in Arithmetic encoding calls for the generation of a number that falls within the range [low, high). The above algorithm will ensure that the shortest binary codeword is found. 41
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
ALGORITHM 7.6 Arithmetic Coding Decoder BEGIN get binary code and convert to decimal value = value(code); Do { find a symbol s so that Range_low(s) <= value < Range_high(s); output s; low = Rang_low(s); high = Range_high(s); range = high - low; value = [value - low] / range; } Until symbol s is a terminator END 42
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Table 7.5 Arithmetic coding: decode symbols CAEE$
value 0.33203125 0.16015625 0.80078125 0.8359375 0.953125
Output Symbol C A E E $
low 0.3 0.0 0.55 0.55 0.9
high 0.5 0.2 0.85 0.85 1.0
range 0.2 0.2 0.3 0.3 0.1
43
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
7.7 Lossless Image Compression
Approaches of Dierential Coding of Images:
Given an original image I (x, y ), using a simple dierence operator we can dene a dierence image d(x, y ) as follows: d(x, y ) = I (x, y ) I (x 1, y ) (7.9)
or use the discrete version of the 2-D Laplacian operator to dene a dierence image d(x, y ) as d(x, y ) = 4 I (x, y ) I (x, y 1) I (x, y + 1) I (x + 1, y ) I (x 1, y ) (7.10)
Due to spatial redundancy existed in normal images I , the dierence image d will have a narrower histogram and hence a smaller entropy, as shown in Fig. 7.9.
44
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
(a)
4 3.5 3 2.5 2 1.5 1 0.5 0 104
(b)
15 10 5 0 80 60 40 20 0 20 40 60 80 104
50
100 150 200 250
(c)
(d)
Fig. 7.9: Distributions for Original versus Derivative Images. (a,b): Original gray-level image and its partial derivative image; (c,d): Histograms for original and derivative images. (This gure uses a commonly employed image called Barb.)
45
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Lossless JPEG
Lossless JPEG: A special case of the JPEG image compression. The Predictive method 1. Forming a dierential prediction: A predictor combines the values of up to three neighboring pixels as the predicted value for the current pixel, indicated by X in Fig. 7.10. The predictor can use any one of the seven schemes listed in Table 7.6. 2. Encoding: The encoder compares the prediction with the actual pixel value at the position X and encodes the dierence using one of the lossless compression techniques we have discussed, e.g., the Human coding scheme.
46
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
C A
B X
Fig. 7.10: Neighboring Pixels for Predictors in Lossless JPEG.
Note: Any of A, B, or C has already been decoded before it is used in the predictor, on the decoder side of an encodedecode cycle.
47
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Table 7.6:
Predictors for Lossless JPEG
Prediction A B C A + B - C A + (B - C) / 2 B + (A - C) / 2 (A + B) / 2
Predictor P1 P2 P3 P4 P5 P6 P7
48
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
Table 7.7: Comparison with other lossless compression programs
Compression Program Compression Ratio Lena football Lossless JPEG Optimal lossless JPEG compress (LZW) gzip (LZ77) gzip -9 (optimal LZ77) pack (Human coding) 1.45 1.49 0.86 1.08 1.08 1.02 1.54 1.67 1.24 1.36 1.36 1.12 F-18 owers 2.29 2.71 2.21 3.10 3.13 1.19 1.26 1.33 0.87 1.05 1.05 1.00
49
Li & Drew c Prentice Hall 2003
Fundamentals of Multimedia, Chapter 7
7.8 Further Exploration
Text books:
The Data Compression Book by M. Nelson Introduction to Data Compression by K. Sayood Web sites: Link to Further Exploration for Chapter 7.. including:
An excellent resource for data compression compiled by Mark Nelson. The Theory of Data Compression webpage. The FAQ for the comp.compression and comp.compression.research groups. A set of applets for lossless compression. A good introduction to Arithmetic coding Grayscale test images f-18.bmp, owers.bmp, football.bmp, lena.bmp
50
Li & Drew c Prentice Hall 2003
Vous aimerez peut-être aussi
- Lecture 3 Compressiond AlgoDocument65 pagesLecture 3 Compressiond AlgoKanishka GopalPas encore d'évaluation
- Fundamentals of MultimediaDocument37 pagesFundamentals of MultimediablablaPas encore d'évaluation
- Chapter 7 Lossless Compression AlgorithmsDocument25 pagesChapter 7 Lossless Compression AlgorithmsToaster97Pas encore d'évaluation
- Data Compression (Pt2)Document22 pagesData Compression (Pt2)Syahmi AhmadPas encore d'évaluation
- Multimedia Igds MSC Exam 2000 SolutionsDocument16 pagesMultimedia Igds MSC Exam 2000 SolutionsDhoulkamalPas encore d'évaluation
- 3.multimedia Compression AlgorithmsDocument23 pages3.multimedia Compression Algorithmsaishu sillPas encore d'évaluation
- Data Compression Data Compression: Chapter FourDocument22 pagesData Compression Data Compression: Chapter FourDawit BassaPas encore d'évaluation
- Presentation MultimediaDocument15 pagesPresentation MultimediaPriyanka MeenaPas encore d'évaluation
- Data CompressionDocument28 pagesData CompressionKimPas encore d'évaluation
- 6.1 Lossless Compression Algorithms: Introduction: Unit 6: Multimedia Data CompressionDocument25 pages6.1 Lossless Compression Algorithms: Introduction: Unit 6: Multimedia Data CompressionSameer ShirhattimathPas encore d'évaluation
- Chap 7Document51 pagesChap 7NAMRA HABIBPas encore d'évaluation
- Dokument - Pub Cardiff University Examination Paper Academic Year Flipbook PDFDocument13 pagesDokument - Pub Cardiff University Examination Paper Academic Year Flipbook PDFالامتحانات السياحةPas encore d'évaluation
- ImageCompression-UNIT-V-students MaterialDocument88 pagesImageCompression-UNIT-V-students MaterialHarika JangamPas encore d'évaluation
- Chapter08 1Document70 pagesChapter08 1Jangwoo YongPas encore d'évaluation
- Mad Unit 3-JntuworldDocument53 pagesMad Unit 3-JntuworldDilip TheLipPas encore d'évaluation
- 09 CM0340 Basic Compression AlgorithmsDocument73 pages09 CM0340 Basic Compression AlgorithmsShobhit JainPas encore d'évaluation
- A Hardware Architecture of A Counter-Based Entropy Coder: Armein Z. R. LangiDocument15 pagesA Hardware Architecture of A Counter-Based Entropy Coder: Armein Z. R. LangiHarryChristiantoPas encore d'évaluation
- Data CompressionDocument22 pagesData CompressionPrachi TrehanPas encore d'évaluation
- Data Compression Practicals VIIII ITDocument49 pagesData Compression Practicals VIIII ITSamyak Mayank ShahPas encore d'évaluation
- 20 CompressionDocument58 pages20 CompressionSudhakar YadavPas encore d'évaluation
- Why Needed?: Without Compression, These Applications Would Not Be FeasibleDocument11 pagesWhy Needed?: Without Compression, These Applications Would Not Be Feasiblesmile00972Pas encore d'évaluation
- Multimedia System (Cse-3230T) Homework: Submitted To: Mr. Yashpal SirDocument6 pagesMultimedia System (Cse-3230T) Homework: Submitted To: Mr. Yashpal SirAnil Singh100% (1)
- Chapter 8-Image CompressionDocument61 pagesChapter 8-Image CompressionAshish GauravPas encore d'évaluation
- Chapter Six 6A ICDocument30 pagesChapter Six 6A ICRobera GetachewPas encore d'évaluation
- Research Paper Coordination BondingDocument11 pagesResearch Paper Coordination BondingSIDHARTH SINHPas encore d'évaluation
- Multmedia StudiesDocument15 pagesMultmedia StudiesDevson SimonPas encore d'évaluation
- Ch8c Data CompressionDocument7 pagesCh8c Data CompressionmuguchialioPas encore d'évaluation
- Cryptography On Indian Languages: Dindayal Mahto Dindayal Mahto MT/IS/1009/10Document52 pagesCryptography On Indian Languages: Dindayal Mahto Dindayal Mahto MT/IS/1009/10bul_mohantyPas encore d'évaluation
- Paul DuraiiDocument8 pagesPaul Duraiipaspatisah9663Pas encore d'évaluation
- Compression IIDocument51 pagesCompression IIJagadeesh NaniPas encore d'évaluation
- Chapter 2 FinalDocument26 pagesChapter 2 FinalRami ReddyPas encore d'évaluation
- Huffman CodingDocument65 pagesHuffman Codingmuhammad_ardiyanPas encore d'évaluation
- HomeworksolutionsDocument6 pagesHomeworksolutionsRass Seyoum100% (1)
- CHP - 10 - Image Compression - Error Free and Lossy Compression MinDocument20 pagesCHP - 10 - Image Compression - Error Free and Lossy Compression Mindetex59086Pas encore d'évaluation
- Assignment No: 02 Title: Huffman AlgorithmDocument7 pagesAssignment No: 02 Title: Huffman AlgorithmtejasPas encore d'évaluation
- Dip 4 Unit NotesDocument10 pagesDip 4 Unit NotesMichael MariamPas encore d'évaluation
- Cour Se or Ient at Ion: Course Description: This Course Is The FirstDocument55 pagesCour Se or Ient at Ion: Course Description: This Course Is The FirstLeonelyn Hermosa Gasco - CosidoPas encore d'évaluation
- CH - 03 Huffman & Extended HuffmanDocument10 pagesCH - 03 Huffman & Extended HuffmanHermandeep KaurPas encore d'évaluation
- DIP Lecture Note - Image CompressionDocument23 pagesDIP Lecture Note - Image Compressiondeeparahul2022Pas encore d'évaluation
- Unit 5 - Data CompressionDocument46 pagesUnit 5 - Data CompressionNezuko KamadoPas encore d'évaluation
- Basics of Information TheoryDocument21 pagesBasics of Information TheoryTanvi SharmaPas encore d'évaluation
- Cryptography ExercisesDocument94 pagesCryptography ExercisesNaru Desu100% (1)
- Coimbatore Sahodaya Set A KeyDocument13 pagesCoimbatore Sahodaya Set A KeySanjay Dani100% (1)
- Presentation 2Document27 pagesPresentation 2GeHad MoheyPas encore d'évaluation
- DIP Image Compression 1.11.2015Document66 pagesDIP Image Compression 1.11.2015LayaPas encore d'évaluation
- 4.2.1. Overview of JPEG: What Is ?Document13 pages4.2.1. Overview of JPEG: What Is ?rekhassePas encore d'évaluation
- Huffman Encoder and Decoder Using VerilogDocument3 pagesHuffman Encoder and Decoder Using VerilogInternational Journal of Application or Innovation in Engineering & ManagementPas encore d'évaluation
- Feistel ProofDocument15 pagesFeistel ProofmaxigisPas encore d'évaluation
- Image Compression (Chapter 8) : CS474/674 - Prof. BebisDocument128 pagesImage Compression (Chapter 8) : CS474/674 - Prof. Bebissrc0108Pas encore d'évaluation
- Practica5 - Resultados Digital SystemsDocument4 pagesPractica5 - Resultados Digital SystemslaramecaPas encore d'évaluation
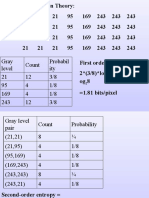
- Gray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8Document51 pagesGray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8kamnakhannaPas encore d'évaluation
- 06 Image CompresssionDocument49 pages06 Image CompresssionAnonymous 3j15irkPas encore d'évaluation
- Data Compression: CS 147 Minh NguyenDocument25 pagesData Compression: CS 147 Minh Nguyenashishj1083Pas encore d'évaluation
- FALLSEM2022-23 CSE4019 ETH VL2022230104728 2022-10-19 Reference-Material-IDocument33 pagesFALLSEM2022-23 CSE4019 ETH VL2022230104728 2022-10-19 Reference-Material-ISRISHTI ACHARYYA 20BCE2561Pas encore d'évaluation
- What Is The Need For Image Compression?Document38 pagesWhat Is The Need For Image Compression?rajeevrajkumarPas encore d'évaluation
- Assembly Programming:Simple, Short, And Straightforward Way Of Learning Assembly LanguageD'EverandAssembly Programming:Simple, Short, And Straightforward Way Of Learning Assembly LanguageÉvaluation : 5 sur 5 étoiles5/5 (1)
- Digital Signal Processing: Instant AccessD'EverandDigital Signal Processing: Instant AccessÉvaluation : 3.5 sur 5 étoiles3.5/5 (2)
- Architecture-Aware Optimization Strategies in Real-time Image ProcessingD'EverandArchitecture-Aware Optimization Strategies in Real-time Image ProcessingPas encore d'évaluation
- Chapter 18 - Content-Based Retrieval in Digital LibrariesDocument66 pagesChapter 18 - Content-Based Retrieval in Digital Librariesa_setiajiPas encore d'évaluation
- Chapter 17 - Wireless NetworksDocument58 pagesChapter 17 - Wireless Networksa_setiajiPas encore d'évaluation
- Chapter 15 - Computer and Multimedia NetworksDocument42 pagesChapter 15 - Computer and Multimedia Networksa_setiajiPas encore d'évaluation
- Chapter 16 - Multimedia Network Communications and ApplicationsDocument68 pagesChapter 16 - Multimedia Network Communications and ApplicationsFarzaan Pardiwala100% (2)
- Chapter 06 - Basics of Digital AudioDocument97 pagesChapter 06 - Basics of Digital Audioa_setiajiPas encore d'évaluation
- CH 8Document84 pagesCH 8Amit BhosalePas encore d'évaluation
- Li Drew Chapter 3 Slides Graphics and Image Data RepresentationDocument46 pagesLi Drew Chapter 3 Slides Graphics and Image Data RepresentationPanagiotis LazarakisPas encore d'évaluation
- Chapter 02 - Multimedia Authoring and ToolsDocument50 pagesChapter 02 - Multimedia Authoring and Toolsa_setiajiPas encore d'évaluation
- MultimediaDocument18 pagesMultimediagurudatha265100% (3)
- QA Chapter5Document7 pagesQA Chapter5Ahmed GamalPas encore d'évaluation
- Cadsoft Eagle 4.16 Rev.2 Help MenuDocument418 pagesCadsoft Eagle 4.16 Rev.2 Help MenulamushkPas encore d'évaluation
- Google Wakeword Detection 1 PDFDocument5 pagesGoogle Wakeword Detection 1 PDFÖzgür Bora GevrekPas encore d'évaluation
- When Good Disks Go BadDocument33 pagesWhen Good Disks Go BadBob2345Pas encore d'évaluation
- Directory: Hc-04 Hc-04-D -04-D 套件Document6 pagesDirectory: Hc-04 Hc-04-D -04-D 套件Dumitru VMPas encore d'évaluation
- GCCDocument452 pagesGCCVijaya KumarPas encore d'évaluation
- EC Council Ehtical Hacking and Contermeasures (CEH) v6Document130 pagesEC Council Ehtical Hacking and Contermeasures (CEH) v6Adam Dhori'unPas encore d'évaluation
- Computer GenerationsDocument14 pagesComputer GenerationsAfsanaKhanPas encore d'évaluation
- Proteus ModesDocument4 pagesProteus Modesnas111Pas encore d'évaluation
- Ai Complete NotesDocument98 pagesAi Complete NotesjayjayjayendraPas encore d'évaluation
- ATM Use CasesDocument5 pagesATM Use CasesWanda AlexanderPas encore d'évaluation
- 1C - Dual Simplex & Post Optimal AnalysisDocument34 pages1C - Dual Simplex & Post Optimal AnalysisSajal AgarwalPas encore d'évaluation
- READMEDocument5 pagesREADMEAshwin KumarPas encore d'évaluation
- Dda Line Drawing AlgorithmDocument2 pagesDda Line Drawing AlgorithmAlok DubeyPas encore d'évaluation
- Distributed Database SystemDocument6 pagesDistributed Database SystemMyHouseATLPas encore d'évaluation
- FT Adb Launcher LogDocument146 pagesFT Adb Launcher LogBojan VucevskiPas encore d'évaluation
- Subject Name:oracle Part: PLSQL:: Chapter OneDocument12 pagesSubject Name:oracle Part: PLSQL:: Chapter OneAbdirahman HassanPas encore d'évaluation
- Game Playing in Artificial IntelligenceDocument17 pagesGame Playing in Artificial IntelligencePraveen KumarPas encore d'évaluation
- C KRDocument382 pagesC KRdeepaksiddPas encore d'évaluation
- FortiGate Security Instructor GuideDocument13 pagesFortiGate Security Instructor GuideAlonso RiveraPas encore d'évaluation
- HP Imp Msa Storage Sol StudentguideDocument304 pagesHP Imp Msa Storage Sol StudentguidePavan KamishettiPas encore d'évaluation
- Manual TestingDocument11 pagesManual TestingsachinPas encore d'évaluation
- Whitney P Lewis ResumeDocument2 pagesWhitney P Lewis Resumeapi-254661283Pas encore d'évaluation
- Markov Based Quality Metrics For Generating Structured Music With Optimization TechniquesDocument1 pageMarkov Based Quality Metrics For Generating Structured Music With Optimization TechniquesDorien HerremansPas encore d'évaluation
- Flowchart Vs Data Flow DiagramDocument2 pagesFlowchart Vs Data Flow DiagramPrabha PanayalPas encore d'évaluation
- System Messages CSC-W32 V2.0 - 53Document746 pagesSystem Messages CSC-W32 V2.0 - 53Carlos R. VergaraPas encore d'évaluation
- Assignment Questions: Module - 1 Application LayerDocument2 pagesAssignment Questions: Module - 1 Application LayerNaveen SettyPas encore d'évaluation
- Virtual Screen SaverDocument15 pagesVirtual Screen SaverM.Saad SiddiquiPas encore d'évaluation
- Using LDAP To Manage UsersDocument57 pagesUsing LDAP To Manage UsersAlex Aeron50% (2)
- Computer ScienceDocument58 pagesComputer SciencepajadhavPas encore d'évaluation