Vous aimerez peut-être aussi
- Getting Started With HadoopDocument47 pagesGetting Started With HadoopTeeMan27Pas encore d'évaluation
- Cloudera Developer TrainingDocument593 pagesCloudera Developer Trainingdatadisk1089% (9)
- Apache Spark TutorialDocument6 pagesApache Spark Tutorialabhimanyu thakur100% (1)
- Hadoop Installation CommandsDocument3 pagesHadoop Installation CommandssiddheshPas encore d'évaluation
- Informix 4GL InfoDocument11 pagesInformix 4GL Infoanon_243945930Pas encore d'évaluation
- Guided By:: Miss. Rupali ZambreDocument20 pagesGuided By:: Miss. Rupali ZambrejohnPas encore d'évaluation
- Guided By:: Miss. Rupali ZambreDocument20 pagesGuided By:: Miss. Rupali ZambrejohnPas encore d'évaluation
- Apache Hive TutorialDocument139 pagesApache Hive TutorialnagalakshmiPas encore d'évaluation
- Hive Main InstallationDocument2 pagesHive Main InstallationpareekPas encore d'évaluation
- MongoDB for Jobseekers: Reach new heights in your career with MongoDB (English Edition)D'EverandMongoDB for Jobseekers: Reach new heights in your career with MongoDB (English Edition)Pas encore d'évaluation
- Hadoop and Related ToolsDocument57 pagesHadoop and Related ToolsPrem PrasadPas encore d'évaluation
- Getting Started with Big Data Query using Apache ImpalaD'EverandGetting Started with Big Data Query using Apache ImpalaPas encore d'évaluation
- HadoopDocument34 pagesHadoopforjunklikescribdPas encore d'évaluation
- Ibm Big Insights For AnalystsDocument28 pagesIbm Big Insights For AnalystschandubabuPas encore d'évaluation
- Apache CassandraDocument3 pagesApache CassandrashikhanirankariPas encore d'évaluation
- Hadoop InstallationDocument13 pagesHadoop Installationamp1279Pas encore d'évaluation
- DS Toolbox DataScienceGeniusDocument1 pageDS Toolbox DataScienceGeniusSandeep SaurabhPas encore d'évaluation
- Hive Using HiveqlDocument38 pagesHive Using HiveqlsulochanaPas encore d'évaluation
- Cloudera Administration Handbook Sample ChapterDocument22 pagesCloudera Administration Handbook Sample ChapterPackt PublishingPas encore d'évaluation
- MongoDB TutorialDocument4 pagesMongoDB TutoriallearnwithvideotutorialsPas encore d'évaluation
- Hadoop Security S360 2015v8 PDFDocument27 pagesHadoop Security S360 2015v8 PDFLuis Demetrio Martinez RuizPas encore d'évaluation
- Deepak Sanagapalli Uuupdated ResumeDocument8 pagesDeepak Sanagapalli Uuupdated ResumeRohit LalwaniPas encore d'évaluation
- KubernetesDocument27 pagesKubernetesJason GomezPas encore d'évaluation
- YARN - MapReduceDocument34 pagesYARN - MapReduceYashu SagarPas encore d'évaluation
- Big Data and Hadoop: by - Ujjwal Kumar GuptaDocument57 pagesBig Data and Hadoop: by - Ujjwal Kumar GuptaUjjwal Kumar GuptaPas encore d'évaluation
- Apache Hue-ClouderaDocument63 pagesApache Hue-ClouderaDheepikaPas encore d'évaluation
- Logstash V1.4.1getting StartedDocument9 pagesLogstash V1.4.1getting StartedAnonymous taUuBikPas encore d'évaluation
- Hadoop Admin Interview Question and AnswersDocument5 pagesHadoop Admin Interview Question and AnswersVivek KushwahaPas encore d'évaluation
- Apache Pig: For Live Hadoop Training, Please See CoursesDocument25 pagesApache Pig: For Live Hadoop Training, Please See CoursesAlmasePas encore d'évaluation
- Big Data and Spark DevelopersDocument5 pagesBig Data and Spark DevelopersBalaji ArunPas encore d'évaluation
- Hadoop For Windows Succinctly PDFDocument148 pagesHadoop For Windows Succinctly PDFDat Nguyen HoangPas encore d'évaluation
- Session 12 MonitoringDocument23 pagesSession 12 MonitoringDipesh JPas encore d'évaluation
- The 25-Year History of SOADocument8 pagesThe 25-Year History of SOADornala Maanasa ReddyPas encore d'évaluation
- 049 Hadoop Commands Reference Guide.Document3 pages049 Hadoop Commands Reference Guide.vaasu1Pas encore d'évaluation
- Ambari Installation Guide PDFDocument54 pagesAmbari Installation Guide PDFKishor pPas encore d'évaluation
- LearningSpark EXCERPTDocument47 pagesLearningSpark EXCERPTAmarilis Gabriela Loor Zambrano0% (1)
- Introduction To Hadoop & SparkDocument28 pagesIntroduction To Hadoop & SparkJustin TalbotPas encore d'évaluation
- Next-Generation Python Big Data Tools, Powered by Apache ArrowDocument22 pagesNext-Generation Python Big Data Tools, Powered by Apache Arrowagrygoruk100% (1)
- Hadoop Training #4: Programming With HadoopDocument46 pagesHadoop Training #4: Programming With HadoopDmytro Shteflyuk100% (2)
- 16 SparkAlgorithmsDocument57 pages16 SparkAlgorithmsPetter P0% (1)
- HDFS Encryption Zone Hive OrigDocument47 pagesHDFS Encryption Zone Hive OrigshyamsunderraiPas encore d'évaluation
- Bigdata With PythonDocument19 pagesBigdata With PythonAmrit ChhetribPas encore d'évaluation
- SAS Hadoop KerberosDocument27 pagesSAS Hadoop KerberosshilpaPas encore d'évaluation
- 2016 05 10 Apache Nifi Deep Dive 160511170654Document34 pages2016 05 10 Apache Nifi Deep Dive 160511170654Shyam BabuPas encore d'évaluation
- LinuxCon Introduction To CloudStackDocument34 pagesLinuxCon Introduction To CloudStackLasantha JayasinghePas encore d'évaluation
- Accessing Data: Center of Excellence Data WarehousingDocument108 pagesAccessing Data: Center of Excellence Data WarehousingbalajivangaruPas encore d'évaluation
- BIG DATA & Hadoop Interview Questions With AnswersDocument9 pagesBIG DATA & Hadoop Interview Questions With AnswersMikky JamesPas encore d'évaluation
- Facebook Hive POCDocument18 pagesFacebook Hive POCJayashree RaviPas encore d'évaluation
- Hadoop NotesDocument11 pagesHadoop NotesVijay Vishwanath ThombarePas encore d'évaluation
- QualityThought Azure SnowFlake - Data Engineer 2022Document6 pagesQualityThought Azure SnowFlake - Data Engineer 2022rockineverPas encore d'évaluation
- QualityThought Tableau 2022-1Document4 pagesQualityThought Tableau 2022-1rockineverPas encore d'évaluation
- QualityThought Sales-Force 2022Document6 pagesQualityThought Sales-Force 2022rockineverPas encore d'évaluation
- Lamda 2Document1 pageLamda 2rockineverPas encore d'évaluation
- Filter - This Is A Python Inbuilt Library That Returns Only ThoseDocument4 pagesFilter - This Is A Python Inbuilt Library That Returns Only ThoserockineverPas encore d'évaluation
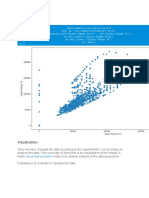
- Scatterplot: VisualizationDocument6 pagesScatterplot: VisualizationrockineverPas encore d'évaluation
- Lamda 1Document1 pageLamda 1rockineverPas encore d'évaluation
- H1B Checklist 2022Document2 pagesH1B Checklist 2022rockineverPas encore d'évaluation
- CPAT Blocker QueriesDocument5 pagesCPAT Blocker QueriesrockineverPas encore d'évaluation
- Python Anaconda Tutorial: Everything You Need To KnowDocument13 pagesPython Anaconda Tutorial: Everything You Need To KnowrockineverPas encore d'évaluation
- Introduction To Anaconda: Data Science Machine Learning Deep LearningDocument6 pagesIntroduction To Anaconda: Data Science Machine Learning Deep LearningrockineverPas encore d'évaluation
- Sand Box Management: Sandboxes Are Enabled by MDS Reprositroy, Where All The Extenstions Are Stored and ManagedDocument4 pagesSand Box Management: Sandboxes Are Enabled by MDS Reprositroy, Where All The Extenstions Are Stored and ManagedrockineverPas encore d'évaluation
- DRM HTTP Load BalancingDocument1 pageDRM HTTP Load BalancingrockineverPas encore d'évaluation
- CERTIFIED/LICENSED SNORKEL GUIDES BY National Institute of Water Sports (NIWS), Goa List of Port Blair / Rangat / Baratang / Diglipur / Neil IslandDocument3 pagesCERTIFIED/LICENSED SNORKEL GUIDES BY National Institute of Water Sports (NIWS), Goa List of Port Blair / Rangat / Baratang / Diglipur / Neil IslandrockineverPas encore d'évaluation
- Part 1 - Oracle SOA Interview Questions (Basic) : Q1. What Is SOA and Explain Its Architectural Benefits?Document6 pagesPart 1 - Oracle SOA Interview Questions (Basic) : Q1. What Is SOA and Explain Its Architectural Benefits?rockineverPas encore d'évaluation
- Oracle Weblogic Server 11G Standard Edition: Key Features and BenefitsDocument4 pagesOracle Weblogic Server 11G Standard Edition: Key Features and BenefitsrockineverPas encore d'évaluation
- What Is OID?: Oracle Internet Directory (OID) 11g: Part II - Requirements and ComponentsDocument3 pagesWhat Is OID?: Oracle Internet Directory (OID) 11g: Part II - Requirements and ComponentsrockineverPas encore d'évaluation
- Essex CelDocument278 pagesEssex CelrockineverPas encore d'évaluation
- Oracle Epm at Oracle 1515594Document21 pagesOracle Epm at Oracle 1515594rockineverPas encore d'évaluation
- Expanded Functionality: Provides Master Data Management For Charts ofDocument1 pageExpanded Functionality: Provides Master Data Management For Charts ofrockineverPas encore d'évaluation