Vous aimerez peut-être aussi
- Chan Jeliazkov 2009Document20 pagesChan Jeliazkov 2009sommukhPas encore d'évaluation
- Research Reports Mdh/Ima No. 2007-4, Issn 1404-4978: Date Key Words and PhrasesDocument16 pagesResearch Reports Mdh/Ima No. 2007-4, Issn 1404-4978: Date Key Words and PhrasesEduardo Salgado EnríquezPas encore d'évaluation
- The Use of Genetic Algorithms in Finite Element Model IdentificationDocument8 pagesThe Use of Genetic Algorithms in Finite Element Model IdentificationMilena PopovicPas encore d'évaluation
- King Et Al-2021-Nature CommunicationsDocument6 pagesKing Et Al-2021-Nature CommunicationsSteve KingPas encore d'évaluation
- Expert Systems With Applications: Jing Xiao, Yuping Yan, Jun Zhang, Yong TangDocument8 pagesExpert Systems With Applications: Jing Xiao, Yuping Yan, Jun Zhang, Yong TangmallajosyulasivaniPas encore d'évaluation
- Abstracts MonteCarloMethodsDocument4 pagesAbstracts MonteCarloMethodslib_01Pas encore d'évaluation
- An E!cient O"-Line Formulation of Robust Model Predictive Control Using Linear Matrix InequalitiesDocument10 pagesAn E!cient O"-Line Formulation of Robust Model Predictive Control Using Linear Matrix InequalitiesRavi VermaPas encore d'évaluation
- Genetic Algorithm in MATLABDocument15 pagesGenetic Algorithm in MATLABAlejito CuzcoPas encore d'évaluation
- Pattern Rrecognition 2Document7 pagesPattern Rrecognition 2Tejinder SinghPas encore d'évaluation
- Linear Feedback ControlDocument14 pagesLinear Feedback ControlHung TuanPas encore d'évaluation
- Efficient Equalization MethodDocument4 pagesEfficient Equalization MethodAntonio Newton Licciardi JuniorPas encore d'évaluation
- Intro To QMLand QNNDocument13 pagesIntro To QMLand QNNSeyyed Adnan SeyyedyPas encore d'évaluation
- 02 Efficient Characterization of The Random Eigenvalue Problem inDocument19 pages02 Efficient Characterization of The Random Eigenvalue Problem inJRPas encore d'évaluation
- Feed-Forward Neural Networks Regressions With Genetic Algorithms - Applications in Econometrics and FinanceDocument25 pagesFeed-Forward Neural Networks Regressions With Genetic Algorithms - Applications in Econometrics and Financenwesterhuijsgmail.comPas encore d'évaluation
- 18 Aos1715Document33 pages18 Aos1715aprilvee1222Pas encore d'évaluation
- Matlab GaDocument15 pagesMatlab Gagreenday3Pas encore d'évaluation
- TSP Cmes 41283Document25 pagesTSP Cmes 41283ranim najibPas encore d'évaluation
- Probabilistic Optimal Flow: PowerDocument4 pagesProbabilistic Optimal Flow: Powerrokhgireh_hojjatPas encore d'évaluation
- Machine Learning and AIDocument10 pagesMachine Learning and AIsmedixonPas encore d'évaluation
- RadevDocument3 pagesRadevIrenataPas encore d'évaluation
- Stabilization Methods For The Integration of DAE in The Presence of Redundant ConstraintsDocument25 pagesStabilization Methods For The Integration of DAE in The Presence of Redundant ConstraintsChernet TugePas encore d'évaluation
- Sliding Mode Control Based On Genetic Algorithm For WSCC Systems Include of SVCDocument6 pagesSliding Mode Control Based On Genetic Algorithm For WSCC Systems Include of SVCmenguemenguePas encore d'évaluation
- InTech-Quantum Cellular Automata Controlled Self Organizing NetworksDocument40 pagesInTech-Quantum Cellular Automata Controlled Self Organizing NetworksSunil KumarPas encore d'évaluation
- Classification With Quantum Machine Learning: A Survey: 1 - IntroductionDocument16 pagesClassification With Quantum Machine Learning: A Survey: 1 - IntroductionArtūrs PriedītisPas encore d'évaluation
- A Weighted GCV Method For Lanczos Hybrid Regularization (PDFDrive)Document19 pagesA Weighted GCV Method For Lanczos Hybrid Regularization (PDFDrive)anahh ramakPas encore d'évaluation
- Steady-State and Transient Probabilities Calculation For Engineering ModelsDocument11 pagesSteady-State and Transient Probabilities Calculation For Engineering ModelsinventionjournalsPas encore d'évaluation
- Efficient Simulation and Integrated Likelihood TVP VarDocument20 pagesEfficient Simulation and Integrated Likelihood TVP VarazertyPas encore d'évaluation
- Learning Algorithm and Application of Quantum BP Neural Networks Based On Universal Quantum GatesDocument8 pagesLearning Algorithm and Application of Quantum BP Neural Networks Based On Universal Quantum Gateshassan safi nezhadPas encore d'évaluation
- Provable Compressed Sensing Quantum State Tomography Via Non-Convex MethodsDocument7 pagesProvable Compressed Sensing Quantum State Tomography Via Non-Convex MethodsGalleta Galleta MetralletaPas encore d'évaluation
- Ad Pap 1Document6 pagesAd Pap 1Riccardo MathisPas encore d'évaluation
- Intelligent Simulation of Multibody Dynamics: Space-State and Descriptor Methods in Sequential and Parallel Computing EnvironmentsDocument19 pagesIntelligent Simulation of Multibody Dynamics: Space-State and Descriptor Methods in Sequential and Parallel Computing EnvironmentsChernet TugePas encore d'évaluation
- 2003 CaoDocument21 pages2003 Caomehmet gezerPas encore d'évaluation
- 09 Ba402Document22 pages09 Ba402shabaazkurmally.um1Pas encore d'évaluation
- Monte Carlo - SubhadipDocument34 pagesMonte Carlo - SubhadipIndra Prakash JhaPas encore d'évaluation
- Sequence Space JacobianDocument84 pagesSequence Space JacobianStan ChrisinskyPas encore d'évaluation
- Deep Boltzmann MachinesDocument8 pagesDeep Boltzmann MachinessitukangsayurPas encore d'évaluation
- Approximate Linear Programming For Network Control: Column Generation and SubproblemsDocument20 pagesApproximate Linear Programming For Network Control: Column Generation and SubproblemsPervez AhmadPas encore d'évaluation
- A N: Vmiranda@porto - Inescn.pt: Muanda J. Da Fax: 351.2.318692Document7 pagesA N: Vmiranda@porto - Inescn.pt: Muanda J. Da Fax: 351.2.318692joonie5Pas encore d'évaluation
- Sat ConversionDocument14 pagesSat Conversion18090wwPas encore d'évaluation
- SQ PreviewDocument63 pagesSQ PreviewAlneo LesagPas encore d'évaluation
- 10 1 1 87 2049 PDFDocument23 pages10 1 1 87 2049 PDFPatrick MugoPas encore d'évaluation
- Lifted Collocation Integrators For Direct Optimal Control in ACADO ToolkitDocument45 pagesLifted Collocation Integrators For Direct Optimal Control in ACADO ToolkitRAHMANI NASR-EDDINEPas encore d'évaluation
- Chaos Updating Rotated Gates Quantum-Inspired Genetic AlgorithmDocument5 pagesChaos Updating Rotated Gates Quantum-Inspired Genetic AlgorithmRobert MaximilianPas encore d'évaluation
- Problematica: Que Son Los GADocument4 pagesProblematica: Que Son Los GAsiddmonPas encore d'évaluation
- Michail Zak and Colin P. Williams - Quantum Neural NetsDocument48 pagesMichail Zak and Colin P. Williams - Quantum Neural Netsdcsi3Pas encore d'évaluation
- Model-Free Reinforcement Learning of Minimal-Cost Variance ControlDocument6 pagesModel-Free Reinforcement Learning of Minimal-Cost Variance ControlVrushabh DongePas encore d'évaluation
- Final Project ReportDocument18 pagesFinal Project ReportjstpallavPas encore d'évaluation
- Kalman Filtering With Intermittent Observations: Abstract-Motivated by Navigation and Tracking ApplicationsDocument12 pagesKalman Filtering With Intermittent Observations: Abstract-Motivated by Navigation and Tracking Applicationsdebasishmee5808Pas encore d'évaluation
- Quantum Informatics View of Statistical Data Processing: Yu. I. Bogdanov, N. A. BogdanovaDocument7 pagesQuantum Informatics View of Statistical Data Processing: Yu. I. Bogdanov, N. A. BogdanovaLouis DavisPas encore d'évaluation
- Mathematical Programming For Piecewise Linear Regression AnalysisDocument43 pagesMathematical Programming For Piecewise Linear Regression AnalysishongxinPas encore d'évaluation
- Bacry-kozhemyak-muzy-2008-Log Normal Continuous Cascades Aggregation Properties and Estimation-Applications To Financial Time SeriesDocument27 pagesBacry-kozhemyak-muzy-2008-Log Normal Continuous Cascades Aggregation Properties and Estimation-Applications To Financial Time SeriesReiner_089Pas encore d'évaluation
- Hybrid Genetic Algorithm Based On Quantum Computing For Numerical Optimization and Parameter EstimationDocument16 pagesHybrid Genetic Algorithm Based On Quantum Computing For Numerical Optimization and Parameter EstimationRobert MaximilianPas encore d'évaluation
- Tensor Decompositions For Learning Latent Variable Models: Mtelgars@cs - Ucsd.eduDocument54 pagesTensor Decompositions For Learning Latent Variable Models: Mtelgars@cs - Ucsd.eduJohn KirkPas encore d'évaluation
- Algoritmos GenéticosDocument10 pagesAlgoritmos GenéticosErick VegaPas encore d'évaluation
- Finite-Time H Filtering of Time-Delay Stochastic Jump Systems With Unbiased EstimationDocument13 pagesFinite-Time H Filtering of Time-Delay Stochastic Jump Systems With Unbiased EstimationKarima ChakerPas encore d'évaluation
- Tutorial: Topic: Finite Element Model Updating Speaker: Wen-Wei LinDocument8 pagesTutorial: Topic: Finite Element Model Updating Speaker: Wen-Wei LinlawfulPas encore d'évaluation
- Parallel Implementation of Divide-and-Conquer Semiempirical Quantum Chemistry CalculationsDocument9 pagesParallel Implementation of Divide-and-Conquer Semiempirical Quantum Chemistry Calculationssepot24093Pas encore d'évaluation
- Multiple Models Approach in Automation: Takagi-Sugeno Fuzzy SystemsD'EverandMultiple Models Approach in Automation: Takagi-Sugeno Fuzzy SystemsPas encore d'évaluation
- TESTDocument1 pageTESTsheetal tanejaPas encore d'évaluation
- Solutions in Multimedia and Hypertext. (P. 21-30) Eds.: Susan Stone and MichaelDocument15 pagesSolutions in Multimedia and Hypertext. (P. 21-30) Eds.: Susan Stone and Michaelsheetal tanejaPas encore d'évaluation
- Elmasri 6eism 02Document2 pagesElmasri 6eism 02sheetal tanejaPas encore d'évaluation
- Karma: by Annie BesantDocument36 pagesKarma: by Annie Besantsheetal taneja100% (1)
- Karma: Why Bad Things Happen To Good PeopleDocument24 pagesKarma: Why Bad Things Happen To Good Peoplesheetal tanejaPas encore d'évaluation
- Take A Second LookDocument1 pageTake A Second Looksheetal tanejaPas encore d'évaluation
- SOLUTIONSDocument2 pagesSOLUTIONSsheetal tanejaPas encore d'évaluation
- LP DualityDocument37 pagesLP Dualitysheetal tanejaPas encore d'évaluation
- Guidelines For Csct501Document4 pagesGuidelines For Csct501sheetal tanejaPas encore d'évaluation
- Few More AreasDocument2 pagesFew More Areassheetal tanejaPas encore d'évaluation
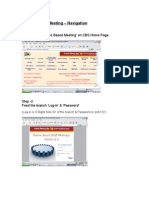
- Step - 1 Click On Link Theme Based Meeting' On CBS Home PageDocument3 pagesStep - 1 Click On Link Theme Based Meeting' On CBS Home Pagesheetal tanejaPas encore d'évaluation
- 1 Assignment Last Date: 8 MarchDocument1 page1 Assignment Last Date: 8 Marchsheetal tanejaPas encore d'évaluation
- Bin PackingDocument6 pagesBin Packingsheetal tanejaPas encore d'évaluation
- Volume 43, Issue 26 - June 29, 2012Document48 pagesVolume 43, Issue 26 - June 29, 2012BladePas encore d'évaluation
- Unit23 SolutionsDocument7 pagesUnit23 SolutionsAbcPas encore d'évaluation
- Unit: 2 States of Matter: Important PointsDocument24 pagesUnit: 2 States of Matter: Important PointsManish SinghPas encore d'évaluation
- Sciencedoze: Science, Education and Technology: Biodegradable Polymers: de Nition, Examples, Properties and ApplicationsDocument5 pagesSciencedoze: Science, Education and Technology: Biodegradable Polymers: de Nition, Examples, Properties and Applicationssantosh chikkamathPas encore d'évaluation
- Dhiman - Attitude of Parents Towards SchoolingDocument9 pagesDhiman - Attitude of Parents Towards SchoolingAnonymous xgY5a6JBbPas encore d'évaluation
- Fagen Et AlDocument44 pagesFagen Et Alhaulatamir100% (3)
- Troubleshooting DHCP and NAT Configurations PDFDocument2 pagesTroubleshooting DHCP and NAT Configurations PDF94akuPas encore d'évaluation
- ZoroastrianismDocument13 pagesZoroastrianismDave Sarmiento ArroyoPas encore d'évaluation
- Charles Schwab - SpeechDocument5 pagesCharles Schwab - SpeechvaluablenamesPas encore d'évaluation
- Ele Imhpssdp 1ST Term NotesDocument7 pagesEle Imhpssdp 1ST Term NotesDANIELLE TORRANCE ESPIRITUPas encore d'évaluation
- Ocampo Et Al. vs. Enriquez, G.R. Nos. 225973 8 November 2016. Peralta, JDocument3 pagesOcampo Et Al. vs. Enriquez, G.R. Nos. 225973 8 November 2016. Peralta, JAnna GuevarraPas encore d'évaluation
- EG Lagging Students 2016Document30 pagesEG Lagging Students 2016arickPas encore d'évaluation
- Siklu Etherhaul ManualDocument221 pagesSiklu Etherhaul ManualmikkhailPas encore d'évaluation
- CHEM BIO Organic MoleculesDocument7 pagesCHEM BIO Organic MoleculesLawrence SarmientoPas encore d'évaluation
- Verbos Repaso-1bDocument5 pagesVerbos Repaso-1bMonica AlvaradoPas encore d'évaluation
- Clinical Outcome of Tolosa-Hunt Syndrome After Intravenous Steroid Therapy (Case Report)Document1 pageClinical Outcome of Tolosa-Hunt Syndrome After Intravenous Steroid Therapy (Case Report)JumrainiTammassePas encore d'évaluation
- Past Simple Regular Verbs Fun Activities Games - 18699Document2 pagesPast Simple Regular Verbs Fun Activities Games - 18699emilyPas encore d'évaluation
- Air France vs. Charles Auguste Raymond M. ZaniDocument15 pagesAir France vs. Charles Auguste Raymond M. ZaniGret HuePas encore d'évaluation
- Full Report of Mini ProjectDocument23 pagesFull Report of Mini ProjectNarsyida Niasara HamdanPas encore d'évaluation
- NOTES On CAPITAL BUDGETING PVFV Table - Irr Only For Constant Cash FlowsDocument3 pagesNOTES On CAPITAL BUDGETING PVFV Table - Irr Only For Constant Cash FlowsHussien NizaPas encore d'évaluation
- Engineering Stages of New Product DevelopmentDocument20 pagesEngineering Stages of New Product DevelopmentRichard CarsonPas encore d'évaluation
- Test - SchoolDocument3 pagesTest - SchoolAna MateusPas encore d'évaluation
- Chickens Come Home To Roost (Genesis 32: 1 - 36: 43)Document13 pagesChickens Come Home To Roost (Genesis 32: 1 - 36: 43)logosbiblestudy100% (1)
- 434 Final PaperDocument21 pages434 Final Paperapi-478219860Pas encore d'évaluation
- Strategic Planning, Sales Strategy, Sales Forecasting, and BudgetingDocument18 pagesStrategic Planning, Sales Strategy, Sales Forecasting, and BudgetingMona AgarwalPas encore d'évaluation
- The Kujung Formation in Kurnia-1 A Viable FractureDocument23 pagesThe Kujung Formation in Kurnia-1 A Viable FractureAnnas Yusuf H.Pas encore d'évaluation
- Logit ProbitDocument17 pagesLogit ProbitGKGEAPas encore d'évaluation
- Tourist Behaviour Unit I & IIDocument83 pagesTourist Behaviour Unit I & IIRashmiranjanPas encore d'évaluation
- Full Download Introduction To Operations and Supply Chain Management 3rd Edition Bozarth Test BankDocument36 pagesFull Download Introduction To Operations and Supply Chain Management 3rd Edition Bozarth Test Bankcoraleementgen1858100% (42)
- The Patriarchial Idea of God Author(s) : Herbert Gordon May Source: Journal of Biblical Literature, Vol. 60, No. 2 (Jun., 1941), Pp. 113-128 Published By: Stable URL: Accessed: 19/06/2014 16:43Document17 pagesThe Patriarchial Idea of God Author(s) : Herbert Gordon May Source: Journal of Biblical Literature, Vol. 60, No. 2 (Jun., 1941), Pp. 113-128 Published By: Stable URL: Accessed: 19/06/2014 16:43Fernando FonsecaPas encore d'évaluation