Vous aimerez peut-être aussi
- Python For Finance PDFDocument28 pagesPython For Finance PDFDiego Mendes0% (1)
- VX Python For Finance EuroScipy 2012 Y HilpischDocument47 pagesVX Python For Finance EuroScipy 2012 Y HilpischMohamed HussienPas encore d'évaluation
- Risk Neutral Pricing and Financial Mathematics: A PrimerD'EverandRisk Neutral Pricing and Financial Mathematics: A PrimerPas encore d'évaluation
- Y Hilpisch Derivatives Analytics ExcerptDocument37 pagesY Hilpisch Derivatives Analytics Excerptfdvdd100% (1)
- Forecasting Volatility in the Financial MarketsD'EverandForecasting Volatility in the Financial MarketsÉvaluation : 4 sur 5 étoiles4/5 (1)
- Algorithmic TradingDocument10 pagesAlgorithmic TradingGustavo Silva0% (2)
- Mastering Python For Finance - Sample ChapterDocument24 pagesMastering Python For Finance - Sample ChapterPackt Publishing100% (3)
- Basic Python in Finance: How to Implement Financial Trading Strategies and Analysis using PythonD'EverandBasic Python in Finance: How to Implement Financial Trading Strategies and Analysis using PythonÉvaluation : 5 sur 5 étoiles5/5 (9)
- A Short Guide On Automated Execution of Trades 2watermarkDocument13 pagesA Short Guide On Automated Execution of Trades 2watermarksukeerthiPas encore d'évaluation
- An Automated FX Trading System Using Adaptive Reinforcement LearningDocument10 pagesAn Automated FX Trading System Using Adaptive Reinforcement LearningDiajeng PermataPas encore d'évaluation
- Building Automated Trading Systems: With an Introduction to Visual C++.NET 2005D'EverandBuilding Automated Trading Systems: With an Introduction to Visual C++.NET 2005Évaluation : 4 sur 5 étoiles4/5 (2)
- Machine Learning For Factor Investing Python Version 9780367639747 9780367639723 9781003121596 2023002044 - CompressDocument358 pagesMachine Learning For Factor Investing Python Version 9780367639747 9780367639723 9781003121596 2023002044 - CompressmiarovyiPas encore d'évaluation
- Algorithmic Trading Methods: Applications Using Advanced Statistics, Optimization, and Machine Learning TechniquesD'EverandAlgorithmic Trading Methods: Applications Using Advanced Statistics, Optimization, and Machine Learning TechniquesPas encore d'évaluation
- Machine Learning in Finance From Theory To PDFDocument22 pagesMachine Learning in Finance From Theory To PDFalPas encore d'évaluation
- Designing Stock Market Trading Systems: With and without soft computingD'EverandDesigning Stock Market Trading Systems: With and without soft computingPas encore d'évaluation
- Python For Finance Course Notes PDFDocument35 pagesPython For Finance Course Notes PDFMuhammad ZohaibPas encore d'évaluation
- Mastering Python for Finance - Second Edition: Implement advanced state-of-the-art financial statistical applications using Python, 2nd EditionD'EverandMastering Python for Finance - Second Edition: Implement advanced state-of-the-art financial statistical applications using Python, 2nd EditionÉvaluation : 4 sur 5 étoiles4/5 (3)
- The Top 21 Python Trading Tools For 2020 - Analyzing AlphaDocument28 pagesThe Top 21 Python Trading Tools For 2020 - Analyzing AlphaJose Carlos Sierra CiudadPas encore d'évaluation
- Python for Finance Cookbook: Over 50 recipes for applying modern Python libraries to financial data analysisD'EverandPython for Finance Cookbook: Over 50 recipes for applying modern Python libraries to financial data analysisPas encore d'évaluation
- Quant TradingDocument20 pagesQuant TradingChristopher M. PattenPas encore d'évaluation
- Neural Networks in Finance: Gaining Predictive Edge in the MarketD'EverandNeural Networks in Finance: Gaining Predictive Edge in the MarketÉvaluation : 3.5 sur 5 étoiles3.5/5 (3)
- Tutorials Finance Python TradingDocument71 pagesTutorials Finance Python TradingLuis Andrés Muñoz Mercado100% (2)
- Python For Quants.Document4 pagesPython For Quants.Alex PinteaPas encore d'évaluation
- The Microstructure Approach To Exchange RatesDocument346 pagesThe Microstructure Approach To Exchange RatesKulbir SinghPas encore d'évaluation
- An Introduction To Serious Algorithmic TradingDocument40 pagesAn Introduction To Serious Algorithmic TradingJorge Luis67% (3)
- Mastering Pandas For Finance - Sample ChapterDocument42 pagesMastering Pandas For Finance - Sample ChapterPackt Publishing100% (2)
- Machine Learning in Finance: Matthew F. Dixon Igor Halperin Paul BilokonDocument565 pagesMachine Learning in Finance: Matthew F. Dixon Igor Halperin Paul BilokonKumar Manoj67% (6)
- Derivatives Analytics With Python Numpy PDFDocument34 pagesDerivatives Analytics With Python Numpy PDFAndre AmorimPas encore d'évaluation
- Algorithmic Trading :buy Side HandbookDocument32 pagesAlgorithmic Trading :buy Side Handbookbettyflo29100% (1)
- Derivatives Pricing Using QuantLib - An IntroductionDocument25 pagesDerivatives Pricing Using QuantLib - An Introductionvicky.sajnaniPas encore d'évaluation
- Honing An Algorithmic Trading StrategyDocument21 pagesHoning An Algorithmic Trading Strategyameetsonavane100% (4)
- Quantitative Trading As A Mathematical Science: Quantcon Singapore 2016Document54 pagesQuantitative Trading As A Mathematical Science: Quantcon Singapore 2016Kofi Appiah-DanquahPas encore d'évaluation
- Pairs Trading: A Statistical Arbitrage StrategyDocument21 pagesPairs Trading: A Statistical Arbitrage StrategyKeshav SehgalPas encore d'évaluation
- Python For TradingDocument47 pagesPython For Tradingdzavkec100% (2)
- Dynamic Asset Allocation For Varied Financial Markets Under Regime Switching FrameworkDocument9 pagesDynamic Asset Allocation For Varied Financial Markets Under Regime Switching FrameworkFarhan SarwarPas encore d'évaluation
- Algorithmic Trading Using Reinforcement Learning Augmented With Hidden Markov ModelDocument10 pagesAlgorithmic Trading Using Reinforcement Learning Augmented With Hidden Markov ModelTutor World OnlinePas encore d'évaluation
- QuantinstiDocument2 pagesQuantinstiAnirudh ParuiPas encore d'évaluation
- Machine TradingDocument17 pagesMachine TradingRicardo Gerhardt0% (1)
- Burgess PHD Thesis - A Computational Methodology For Modelling The Dynamics of Statistical ArbitrageDocument370 pagesBurgess PHD Thesis - A Computational Methodology For Modelling The Dynamics of Statistical ArbitragemaynaazePas encore d'évaluation
- KDB ManualDocument189 pagesKDB Manualiallika71Pas encore d'évaluation
- Quantitative Trading and BacktestingDocument23 pagesQuantitative Trading and Backtestingalexa_sherpy100% (3)
- The Myth and Reality of Financial Machine Learning by Marcos López de Prado PDFDocument33 pagesThe Myth and Reality of Financial Machine Learning by Marcos López de Prado PDFSau L.Pas encore d'évaluation
- Fractals in Finance and RiskDocument14 pagesFractals in Finance and Riskcatwalktoiim100% (1)
- Github Com Grananqvist Awesome Quant Machine Learning Trading PDFDocument7 pagesGithub Com Grananqvist Awesome Quant Machine Learning Trading PDFBartek SPas encore d'évaluation
- Monte Carlo Methods in Financial Engineering Paul Glasserman 2004Document615 pagesMonte Carlo Methods in Financial Engineering Paul Glasserman 2004tomk2220100% (3)
- Py FiDocument17 pagesPy FiShuvamPas encore d'évaluation
- 1、On Becoming A Quant 2、The Essential Algorithmic Trading Reading List 3、The Self-Study Guide To Becoming A Quantitative Trader 4、Quantstart LessonsDocument87 pages1、On Becoming A Quant 2、The Essential Algorithmic Trading Reading List 3、The Self-Study Guide To Becoming A Quantitative Trader 4、Quantstart LessonsSuperquant100% (4)
- KEY - Resources - Roadmap3 - Quant Algo Trading Systems Coding Tradingview $SPX $NQ - F $ES - F Start HereDocument21 pagesKEY - Resources - Roadmap3 - Quant Algo Trading Systems Coding Tradingview $SPX $NQ - F $ES - F Start HereNataliaPas encore d'évaluation
- Finance With Python and MPTDocument31 pagesFinance With Python and MPTravinysePas encore d'évaluation
- High Frequency Trading - Shawn DurraniDocument49 pagesHigh Frequency Trading - Shawn DurraniShawnDurraniPas encore d'évaluation
- Machine Learning For Algorithmic TradingDocument302 pagesMachine Learning For Algorithmic TradingyoyoksdPas encore d'évaluation
- Market MakingDocument7 pagesMarket MakingLukash KotatkoPas encore d'évaluation
- Price Trailing For Financial Trading Using Deep Reinforcement LearningDocument10 pagesPrice Trailing For Financial Trading Using Deep Reinforcement LearningNAGA KUMARI ODUGUPas encore d'évaluation
- Free Quant ResourcesDocument6 pagesFree Quant ResourcesKaustubh Keskar100% (2)
- Quantra Machine Learning Ebook PDFDocument17 pagesQuantra Machine Learning Ebook PDFAlex VzquZPas encore d'évaluation
- 1.3. Types of Computer NetworksDocument10 pages1.3. Types of Computer NetworksJUGRAJ SINGHPas encore d'évaluation
- 802 - Information - Technology - MS (3) - 231223 - 091112Document7 pages802 - Information - Technology - MS (3) - 231223 - 091112manmarvellous1337Pas encore d'évaluation
- KPLC DistributionDocument598 pagesKPLC DistributionRahabGathoni50% (2)
- Advance Excel Course Notes CompleteDocument58 pagesAdvance Excel Course Notes CompleteAbhishek Motiram JagtapPas encore d'évaluation
- FTTHDocument9 pagesFTTHAnadi GuptaPas encore d'évaluation
- Sayon Dutta - Reinforcement Learning With TensorFlow - A Beginner's Guide To Designing Self-Learning Systems With TensorFlow and OpenAI Gym-Packt Publishing (2018)Document327 pagesSayon Dutta - Reinforcement Learning With TensorFlow - A Beginner's Guide To Designing Self-Learning Systems With TensorFlow and OpenAI Gym-Packt Publishing (2018)Akshit Bhalla100% (3)
- Grade 6 PPT Math q4 w4Document18 pagesGrade 6 PPT Math q4 w4Cristal Iba?zPas encore d'évaluation
- Wind Speed Modelling Using Inverse Weibull Distrubition - A Case Study For B - Lec - K, Turkey (#299493) - 285602Document5 pagesWind Speed Modelling Using Inverse Weibull Distrubition - A Case Study For B - Lec - K, Turkey (#299493) - 285602CherinetPas encore d'évaluation
- Gorm Day2Document45 pagesGorm Day2Ryan SmithPas encore d'évaluation
- Ficha Tecnica SX10Document7 pagesFicha Tecnica SX10José CamachoPas encore d'évaluation
- Globalization Syllabus S22Document11 pagesGlobalization Syllabus S22Manit ShahPas encore d'évaluation
- BAS1303 White Paper Interface Comparsion eDocument5 pagesBAS1303 White Paper Interface Comparsion eIndraPas encore d'évaluation
- Design of Library Management SystemDocument8 pagesDesign of Library Management SystemSasi KumarPas encore d'évaluation
- AS400 Questions SDocument21 pagesAS400 Questions SNaveen SaharanPas encore d'évaluation
- Branding LP 1st Quarter TLE ICT 10Document6 pagesBranding LP 1st Quarter TLE ICT 10LEONEL RIVASPas encore d'évaluation
- Alu - 7368 Isam Ont G-240w-b InfoDocument7 pagesAlu - 7368 Isam Ont G-240w-b InfodcooverPas encore d'évaluation
- UAV-based GIS/Remote Sensing For Civilian Applications & Disaster ManagementDocument53 pagesUAV-based GIS/Remote Sensing For Civilian Applications & Disaster ManagementMyo Myint AungPas encore d'évaluation
- As ISO 9918-2004 Capnometers For Use With Humans - RequirementsDocument10 pagesAs ISO 9918-2004 Capnometers For Use With Humans - RequirementsSAI Global - APACPas encore d'évaluation
- Godzilla VS. Kong (2021) Movie ScriptDocument5 pagesGodzilla VS. Kong (2021) Movie ScriptlucasPas encore d'évaluation
- Kumbharana CK Thesis CsDocument243 pagesKumbharana CK Thesis CsYadu KrishnanPas encore d'évaluation
- PPP Feature Config Guide Rev CDocument29 pagesPPP Feature Config Guide Rev CSai Kyaw HtikePas encore d'évaluation
- Minh Nguyen ResumeDocument2 pagesMinh Nguyen Resumeapi-537841053Pas encore d'évaluation
- IPCR Part 2 2017Document4 pagesIPCR Part 2 2017RommelPas encore d'évaluation
- 10 1109@IoT-SIU 2019 8777722 PDFDocument6 pages10 1109@IoT-SIU 2019 8777722 PDFAkshay KumarPas encore d'évaluation
- PlainSight BTCDocument11 pagesPlainSight BTCMidnight Hacker100% (1)
- Patch NotesDocument8 pagesPatch Notesradijet07Pas encore d'évaluation
- Application of ICT and BIM For Implementation of Building ByelawsDocument41 pagesApplication of ICT and BIM For Implementation of Building ByelawsAyesha MalikPas encore d'évaluation
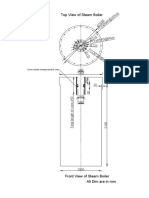
- Top View of Steam Boiler: PCDØ270@6NosDocument1 pageTop View of Steam Boiler: PCDØ270@6NosAnkur SinghPas encore d'évaluation
- NokiaDocument11 pagesNokiaAnonymous pU4X5VSuTfPas encore d'évaluation
- SpringBoot All ProgramsDocument16 pagesSpringBoot All ProgramsHitesh WadhwaniPas encore d'évaluation