Académique Documents
Professionnel Documents
Culture Documents
Documentacion Final de Sistemas de Base de Datos Avanzados
Transféré par
lolealvaroTitre original
Copyright
Formats disponibles
Partager ce document
Partager ou intégrer le document
Avez-vous trouvé ce document utile ?
Ce contenu est-il inapproprié ?
Signaler ce documentDroits d'auteur :
Formats disponibles
Documentacion Final de Sistemas de Base de Datos Avanzados
Transféré par
lolealvaroDroits d'auteur :
Formats disponibles
Final de Sistemas de Base de Datos Avanzados
Alumnos: Mangiafico Alejandra Natalia, Lopez Gabriela Alejandra, Palavecino Cecilia Beatriz Profesor: Ingeniero Sardi, Duilio
ResumenEl presente trabajo fue elaborado para la aprobacin de una materia de 5 aos de la carrera de ingeniera en sistema de informacin. En este documento se explicar el desarrollo de un sistema de informacin y las herramientas que se utilizaron para el sistema en ejecucin.
ndices Funciones del sistema, Herramienta para el desarrollo, Mdulos.
I. INTRODUCCIN
STE documento presenta la informacin de la elaboracin de un software para una farmacia del medio. Se va a describir los mdulos que se han desarrollado para el perfecto funcionamiento de los procesos de negocio que maneja dicha farmacia.
II. OBJETIVOS PRETENDIDOS
Ofrecer un sistema que permita agilizar el control de ventas. Ofrecer una interfaz amigable para facilitar su uso. Facilitar al usuario la bsqueda de los productos, consultando su precio, descripcin y la cantidad disponible. Realizar clculos, como totales, vueltos, etc. para evitar las equivocaciones en el proceso del negocio. Facilitar el control de Stock (ingreso y egreso de productos). Proveer un mecanismo de control de acceso al sistema, mediante contraseas, para evitar el ingreso de personas no autorizadas. Optimizar el proceso de liquidacin de sueldos, manteniendo un registro de los empleados con sus correspondientes datos. Mejorar la seguridad del Sistema encriptando las claves de los Usuarios en la Base de Datos. Proveer mecanismo de consultas para saber cunto se ha vendido, cuanto se ha gastado, saber que Stock est en estado crtico.
III. FUNCIONES DEL SISTEMA
Bsicamente el sistema puede dividirse en cuatro mdulos: Mdulo de Venta Mdulo de Compra Mdulo de Liquidacin Mdulo de Registro de Entidades Mdulo de consulta
IV. MDULO DE VENTA
El objetivo de este mdulo es el de cubrir todas las necesidades correspondientes a la Gestin de Ventas. Contempla las funciones referentes a facturacin y cuentas corrientes deudoras de clientes. Adems se conecta e integra en forma automtica con el mdulo de Stock. Las entidades que intervienen en este Modulo son: VENTA PRODUCTO DETALLE_VENTA PAGO_CON_TARJETA CUENTA_CORRIENTE EMPLEADO
V. MODULO DE COMPRA
Este mdulo permite una efectiva clasificacin y registro de las compras que realiza la farmacia a proveedores (locales, nacionales, entre otros) Las entidades que intervienen en este Modulo son: PROVEEDOR COMPRA DETALLE_COMPRA PRODUCTO
VI. MODULO DE LIQUIDACIN
Este modulo permite liquidar el sueldo por periodo de los empleados que trabajan en la farmacia. Las entidades que intervienen en este Modulo son: EMPLEADO LIQUIDACION DETALLE _ LIQUIDACIN CONCEPTO
VII. MDULO DE REGISTRO DE ENTIDADES
Este mdulo permite la gestin de los datos de Productos, Usuarios, Proveedores, Cliente, Empleado. Esta informacin es de suma importancia ya que otros mdulos la necesitan para completar sus operaciones.Las entidades que intervienen en este Modulo son: EMPLEADO PROVEEDOR PRODUCTO CLIENTE USUARIO Cabe aclara que dentro este mdulo se encuentra el mdulo de Stock que es la que centraliza toda la informacin referida a los datos del producto.
VIII. MDULO DE CONSULTA
Este modulo tiene como objetivo el de brindar informacin de los registros que se llevan a cabo en la farmacia. Tales consultas de registro son: Venta Stock Compra Liquidacin
IX. ATRIBUTOS DEL SISTEMA
Plataforma: Multiplataforma. Tiempo de Respuesta: 1 2 Segundos. Tolerancia a Fallos: 1a 2 veces por ao. Metfora de Interfaz: ventanas orientadas al dialogo que llevan a una mayor utilizacin del Mouse en lugar de teclado, aunque a este tambin se lo puede utilizar. La confidencialidad: la informacin es accedida exclusivamente por el personal autorizado del negocio. Seguridad: ofrece proteccin tras el uso de jerarqua de usuarios, las contraseas estn encriptados con el tipo de encriptacin md5.
X. HERRAMIENTAS UTILIZADAS EN EL DESARROLLO
MySQL MySQL es un sistema de gestin de bases de datos relacional, multihilo y multiusuario con ms de seis millones de instalaciones. 1 MySQL AB desde enero de 2008 una subsidiaria de Sun Microsystems y sta a su vez de Oracle Corporation desde abril de 2009 que desarrolla MySQL como software libre en un esquema de licenciamiento dual.
XI. INSTALACION DEL GESTOR DE BASE DE DATOS WAMP ( WINDOWS APACHE MYSQL PHP)
Recursos legales GNU
Carpeta de destino donde se instalaran los archivos generalmene es en la particion raiz del SO crea una carpeta llamada wamp
Opciones generales de configuracin del acceso al sistema.
Listo para la instalacin, es el paso de revisin de la configuracin seleccionada para el programa.
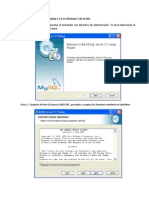
Instalando WAMP Server en el equipo
Una vez finalizada la instalacin, el instalador pregunta si desea ejecutar el wampserver
En la siguinete captura se puede observar al programa corriendo bajo el entorno de windows 7 x64
XII. HERRAMIENTAS DE WAMP
Wamp server trae una serie de herramientas destinadas para la administracion del las diferentes tecnologias, trae consigo phpmyadmin que es un sistema que hace uso de las tecnologias web para administrar las caracteristicas de mysql con una interfaz facil de entender
En cada pestaa se puede observar: Las bases de datos Ejecutar sentencias Sql sobre cualquier DB o Tabla Estado Actual: donde se puede ver cunto tiempo est activo el servidor, las consultas que se ejecutaron, cuales son las ms repetidas de ellas, Variables: ac se encuentra variables de configuracin del servidor, como el auto incremental etc. Juego de Caracteres: se refiere al lenguaje usado para almacenar los datos sobre las tablas uno puede elegir entre varios tipos como ASCII, UTF, lenguajes como espaol, francs, armenio, ingles etc. Motores: Son aquellos tipos de motores de base de datos INNODB; Hash, etc Privilegios: sirve para la administracin de usuarios, mantiene los privilegios, accesos, espacio, cantidad de transacciones, etc. Replicacin: sirve para administrar la replicacin del servidor Log Usuario. Es el log del usuario actual sobre el servidor
Procesos: muestra los diferentes procesos que se estn ejecutando sobre el servidor. Exportar: una caracterstica bastante desarrollada de phpmyadmin ya que permite exportar una DB completa o simplemente un registro de una tabla en diferentes formatos como CVS, texto plano, sql, Excel etc. Importar: es para insertar comandos sql o scriptsql en nuestra DBMS Sincronizar: sirve para comunicar 2 servidores diferentes. Adems de phpmyadmin existen otras herramientas para configurar el servidor, httpconf es un archivo de texto para poder configurar las caractersticas del servidor apache. Php ini, es el similar a httpconf de apache pero para las variables y caractersticas del lenguaje php, la configuracin de las variables globales, etc. Como cuenta con mysql existe adems la posibilidad de acceder a la consola de mysql a travs del a interfaz del programa.
Para mostrar la relacion entre las tablas se ha usado mysql workbench. Que es una herramienta visual de MySql
Base de datos: `sistemagestionfarmacia` Estructura de tabla para la tabla `cliente` CREATE TABLE IF NOT EXISTS `cliente` ( `idCliente` int(11) NOT NULL AUTO_INCREMENT, `dni` int(11) DEFAULT NULL, `apellido` varchar(255) DEFAULT NULL, `nombre` varchar(255) DEFAULT NULL, `domicilio` varchar(255) DEFAULT NULL, `telefono` varchar(255) DEFAULT NULL, `estado` varchar(45) DEFAULT NULL, `baja` int(10) unsigned DEFAULT NULL, PRIMARY KEY (`idCliente`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=6 ;
-- Volcar la base de datos para la tabla `cliente` INSERT INTO `cliente` (`idCliente`, `dni`, `apellido`, `nombre`, `domicilio`, `telefono`, `estado`, `baja`) VALUES (1, 78965412, 'Apellido Prueba', 'Nombre Prueba Modifi', 'domicilio', 'telefono', 'Sin Cuenta Pendiente', 2), (2, 788965, 'AD', 'RubenM', 'domicilio', 'telefono', 'Tiene Cuenta Pendiente', 2), (3, 32432543, 'Lopez T', 'Gabriela', 'psmagallllanes', '4231232', 'Sin Cuenta Pendiente', 1), (4, 29432345, 'Mangiafico', 'Alejandra', 'Rivadavia 300', '23456778', 'Sin Cuenta Pendiente', 1), (5, 23356566, 'Palavecino', 'Ceci', 'As', '4543212', 'Sin Cuenta Pendiente', 1);
Estructura de tabla para la tabla `compra`
CREATE TABLE IF NOT EXISTS `compra` ( `idCompra` int(11) NOT NULL DEFAULT '0', `idProveedor` int(11) NOT NULL, `legajo` int(11) NOT NULL, `fecha` date DEFAULT NULL, `total` float DEFAULT NULL, PRIMARY KEY (`idCompra`), KEY `fk_compra_proveedor1` (`idProveedor`), KEY `fk_compra_empleado1` (`legajo`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; Volcar la base de datos para la tabla `compra` INSERT INTO `compra` (`idCompra`, `idProveedor`, `legajo`, `fecha`, `total`) VALUES (1, 4, 1459, '2011-12-08', 85), (2, 5, 1459, '2011-12-08', 12), (3, 4, 1459, '2011-12-08', 84), (4, 4, 1459, '2011-12-08', 40), (5, 4, 1459, '2011-12-08', 60), (6, 4, 1459, '2011-12-09', 30); Estructura de tabla para la tabla `concepto` CREATE TABLE IF NOT EXISTS `concepto` ( `idConcepto` int(11) NOT NULL DEFAULT '0', `descripcion` varchar(45) DEFAULT NULL, `importe` float DEFAULT NULL, `tipo` varchar(5) DEFAULT NULL, `porcentaje` float DEFAULT NULL, PRIMARY KEY (`idConcepto`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; Volcar la base de datos para la tabla `concepto` INSERT INTO `concepto` (`idConcepto`, `descripcion`, `importe`, `tipo`, `porcentaje`) VALUES (0, NULL, NULL, NULL, NULL), (1, 'Presentismo', 0, 'haber', 8.33), (2, 'Jubilacin', 0, 'deber', 11), (3, 'Ley 19032', 0, 'deber', 3), (4, 'Obra Social', 0, 'deber', 3), (5, 'Cuota Social', 0, 'deber', 2), (6, 'Cuota Sindical', 0, 'deber', 1), (7, 'FAECYS', 0, 'deber', 0.5), (8, 'Inc. Salarial 20% ( Acue. Abr/08 )', 138, 'haber', 0), (9, 'Suma Fija ( Acue. Abr/08 )', 50, 'haber', 0), (10, 'Suma Fija ( Acue. Abr/09 )', 150, 'haber', 0), (11, 'Present. S/Acuerdo Colectivo', 28.16, 'haber', 0), (12, 'Obra Social ( Acue. Abr/08-09)', 0, 'deber', 3), (13, 'Cuota Social ( Acue. Abr/08-09)', 0, 'deber', 2), (14, 'FAECYS ( Acue. Abr/08-09)', 0, 'deber', 0.5);
Estructura de tabla para la tabla `cuentacorriente` CREATE TABLE IF NOT EXISTS `cuentacorriente` ( `idCliente` int(11) NOT NULL DEFAULT '0', `idventa` int(11) NOT NULL, `fecha` date NOT NULL, `debe` float DEFAULT NULL, `haber` float DEFAULT NULL, `saldo` float DEFAULT NULL, `estado` varchar(45) NOT NULL DEFAULT '', KEY `fk_cuentaCorriente_venta1` (`idventa`), KEY `fk_cuentaCorriente_cliente1` (`idCliente`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; Volcar la base de datos para la tabla `cuentacorriente` Estructura de tabla para la tabla `empleado` CREATE TABLE IF NOT EXISTS `empleado` ( `legajo` int(11) NOT NULL AUTO_INCREMENT, `sueldo_basico` float DEFAULT NULL, `apellido` varchar(45) DEFAULT NULL, `nombre` varchar(45) DEFAULT NULL, `dni` int(8) unsigned NOT NULL DEFAULT '0', `cuit` varchar(45) DEFAULT NULL, `estado_civil` varchar(45) DEFAULT NULL, `telefono` varchar(45) DEFAULT NULL, `domicilio` varchar(255) DEFAULT NULL, `fechaIngreso` date DEFAULT NULL, `fechaDeRetiro` date DEFAULT NULL, `fechaNacimiento` date DEFAULT NULL, `baja` int(10) unsigned DEFAULT NULL, PRIMARY KEY (`legajo`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1462 ;
Volcar la base de datos para la tabla `empleado` INSERT INTO `empleado` (`legajo`, `sueldo_basico`, `apellido`, `nombre`, `dni`, `cuit`, `estado_civil`, `telefono`, `domicilio`, `fechaIngreso`, `fechaDeRetiro`, `fechaNacimiento`, `baja`) VALUES (1459, 500, 'Palavecino', 'Cecilia', 34321098, '273454323456', 'Soltero', '4279032', 'Av-Nose', '2011-12-08', NULL, '1986-12-10', 1), (1460, 600, 'Nazar', 'Patrcia', 34567889, '1233434545', 'Soltero', '0', 'x', '2011-12-08', '1800-0101', '1989-12-08', 2), (1461, 940, 'mangiafico', 'alejandra', 29357919, '2729357991', 'Soltero', '0386315400029', 'rivadavia', '2011-12-09', '1800-01-01', '1982-11-02', 1); Estructura de tabla para la tabla `linea_compra`
CREATE TABLE IF NOT EXISTS `linea_compra` ( `idProducto` int(11) NOT NULL, `idCompra` int(11) NOT NULL, `cantidad` int(11) NOT NULL, `detalle` varchar(255) DEFAULT NULL, `precioUnitario` float DEFAULT NULL, `subtotal` float DEFAULT NULL, PRIMARY KEY (`idCompra`,`idProducto`), KEY `fk_linea_compra_compra1` (`idCompra`), KEY `fk_linea_compra_producto1` (`idProducto`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1;
Volcar la base de datos para la tabla `linea_compra` INSERT INTO `linea_compra` (`idProducto`, `idCompra`, `cantidad`, `detalle`, `precioUnitario`, `subtotal`) VALUES (1263, 1, 5, 'Bayaspirina', 12, 60), (1264, 1, 5, 'Paracetamol', 5, 25), (1263, 2, 1, 'Bayaspirina', 12, 12), (1263, 3, 7, 'Bayaspirina', 12, 84), (1264, 4, 8, 'Paracetamol', 5, 40), (1263, 5, 5, 'Bayaspirina', 12, 60), (1268, 6, 5, 'nobalgina', 6, 30); Estructura de tabla para la tabla `linea_liquidacion` CREATE TABLE IF NOT EXISTS `linea_liquidacion` ( `empleadoLegajo` int(11) NOT NULL DEFAULT '0', `idLiquidacion` int(11) NOT NULL, `idConcepto` int(11) NOT NULL, `totalHaber` varchar(45) DEFAULT NULL, `totalDeber` varchar(45) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL, `descripcion` varchar(45) NOT NULL DEFAULT '', KEY `fk_linea_liquidacion_concepto1` (`idConcepto`), KEY `fk_linea_liquidacion_liquidacion1` (`idLiquidacion`,`empleadoLegajo`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; Volcar la base de datos para la tabla `linea_liquidacion` INSERT INTO `linea_liquidacion` (`empleadoLegajo`, `idLiquidacion`, `idConcepto`, `totalHaber`, `totalDeber`, `descripcion`) VALUES (1459, 1, 0, '500.0', '-', 'Sueldo Bsico'), (1459, 1, 1, '41.65', '-', 'Presentismo'), (1459, 1, 2, '-', '59.581505', 'Jubilacin'), (1459, 1, 3, '-', '16.2495', 'Ley 19032'), (1459, 1, 4, '-', '16.2495', 'Obra Social'), (1459, 1, 5, '-', '10.833', 'Cuota Social'), (1459, 1, 6, '-', '5.4165', 'Cuota Sindical'), (1459, 1, 7, '-', '2.70825', 'FAECYS'), (1459, 1, 8, '138.0', '-', 'Inc. Salarial 20% ( Acue. Abr/08 )'), (1459, 1, 9, '50.0', '-', 'Suma Fija ( Acue. Abr/08 )'), (1459, 1, 10, '150.0', '-', 'Suma Fija ( Acue. Abr/09 )'),
(1459, 1, 11, '28.16', '-', 'Present. S/Acuerdo Colectivo'), (1459, 1, 12, '-', '10.984799', 'Obra Social ( Acue. Abr/08-09)'), (1459, 1, 13, '-', '7.3232', 'Cuota Social ( Acue. Abr/08-09)'), (1459, 1, 14, '-', '1.8308', 'FAECYS ( Acue. Abr/08-09)'), (1459, 2, 0, '500.0', '-', 'Sueldo Bsico'), (1459, 2, 1, '41.65', '-', 'Presentismo'), (1459, 2, 2, '-', '59.581505', 'Jubilacin'), (1459, 2, 3, '-', '16.2495', 'Ley 19032'), (1459, 2, 4, '-', '16.2495', 'Obra Social'), (1459, 3, 0, '500.0', '-', 'Sueldo Bsico'), (1459, 3, 1, '41.65', '-', 'Presentismo'), (1459, 3, 2, '-', '59.581505', 'Jubilacin'), (1459, 3, 3, '-', '16.2495', 'Ley 19032'), (1460, 4, 0, '600.0', '-', 'Sueldo Bsico'), (1460, 4, 1, '49.98', '-', 'Presentismo'), (1460, 4, 2, '-', '71.497795', 'Jubilacin'), (1460, 4, 3, '-', '19.4994', 'Ley 19032'), (1460, 4, 4, '-', '19.4994', 'Obra Social'), (1460, 4, 5, '-', '12.999599', 'Cuota Social'), (1460, 4, 6, '-', '6.4997997', 'Cuota Sindical'), (1460, 4, 7, '-', '3.2498999', 'FAECYS'), (1460, 4, 8, '138.0', '-', 'Inc. Salarial 20% ( Acue. Abr/08 )'), (1460, 4, 9, '50.0', '-', 'Suma Fija ( Acue. Abr/08 )'), (1460, 4, 10, '150.0', '-', 'Suma Fija ( Acue. Abr/09 )'), (1460, 4, 11, '28.16', '-', 'Present. S/Acuerdo Colectivo'), (1460, 4, 13, '-', '7.3232', 'Cuota Social ( Acue. Abr/08-09)'), (1460, 4, 14, '-', '1.8308', 'FAECYS ( Acue. Abr/08-09)'), (1460, 5, 0, '600.0', '-', 'Sueldo Bsico'), (1460, 5, 1, '49.98', '-', 'Presentismo'), (1460, 5, 2, '-', '71.497795', 'Jubilacin'), (1460, 5, 3, '-', '19.4994', 'Ley 19032'), (1460, 5, 4, '-', '19.4994', 'Obra Social'), (1460, 5, 5, '-', '12.999599', 'Cuota Social'), (1460, 5, 6, '-', '6.4997997', 'Cuota Sindical'); Estructura de tabla para la tabla `linea_venta` CREATE TABLE IF NOT EXISTS `linea_venta` ( `idProducto` int(11) NOT NULL, `idVenta` int(11) NOT NULL, `cantidad` int(11) NOT NULL, `detalle` varchar(255) DEFAULT NULL, `precioUnitario` float DEFAULT NULL, `subtotal` float DEFAULT NULL, PRIMARY KEY (`idProducto`,`idVenta`), KEY `fk_linea_venta_producto1` (`idProducto`), KEY `fk_linea_venta_venta1` (`idVenta`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; Volcar la base de datos para la tabla `linea_venta`
INSERT INTO `linea_venta` (`idProducto`, `idVenta`, `cantidad`, `detalle`, `precioUnitario`, `subtotal`) VALUES (1263, 1, 1, 'Bayaspirina', 15, 15), (1263, 2, 1, 'Bayaspirina', 15, 15), (1264, 3, 1, 'Paracetamol', 8.5, 8.5); Estructura de tabla para la tabla `liquidacion` CREATE TABLE IF NOT EXISTS `liquidacion` ( `idLiquidacion` int(11) NOT NULL DEFAULT '0', `empleadoLegajo` int(11) NOT NULL, `fecha` date DEFAULT NULL, `total` float DEFAULT NULL, `periodo` date DEFAULT NULL, PRIMARY KEY (`idLiquidacion`,`empleadoLegajo`), KEY `fk_liquidacion_empleado1` (`empleadoLegajo`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; Volcar la base de datos para la tabla `liquidacion` INSERT INTO `liquidacion` (`idLiquidacion`, `empleadoLegajo`, `fecha`, `total`, `periodo`) VALUES (1, 1459, '2011-12-08', 776.633, '2011-07-02'), (2, 1459, '2011-12-08', 449.569, '2011-08-05'), (3, 1459, '2011-12-08', 465.819, '2011-12-08'), (4, 1460, '2011-12-08', 873.74, '2011-05-01'), (5, 1460, '2011-12-09', 519.984, '2011-12-09'); Estructura de tabla para la tabla `novedades` CREATE TABLE IF NOT EXISTS `novedades` ( `idLiquidacion` int(11) DEFAULT NULL, `idConcepto` int(11) DEFAULT NULL, `descripcion` varchar(45) DEFAULT NULL, `importe` float DEFAULT NULL, `tipo` varchar(5) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=latin1; Volcar la base de datos para la tabla `novedades` Estructura de tabla para la tabla `pagotarjeta` CREATE TABLE IF NOT EXISTS `pagotarjeta` ( `idVenta` int(11) NOT NULL DEFAULT '0', `codigoTarjeta` varchar(45) DEFAULT NULL, `saldo` float DEFAULT NULL, `descripcion` varchar(45) DEFAULT NULL, `cuota` int(11) DEFAULT NULL, `precioPorCuota` int(10) unsigned DEFAULT NULL, KEY `fk_pagoTarjeta_venta1` (`idVenta`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1;
Volcar la base de datos para la tabla `pagotarjeta` INSERT INTO `pagotarjeta` (`idVenta`, `codigoTarjeta`, `saldo`, `descripcion`, `cuota`, `precioPorCuota`) VALUES (3, '1234', 8.5, 'Naranja Visa', 2, 4) Estructura de tabla para la tabla `producto` CREATE TABLE IF NOT EXISTS `producto` ( `idProducto` int(11) NOT NULL AUTO_INCREMENT, `descripcion` varchar(255) DEFAULT NULL, `presentacion` varchar(45) DEFAULT NULL, `precio_compra` float DEFAULT NULL, `precio_venta` float DEFAULT NULL, `cantidad_existente` int(11) DEFAULT NULL, `baja` int(10) unsigned NOT NULL DEFAULT '0', PRIMARY KEY (`idProducto`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1270 ; Volcar la base de datos para la tabla `producto` INSERT INTO `producto` (`idProducto`, `descripcion`, `presentacion`, `precio_compra`, `precio_venta`, `cantidad_existente`, `baja`) VALUES (1263, 'Bayaspirina', 'AS', 12, 15, 10, 2), (1264, 'Paracetamol', 'Comprimido', 5, 8.5, 7, 1), (1265, 'bayaspirina', 'comprimidos', 12, 15, 55, 1), (1266, 'refrianex', 'compimidos', 2, 3.5, 94, 1), (1267, 'dexametasona', 'comprimidos', 2, 5, 10, 1), (1268, 'nobalgina', 'jarabe', 6, 12, 15, 1), (1269, 'macril', 'crema 20g', 13, 20, 5, 1); Estructura de tabla para la tabla `proveedor` CREATE TABLE IF NOT EXISTS `proveedor` ( `idProveedor` int(11) NOT NULL AUTO_INCREMENT, `cuit` varchar(45) DEFAULT NULL, `nombre` varchar(45) DEFAULT NULL, `razon_social` varchar(45) DEFAULT NULL, `domicilio` varchar(255) DEFAULT NULL, `mail` varchar(45) DEFAULT NULL, `telefono` int(11) DEFAULT NULL, `fax` varchar(45) DEFAULT NULL, `baja` int(10) unsigned DEFAULT NULL, PRIMARY KEY (`idProveedor`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=6 ; Volcar la base de datos para la tabla `proveedor` INSERT INTO `proveedor` (`idProveedor`, `cuit`, `nombre`, `razon_social`, `domicilio`, `mail`, `telefono`, `fax`, `baja`) VALUES (4, '1223344', 'Nam', 'Cofaral', 'domicilio', 'x', 4637172, 'x', 1), (5, '123455', 'AS', 'Suiza', 'x', 'x', 0, 'x', 1);
Estructura de tabla para la tabla `subtotalliquidacion` CREATE TABLE IF NOT EXISTS `subtotalliquidacion` ( `totalHaber` float DEFAULT NULL, `totalDeber` float DEFAULT NULL, `liquidacion_idLiquidacion` int(11) NOT NULL, KEY `fk_subtotalLiquidacion_liquidacion` (`liquidacion_idLiquidacion`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; Volcar la base de datos para la tabla `subtotalliquidacion` INSERT INTO `subtotalliquidacion` (`totalHaber`, `totalDeber`, `liquidacion_idLiquidacion`) VALUES (907.81, 131.177, 1), (541.65, 92.0805, 2), (541.65, 75.831, 3), (1016.14, 142.4, 4), (649.98, 129.996, 5); Estructura de tabla para la tabla `usuario` CREATE TABLE IF NOT EXISTS `usuario` ( `usuario` varchar(25) NOT NULL DEFAULT '', `clave` varchar(25) NOT NULL DEFAULT '', `privilegio` varchar(25) NOT NULL DEFAULT '', `legajo` int(10) unsigned NOT NULL DEFAULT '0', PRIMARY KEY (`usuario`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; Volcar la base de datos para la tabla `usuario` INSERT INTO `usuario` (`usuario`, `clave`, `privilegio`, `legajo`) VALUES ('alejandra', 'E{23.eQ', 'Administrador', 1461), ('cecilia', 'E{23.eQ', 'Administrador', 1459); Estructura de tabla para la tabla `venta CREATE TABLE IF NOT EXISTS `venta` ( `idVenta` int(11) NOT NULL DEFAULT '0', `idCliente` int(11) DEFAULT NULL, `legajo` int(11) NOT NULL, `fecha` date DEFAULT NULL, `total` float DEFAULT NULL, `tipoVenta` varchar(45) DEFAULT NULL, PRIMARY KEY (`idVenta`), KEY `fk_venta_cliente1` (`idCliente`), KEY `fk_venta_empleado1` (`legajo`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1;
Volcar la base de datos para la tabla `venta` INSERT INTO `venta` (`idVenta`, `idCliente`, `legajo`, `fecha`, `total`, `tipoVenta`) VALUES (1, 4, 1459, '2011-12-08', 15, 'EFECTIVO'), (2, 5, 1459, '2011-12-08', 15, 'EFECTIVO'), (3, 4, 1459, '2011-12-09', 8.5, 'TARJETA'); Estructura Stand-in para la vista `v_usuario` CREATE TABLE IF NOT EXISTS `v_usuario` ( `usuario` varchar(25) ,`clave` varchar(25) ,`privilegio` varchar(25) ,`legajo` int(11) ,`nombre` varchar(45) ,`apellido` varchar(45) ); Estructura para la vista `v_usuario` DROP TABLE IF EXISTS `v_usuario`; CREATE ALGORITHM=UNDEFINED DEFINER=`root`@`localhost` SQL SECURITY DEFINER VIEW `v_usuario` AS select `usuario`.`usuario` AS `usuario`,`usuario`.`clave` AS `clave`,`usuario`.`privilegio` AS `privilegio`,`empleado`.`legajo` AS `legajo`,`empleado`.`nombre` AS `nombre`,`empleado`.`apellido` AS `apellido` from (`usuario` join `empleado` on((`empleado`.`legajo` = `usuario`.`legajo`))); Filtros para las tablas descargadas (dump) Filtros para la tabla `compra` ALTER TABLE `compra` ADD CONSTRAINT `fk_compra_empleado1` FOREIGN KEY (`legajo`) REFERENCES `empleado` (`legajo`) ON DELETE NO ACTION ON UPDATE NO ACTION, ADD CONSTRAINT `fk_compra_proveedor1` FOREIGN KEY (`idProveedor`) REFERENCES `proveedor` (`idProveedor`) ON DELETE NO ACTION ON UPDATE NO ACTION; Filtros para la tabla `cuentacorriente` ALTER TABLE `cuentacorriente` ADD CONSTRAINT `fk_cuentaCorriente_cliente1` FOREIGN KEY (`idCliente`) REFERENCES `cliente` (`idCliente`) ON DELETE NO ACTION ON UPDATE NO ACTION, ADD CONSTRAINT `fk_cuentaCorriente_venta1` FOREIGN KEY (`idventa`) REFERENCES `venta` (`idVenta`) ON DELETE NO ACTION ON UPDATE NO ACTION; Filtros para la tabla `linea_compra` ALTER TABLE `linea_compra`
ADD CONSTRAINT `fk_linea_compra_compra1` FOREIGN KEY (`idCompra`) REFERENCES `compra` (`idCompra`) ON DELETE NO ACTION ON UPDATE NO ACTION, ADD CONSTRAINT `fk_linea_compra_producto1` FOREIGN KEY (`idProducto`) REFERENCES `producto` (`idProducto`) ON DELETE NO ACTION ON UPDATE NO ACTION; Filtros para la tabla `linea_liquidacion` ALTER TABLE `linea_liquidacion` ADD CONSTRAINT `fk_linea_liquidacion_concepto1` FOREIGN KEY (`idConcepto`) REFERENCES `concepto` (`idConcepto`) ON DELETE NO ACTION ON UPDATE NO ACTION, ADD CONSTRAINT `fk_linea_liquidacion_liquidacion1` FOREIGN KEY (`idLiquidacion`, `empleadoLegajo`) REFERENCES `liquidacion` (`idLiquidacion`, `empleadoLegajo`) ON DELETE NO ACTION ON UPDATE NO ACTION; Filtros para la tabla `linea_venta` ALTER TABLE `linea_venta` ADD CONSTRAINT `fk_linea_venta_producto1` FOREIGN KEY (`idProducto`) REFERENCES `producto` (`idProducto`) ON DELETE NO ACTION ON UPDATE NO ACTION, ADD CONSTRAINT `fk_linea_venta_venta1` FOREIGN KEY (`idVenta`) REFERENCES `venta` (`idVenta`) ON DELETE NO ACTION ON UPDATE NO ACTION; Filtros para la tabla `liquidacion` ALTER TABLE `liquidacion` ADD CONSTRAINT `fk_liquidacion_empleado1` FOREIGN KEY (`empleadoLegajo`) REFERENCES `empleado` (`legajo`) ON DELETE NO ACTION ON UPDATE NO ACTION; Filtros para la tabla `pagotarjeta` ALTER TABLE `pagotarjeta` ADD CONSTRAINT `fk_pagoTarjeta_venta1` FOREIGN KEY (`idVenta`) REFERENCES `venta` (`idVenta`) ON DELETE NO ACTION ON UPDATE NO ACTION; Filtros para la tabla `subtotalliquidacion` ALTER TABLE `subtotalliquidacion` ADD CONSTRAINT `fk_subtotalLiquidacion_liquidacion` FOREIGN KEY (`liquidacion_idLiquidacion`) REFERENCES `liquidacion` (`idLiquidacion`) ON DELETE NO ACTION ON UPDATE NO ACTION; Filtros para la tabla `venta` ALTER TABLE `venta`
ADD CONSTRAINT `fk_venta_cliente1` FOREIGN KEY (`idCliente`) REFERENCES `cliente` (`idCliente`) ON DELETE NO ACTION ON UPDATE NO ACTION, ADD CONSTRAINT `fk_venta_empleado1` FOREIGN KEY (`legajo`) REFERENCES `empleado` (`legajo`) ON DELETE NO ACTI
Phpmyadmin muestra dos BD relacionadas con la informacin sobre las BD creadas y generadas por los usuarios asi, la BD information schema cuenta con 28 tablas de las cuales las mas importantes son: Schemata - donde se encuentra almacenada informacin referida alas BD de mysql, el juego de caracteres. Tables aca se encuentra la informacin de todas las tablas de DBMS, donde se puede apreciar que la informacin almacenda correponde por ejemplo a: Table Schema: DB a la cual pertence la tabla. Table Name: el nombre de la tabla. Table Type: Tipo de tabla Enginne: puede ser INNODB, MySAM, CVS, etc. Table Row: almacena la cantidad de columnas que tiene la tabla Create Time, Update Time, Check Time: almacena la hora y el dia en que se realizaron cualquiera de estas operaciones sobre la tabla. Table constraints - aca se encuentra las relaciones entre las tablas, almacena informacin sobre las claves si es primario o fornea. Table privileges - los privilegios de los usuarios sobre la tablas. triggers - almacena la informacin de los triggers, que se ejecutan sobre la tablas. users Privileges - Alamcena las acciones de los usuarios sobre las tablas o las DB, que son los privilegios de usuario, es decir que acciones pueden hacer sobre las tablas. columns aca se guarda la informacin sobre las columnas de todas las DB, el nombre de la misma, a que tabla pertenece, a que DB, el tipo de dato que almacena char, text, integer, etc. Ademas si pueden ser nulo o no, privilegios sobre esas columnas.
XIII. TRANSACCIONES
A continuacin detallaremos paso a paso las configuraciones que deben hacerse en el motor para generar y activar el archivo de transacciones en WAMP.
Para comenzar debemos hacer clic con el botn secundario en la base de datos que deseamos usar como base de datos primaria en la configuracin del trasvase de registros y, a continuacin, hacemos clic en Propiedades como se muestra en la figura.
A continuacin nos muestra en la ventana Seleccionar una pgina, hacemos clic en Trasvase de registro de transacciones. Activamos la casilla de verificacin Habilitar sta como base de datos primaria en una configuracin de trasvase de registros.
En la opcin Copias de seguridad de registros de transacciones, hacemos clic en Configuracin de copia de seguridad. En el cuadro Ruta de red a esta carpeta de copia de seguridad, escribimos la ruta de acceso de red al recurso compartido que cre para la carpeta de copias de seguridad de los registros de transacciones.
Si la carpeta de copias de seguridad se encuentra en el servidor primario, escribimos la ruta de acceso local a la carpeta de copias de seguridad en el cuadro Si la carpeta de
copia de seguridad est ubicada en el servidor primario, escribimos una ruta local a la carpeta (si la carpeta de copias de seguridad no est situada en el servidor primario, podemos dejar este cuadro vaco). Configuramos los parmetros Eliminar archivos con ms de y Mostrar una alerta si no se produce una copia de seguridad tras. Tenemos que tener en cuenta la programacin de copia de seguridad que aparece en el cuadro Programacin bajo Trabajo de copia de seguridad. Si queremos podemos personalizar la programacin de su instalacin, a continuacin, hacemos clic en Programar y ajustamos la programacin del Agente SQL Server segn nuestras necesidades. Hacemos clic en Aceptar. En Instancias de servidores secundarios y bases de datos, hacemos clic en Agregar.
Hacemos clic en Conectar y nos conectamos a la instancia de SQL Server que queremos utilizar como servidor secundario.
En el cuadro Base de datos secundaria, elegimos una base de datos de la lista o escribimos el nombre de la base de datos que deseamos crear. En la ficha Inicializar base de datos secundaria, elegimos la opcin que deseamos utilizar para inicializar la base de datos secundaria. En la ficha Copiar archivos, en el cuadro Carpeta de destino de los archivos copiados, escribimos la ruta de acceso de la carpeta en la que deben copiarse las copias de seguridad de los registros de transacciones. Esta carpeta normalmente est situada en el servidor secundario. Tenemos que tener en cuenta la programacin de copia que aparece en el cuadro Programacin bajo Trabajo de copia. Si deseamos personalizar la programacin de la instalacin, hacemos clic en Programar y, a continuacin, ajustamos la programacin del Agente SQL Server segn nuestras necesidades. Esta programacin debe aproximarse a la programacin de las copias de seguridad. En la ficha Restaurar, en Estado de la base de datos al restaurar copias de seguridad, elegimos la opcin Modo sin recuperacin o Modo de espera. Si elegimos la opcin Modo de espera, seleccionamos si deseamos desconectar a los usuarios de la base de datos secundaria mientras se realiza la operacin de restauracin. Si queremos retrasar el proceso de restauracin en el servidor secundario, elegimos un tiempo de retraso en Retrasar la restauracin de las copias de seguridad al menos. Elegimos un umbral de alerta en Mostrar una alerta si no se produce una restauracin tras. Tenemos que tener en cuenta la programacin de la restauracin que aparece en el cuadro Programacin bajo Trabajo de restauracin. Si queremos personalizar la programacin de la instalacin, hacemos clic en Programar y, a continuacin, ajustamos la programacin del Agente SQL Server segn sus necesidades. Esta programacin debe aproximarse a la programacin de las copias de seguridad. A continuacin hacemos clic en Aceptar.
En Instancia del servidor de supervisin, activamos la casilla de verificacin Utilizar una instancia del servidor de supervisin y, a continuacin, hacemos clic en Configuracin. Luego hacemos clic en Conectar y nos conectamos a la instancia de SQL Server que queremos utilizar como servidor de supervisin. En Supervisar conexiones, seleccionamos el mtodo de conexin que utilizarn los trabajos de copia de seguridad, copia y restauracin para conectarse al servidor de supervisin. En Retencin de historial, seleccionamos el perodo de tiempo que queremos retener un registro del historial de trasvase de registros. Luego hacemos clic en Aceptar. En el cuadro de dilogo Propiedades de la base de datos, hacemos clic en Aceptar para comenzar el proceso de configuracin.
Archivos de Transacciones Tabla del servidor principal
Procedimientos almacenados del servidor principal
Procedimiento almacenado
Descripcin
sp_add_log_shipping_p Configura la base de datos principal de una configuracin de rimary_database trasvase de registros, incluido el trabajo de copia de seguridad, el registro de monitor local y el registro de monitor remoto. sp_add_log_shipping_p Agrega un nombre de base de datos secundaria a una base rimary_secondary de datos principal existente. sp_change_log_shippin Cambia la configuracin de la base de datos principal g_primary_database incluidos los registros de monitor local y remoto. sp_cleanup_log_shippi ng_history Limpia el historial localmente y en el monitor basndose en el perodo de retencin.
sp_delete_log_shipping Quita el trasvase de registros de la base de datos principal, _primary_database incluido el trabajo de copia de seguridad as como el historial local y remoto. sp_delete_log_shipping Quita el nombre de una base de datos secundaria de una _primary_secondary principal. sp_help_log_shipping_ primary_database Recupera la configuracin de la base de datos principal y muestra los valores de las tablaslog_shipping_primary_databases ylog_shipping_mo nitor_primary. Recupera los nombres de las bases de datos secundarias para una principal. Actualiza el monitor con la informacin ms reciente del agente de trasvase de registros especificado.
sp_help_log_shipping_ primary_secondary sp_refresh_log_shippin g_monitor
Tablas de servidor secundario Tabla log_shipping_monitor_alert Descripcin Almacena los Id. de trabajos de alerta. Esta tabla slo se utiliza en el servidor secundario si no se ha configurado un servidor de supervisin remoto. Almacena los detalles de error de los trabajos de trasvase de registros asociados con este servidor secundario.
log_shipping_monitor_error_detail
log_shipping_monitor_history_detail Almacena los detalles de historial de los trabajos de
trasvase de registros asociados con este servidor secundario. log_shipping_monitor_secondary Almacena un registro de monitor por cada base de datos secundaria asociada con este servidor secundario. Incluye informacin de configuracin de las bases de datos secundarias de un servidor determinado. Incluye una fila por Id. secundario.
log_shipping_secondary
log_shipping_secondary_databases Almacena informacin de configuracin de una base de datos secundaria determinada. Incluye una fila por base de datos secundaria.
Procedimientos almacenados del servidor secundario Procedimiento almacenado Descripcin
sp_add_log_shipping_secondary Configura una base de datos secundaria para el _database trasvase de registros. sp_add_log_shipping_secondary Configura informacin principal, agrega vnculos al _primary monitor local y remoto y crea trabajos de copia y restauracin en el servidor secundario de la base de datos principal especificada. sp_change_log_shipping_secon dary_database sp_change_log_shipping_secon dary_primary sp_cleanup_log_shipping_histor y sp_delete_log_shipping_second ary_database sp_delete_log_shipping_second ary_primary sp_help_log_shipping_secondar y_database Cambia la configuracin de la base de datos secundaria incluidos los registros de monitor local y remoto. Cambia la configuracin de la base de datos secundaria como el directorio de origen y destino o el perodo de retencin de los archivos. Limpia el historial localmente y en el monitor basndose en el perodo de retencin. Quita una base de datos secundaria y los historiales local y remoto. Quita la informacin acerca del servidor principal especificado del servidor secundario. Recupera la configuracin de la base de datos secundaria de las tablas log_shipping_secondary,log_shipping_secon dary_databases ylog_shipping_monitor_secondary. Este procedimiento almacenado recupera la configuracin de una base de datos principal determinada en el servidor secundario.
sp_help_log_shipping_secondar y_primary
sp_refresh_log_shipping_monito Actualiza el monitor con la informacin ms reciente del
agente de trasvase de registros especificado.
Tablas de servidor de supervisin Tabla log_shipping_monitor_alert Descripcin Almacena los Id. de trabajo de alerta
log_shipping_monitor_error_deta Almacena los detalles de error de los trabajos de il trasvase de registros. log_shipping_monitor_history_de Almacena los detalles de historial de los trabajos de tail trasvase de registros. log_shipping_monitor_primary Almacena un registro de monitor por cada base de datos principal asociada con este servidor de supervisin.
log_shipping_monitor_secondary Almacena un registro de monitor por cada base de datos secundaria asociada con este servidor de supervisin.
Procedimientos almacenados del servidor de supervisin Procedimiento almacenado sp_add_log_shipping_alert_job sp_delete_log_shipping_alert_jo b sp_help_log_shipping_alert_job Descripcin Crea un trabajo de alerta de trasvase de registros si an no se ha creado ninguno. Quita un trabajo de alerta de trasvase de registros si no hay ninguna base de datos principal asociada. Devuelve el Id. del trabajo de alerta.
sp_help_log_shipping_monitor_p Devuelve los registros de monitor de la base de datos rimary principal especificada de la tabla log_shipping_monitor_primary. sp_help_log_shipping_monitor_s Devuelve los registros de monitor de la base de datos econdary secundaria especificada de la tablalog_shipping_monitor_secondary.
Procedimientos que se deben hacer para recuperar informacin a un punto determinado del transaccional Para determinar los procedimientos que se deben hacer para recuperar la informacin en a un punto determinado del transaccional, debemos utilizar la opcin Intervalo de recuperacin. Esta nos permite establecer el nmero mximo de minutos por cada base de datos que Microsoft SQL Server necesita para recuperarlas. Cada vez que se inicia una instancia de SQL
Server, recupera cada una de las bases de datos, revierte las transacciones que no se confirmaron y pone al da las transacciones que s se confirmaron pero cuyos cambios no se haban escrito an en el disco cuando se detuvo la instancia de SQL Server. Esta opcin de configuracin establece un lmite superior para el tiempo de recuperacin de cada base de datos. El valor predeterminado es 0, que indica que SQL Server configura el tiempo automticamente. En la prctica, esto significa un tiempo de recuperacin inferior a un minuto y un punto de comprobacin aproximadamente cada minuto para bases de datos activas. Para establecer el intervalo de recuperacin debemos hacer lo siguiente: En el Explorador de objetos, hacemos clic con el botn secundario del mouse en un servidor y seleccionamos Propiedades. Luego hacemos clic en el nodo Configuracin de base de datos. En Recuperacin, en el cuadro Intervalo de recuperacin (min), escribimos o seleccionamos un valor entre 0 y 32.767 para establecer el tiempo mximo, en minutos, que SQL Server debe emplear en recuperar cada base de datos cuando se inicia. El valor predeterminado es 0, lo que indica una configuracin automtica.
XIV. SISTEMAS DE ALMACENAMIENTO QUE EXISTEN EN EL MERCADO A NIVEL HW Y TECNOLOGA MS SEGURA PARA DATOS DE UN DBMS. (SE CONSIDERA A SAN: STORAGE AREA NETWORK)
El mtodo preferido de almacenamientosimplemente depende de las necesidades de la empresa y la infraestructura existente. La funcionalidad de un NAS y SAN son muy similares, sin embargo hay diferencias tcnicas entre un NAS y un SAN: NAS identifica los datos por nombre de archivo y desplazamientos de bytes, transferencias de archivos de datos o un archivo de metadatos (propietario del archivo, los permisos, los datos de creacin, etc), y se ocupa de la seguridad, la autenticacin de usuario, bloqueo de archivos. SAN addressesidentifies datos por nmero de bloque de disco y pide bloques transferencias primas normalmente a travs de disco SCSI.
Un NAS consiste en un dispositivo de almacenamiento o una combinacin de mltiples dispositivos de almacenamiento conectados a la red de rea local existente (LAN). Un NAS sirve para descargar los datos valiosos de la empresa en una ubicacin de almacenamiento a que todava est fcilmente accesible por el archivo y servidores de aplicaciones a travs de la LAN corporativa. Una tpica solucin NAS consiste en un servidor dedicado para compartir archivos en la red con una conexin TCP/IP. SSR212MA de Intel a dispositivos de almacenamiento NAS de soluciones permite ms espacio de disco duro que se aade a una red que ya utiliza servidores principales para otras aplicaciones. El dispositivo de Intel entrega los datos al usuario por la red LAN existente. No es necesario para el dispositivo de Intel que se encuentra en un servidor determinado. Puede existir en cualquier lugar de una LAN con varios dispositivos NAS.
Una SAN se compone de dispositivos de almacenamiento que son conectados en red (histricamente a travs de un backbone de fibra de velocidad-alta) separada de la LAN corporativa existente.Mtodo principal de Intel SSR212MA SAN Storage Server para conectar con el almacenamiento es iSCSI. Una SAN es una sub-red de alta velocidad de dispositivos dealmacenamiento compartido (mquinas que contienen nada ms que los discos para almacenar datos) que todava se puede acceder por los usuarios a travs de archivos y servidores de aplicaciones. El SSR212MA puede hacer todos los dispositivos de almacenamiento disponibles para todos los servidores en una LAN o red de rea amplia (WAN). Cuando los dispositivos de almacenamiento se agregan al servidor Intel SAN, que se puede acceder desde cualquier servidor de la red. Adems, la capacidad de almacenamiento se puede agregar al sistema de almacenamiento SAN, segn sea necesario sin intrusiones en la red corporativa. El servidor de Intel es un puente entre los datos almacenados y el usuario final.
Seguridad
La seguridad en las SAN ha sido desde el principio un factor fundamental, es por ello que se ha implementado la tecnologa de zonificacin, la cual consiste en que un grupo de elementos se aslen del resto para evitar estos problemas, la zonificacin puede llevarse a cabo por hardware, software o ambas, siendo capaz de agrupar por puerto o por WWN (World Wide Name), una tcnica adicional se implementa a nivel del dispositivo de almacenamiento que es la Presentacin, consiste en hacer que una LUN (LogicalUnitNumber) sea accesible slo por una lista predefinida de servidores o nodos (se implementa con los WWN) Componentes
Los componentes de una SAN son: switches, directores, HBAs, Servidores, Ruteadores, Gateways, Matrices de discos y Libreras de cintas. Topologa
Cada topologa provee distintas capacidades y beneficios las topologas de SAN son: Cascada (cascade) Anillo (ring) Malla (meshed) Ncleo/borde (core/edge) Intel SSR212MC2NA Storage System Hard Drive Array Caractersticas Device Type: Hard Drive Array Enclosure Type: Rack Mountable, 2U Max Supported Capacity: 9 TB Interface: ISCSI
Supported Drives: Serial ATA-300 / SAS Storage Controller: Serial Attached SCSI ( Serial ATA-300 / SAS ) Hard Drive: 0 Hot Swap Serial ATA-300 / SAS Cabina de almacenamiento Dell EqualLogic PS6010S SAN iSCSI de categora superior compatible con 10 GbE y discos de estado slido (SSD) Rendimiento mejorado con discos SSD y consolidacin de entornos de sobremesas virtuales Idneo para aplicaciones sensibles a la latencia Almacenamiento fiable para las cargas de trabajo empresariales ms importantes Gestin eficiente de los datos empresariales y reduccin del coste total de mantenimiento con un conjunto de software con todo incluido SAN iSCSI Dell EqualLogic PS6000S La EqualLogic PS6000S constituye un mtodo sencillo y asequible para proporcionar las ventajas de rendimiento de baja latencia que presenta la tecnologa SSD a sus exigentes aplicaciones. Con esta arquitectura de almacenamiento virtualizada por niveles, la serie PS6000S se puede combinar con cualquier SAN de EqualLogic. Una dcima parte de la latencia de una cabina SAS a 15.000 rpm Rendimiento de lectura y escritura aleatorio de hasta tres veces superior que una cabina SAS a 15.000 rpm Ampliacin con otras cabinas PS6000S para tener un rendimiento de SSD adicional o para conseguir una SAN por niveles Esquema de optimizacin de la BD mediante grupos de archivos con RAID basados en HD. RAID 0 (Data Striping)
Un RAID 0 (tambin llamado conjunto dividido o volumen dividido) distribuye los datos equitativamente entre dos o ms discos sin informacin de paridad que proporcione redundancia. Es importante sealar que el RAID 0 no era uno de los niveles RAID originales y que no es redundante. El RAID 0 se usa normalmente para incrementar el rendimiento, aunque tambin puede utilizarse como forma de crear un pequeo nmero de grandes discos virtuales a partir de un gran nmero de pequeos discos fsicos. Un RAID 0 puede ser creado con discos de diferentes tamaos, pero el espacio de almacenamiento aadido al conjunto estar limitado por el tamao del disco ms pequeo (por ejemplo, si un disco de 300 GB se
divide con uno de 100 GB, el tamao del conjunto resultante ser slo de 200 GB, ya que cada disco aporta 100GB). Una buena implementacin de un RAID 0 dividir las operaciones de lectura y escritura en bloques de igual tamao, por lo que distribuir la informacin equitativamente entre los dos discos. Tambin es posible crear un RAID 0 con ms de dos discos, si bien, la fiabilidad del conjunto ser igual a la fiabilidad media de cada disco entre el nmero de discos del conjunto; es decir, la fiabilidad total medida como MTTF o MTBF es (aproximadamente) inversamente proporcional al nmero de discos del conjunto (pues para que el conjunto falle es necesario que lo hagan cualquiera de sus discos). RAID 1
Un RAID 1 crea una copia exacta (o espejo) de un conjunto de datos en dos o ms discos. Esto resulta til cuando el rendimiento en lectura es ms importante que la capacidad. Un conjunto RAID 1 slo puede ser tan grande como el ms pequeo de sus discos. Un RAID 1 clsico consiste en dos discos en espejo, lo que incrementa exponencialmente la fiabilidad respecto a un solo disco; es decir, la probabilidad de fallo del conjunto es igual al producto de las probabilidades de fallo de cada uno de los discos (pues para que el conjunto falle es necesario que lo hagan todos sus discos). Adicionalmente, dado que todos los datos estn en dos o ms discos, con hardware habitualmente independiente, el rendimiento de lectura se incrementa aproximadamente como mltiplo lineal del nmero del copias; es decir, un RAID 1 puede estar leyendo simultneamente dos datos diferentes en dos discos diferentes, por lo que su rendimiento se duplica. Para maximizar los beneficios sobre el rendimiento del RAID 1 se recomienda el uso de controladoras de disco independientes, una para cada disco (prctica que algunos denominan splitting o duplexing). Como en el RAID 0, el tiempo medio de lectura se reduce, ya que los sectores a buscar pueden dividirse entre los discos, bajando el tiempo de bsqueda y subiendo la tasa de transferencia, con el nico lmite de la velocidad soportada por la controladora RAID. Sin embargo, muchas tarjetas RAID 1 IDE antiguas leen slo de un disco de la pareja, por lo que su rendimiento es igual al de un nico disco. Algunas implementaciones RAID 1 antiguas tambin leen de ambos discos simultneamente y comparan los datos para detectar errores. La deteccin y correccin de errores en los discos duros modernos hacen esta prctica poco til. Al escribir, el conjunto se comporta como un nico disco, dado que los datos deben ser escritos en todos los discos del RAID 1. Por tanto, el rendimiento no mejora. El RAID 1 tiene muchas ventajas de administracin. Por ejemplo, en algunos entornos 24/7, es posible dividir el espejo: marcar un disco como inactivo, hacer una copia de seguridad de dicho disco y luego reconstruir el espejo. Esto requiere que la aplicacin de gestin del conjunto soporte la recuperacin de los datos del disco en el momento de la divisin. Este procedimiento es menos crtico que la presencia de una caracterstica de snapshot en algunos sistemas de archivos, en la que se reserva algn espacio para los cambios, presentando una vista esttica en un punto temporal dado del sistema de archivos. Alternativamente, un conjunto de discos puede ser almacenado de forma parecida a como se hace con las tradicionales cintas.
RAID 2
Un RAID 2 divide los datos a nivel de bits en lugar de a nivel de bloques y usa un cdigo de Hamming para la correccin de errores. Los discos son sincronizados por la controladora para funcionar al unsono. ste es el nico nivel RAID original que actualmente no se usa. Permite tasas de trasferencias extremadamente altas. Tericamente, un RAID 2 necesitara 39 discos en un sistema informtico moderno: 32 se usaran para almacenar los bits individuales que forman cada palabra y 7 se usaran para la correccin de errores. RAID 3
Diagrama de una configuracin RAID 3. Cada nmero representa un byte de datos; cada columna, un disco. Un RAID 3 usa divisin a nivel de bytes con un disco de paridad dedicado. El RAID 3 se usa rara vez en la prctica. Uno de sus efectos secundarios es que normalmente no puede atender varias peticiones simultneas, debido a que por definicin cualquier simple bloque de datos se dividir por todos los miembros del conjunto, residiendo la misma direccin dentro de cada uno de ellos. As, cualquier operacin de lectura o escritura exige activar todos los discos del conjunto. En el ejemplo del grfico, una peticin del bloque A formado por los bytes A1 a A6 requerira que los tres discos de datos buscaran el comienzo (A1) y devolvieran su contenido. Una peticin simultnea del bloque B tendra que esperar a que la anterior concluyese. RAID 4
Diagrama de una configuracin RAID 4. Cada nmero representa un bloque de datos; cada columna, un disco.
Un RAID 4 usa divisin a nivel de bloques con un disco de paridad dedicado. Necesita un mnimo de 3 discos fsicos. El RAID 4 es parecido al RAID 3 excepto porque divide a nivel de bloques en lugar de a nivel de bytes. Esto permite que cada miembro del conjunto funcione independientemente cuando se solicita un nico bloque. Si la controladora de disco lo permite, un conjunto RAID 4 puede servir varias peticiones de lectura simultneamente. En principio tambin sera posible servir varias peticiones de escritura simultneamente, pero al estar toda la informacin de paridad en un solo disco, ste se convertira en el cuello de botella del conjunto. En el grfico de ejemplo anterior, una peticin del bloque A1 sera servida por el disco 0. Una peticin simultnea del bloque B1 tendra que esperar, pero una peticin de B2 podra atenderse concurrentemente. RAID 5
Un RAID 5 usa divisin de datos a nivel de bloques distribuyendo la informacin de paridad entre todos los discos miembros del conjunto. El RAID 5 ha logrado popularidad gracias a su bajo coste de redundancia. Generalmente, el RAID 5 se implementa con soporte hardware para el clculo de la paridad. En el grfico de ejemplo anterior, una peticin de lectura del bloque A1 sera servida por el disco 0. Una peticin de lectura simultnea del bloque B1 tendra que esperar, pero una peticin de lectura de B2 podra atenderse concurrentemente ya que seria servida por el disco 1. Cada vez que un bloque de datos se escribe en un RAID 5, se genera un bloque de paridad dentro de la misma divisin (stripe). Un bloque se compone a menudo de muchos sectores consecutivos de disco. Una serie de bloques (un bloque de cada uno de los discos del conjunto) recibe el nombre colectivo de divisin (stripe). Si otro bloque, o alguna porcin de un bloque, son escritos en esa misma divisin, el bloque de paridad (o una parte del mismo) es recalculada y vuelta a escribir. El disco utilizado por el bloque de paridad est escalonado de una divisin a la siguiente, de ah el trmino bloques de paridad distribuidos. Las escrituras en un RAID 5 son costosas en trminos de operaciones de disco y trfico entre los discos y la controladora. Los bloques de paridad no se leen en las operaciones de lectura de datos, ya que esto sera una sobrecarga innecesaria y disminuira el rendimiento. Sin embargo, los bloques de paridad se leen cuando la lectura de un sector de datos provoca un error de CRC. En este caso, el sector en la misma posicin relativa dentro de cada uno de los bloques de datos restantes en la divisin y dentro del bloque de paridad en la divisin se utiliza para reconstruir el sector errneo. El error CRC se oculta as al resto del sistema. De la misma forma, si falla un disco del conjunto, los bloques de paridad de los restantes discos son combinados matemticamente con los bloques de datos de los restantes discos para reconstruir los datos del disco que ha fallado al vuelo. Lo anterior se denomina a veces Modo Interino de Recuperacin de Datos (Interim Data RecoveryMode). El sistema sabe que un disco ha fallado, pero slo con el fin de que el sistema operativo pueda notificar al administrador que una unidad necesita ser reemplazada: las aplicaciones en ejecucin siguen funcionando ajenas al fallo. Las lecturas y escrituras continan normalmente en el conjunto de discos, aunque con alguna degradacin de
rendimiento. La diferencia entre el RAID 4 y el RAID 5 es que, en el Modo Interno de Recuperacin de Datos, el RAID 5 puede ser ligeramente ms rpido, debido a que, cuando el CRC y la paridad estn en el disco que fall, los clculos no tienen que realizarse, mientras que en el RAID 4, si uno de los discos de datos falla, los clculos tienen que ser realizados en cada acceso. El RAID 5 requiere al menos tres unidades de disco para ser implementado. El fallo de un segundo disco provoca la prdida completa de los datos. El nmero mximo de discos en un grupo de redundancia RAID 5 es tericamente ilimitado, pero en la prctica es comn limitar el nmero de unidades. Los inconvenientes de usar grupos de redundancia mayores son una mayor probabilidad de fallo simultneo de dos discos, un mayor tiempo de reconstruccin y una mayor probabilidad de hallar un sector irrecuperable durante una reconstruccin. A medida que el nmero de discos en un conjunto RAID 5 crece, el MTBF (tiempo medio entre fallos) puede ser ms bajo que el de un nico disco. Esto sucede cuando la probabilidad de que falle un segundo disco en los N-1 discos restantes de un conjunto en el que ha fallado un disco en el tiempo necesario para detectar, reemplazar y recrear dicho disco es mayor que la probabilidad de fallo de un nico disco. Una alternativa que proporciona una proteccin de paridad dual, permitiendo as mayor nmero de discos por grupo, es el RAID 6. Algunos vendedores RAID evitan montar discos de los mismos lotes en un grupo de redundancia para minimizar la probabilidad de fallos simultneos al principio y el final de su vida til. Las implementaciones RAID 5 presentan un rendimiento malo cuando se someten a cargas de trabajo que incluyen muchas escrituras ms pequeas que el tamao de una divisin (stripe). Esto se debe a que la paridad debe ser actualizada para cada escritura, lo que exige realizar secuencias de lectura, modificacin y escritura tanto para el bloque de datos como para el de paridad. Implementaciones ms complejas incluyen a menudo cachs de escritura no voltiles para reducir este problema de rendimiento. En el caso de un fallo del sistema cuando hay escrituras activas, la paridad de una divisin (stripe) puede quedar en un estado inconsistente con los datos. Si esto no se detecta y repara antes de que un disco o bloque falle, pueden perderse datos debido a que se usar una paridad incorrecta para reconstruir el bloque perdido en dicha divisin. Esta potencial vulnerabilidad se conoce a veces como agujero de escritura. Son comunes el uso de cach no voltiles y otras tcnicas para reducir la probabilidad de ocurrencia de esta vulnerabilidad. RAID 6
Diagrama de una configuracin RAID 6. Cada nmero representa un bloque de datos; cada columna, un disco; p y q, cdigos Reed-Solomon. Un RAID 6 ampla el nivel RAID 5 aadiendo otro bloque de paridad, por lo que divide los datos a nivel de bloques y distribuye los dos bloques de paridad entre todos los miembros del conjunto. El RAID 6 no era uno de los niveles RAID originales. El RAID 6 puede ser considerado un caso especial de cdigo Reed-Solomon. El RAID 6, siendo un caso degenerado, exige slo sumas en elcampo de Galois.Dado que se est operando sobre
bits, lo que se usa es un campo binario de Galois ( ). En las representaciones cclicas de los campos binarios de Galois, la suma se calcula con un simple XOR. Tras comprender el RAID 6 como caso especial de un cdigo Reed-Solomon, se puede ver que es posible ampliar este enfoque para generar redundancia simplemente produciendo otro cdigo, tpicamente un polinomio en (m = 8 significa que estamos operando sobre bytes). Al aadir cdigos adicionales es posible alcanzar cualquier nmero de discos redundantes, y recuperarse de un fallo de ese mismo nmero de discos en cualquier puntos del conjunto, pero en el nivel RAID 6 se usan dos nicos cdigos. Al igual que en el RAID 5, en el RAID 6 la paridad se distribuye en divisiones (stripes), con los bloques de paridad en un lugar diferente en cada divisin. El RAID 6 es ineficiente cuando se usa un pequeo nmero de discos pero a medida que el conjunto crece y se dispone de ms discos la prdida en capacidad de almacenamiento se hace menos importante, creciendo al mismo tiempo la probabilidad de que dos discos fallen simultneamente. El RAID 6 proporciona proteccin contra fallos dobles de discos y contra fallos cuando se est reconstruyendo un disco. En caso de que slo tengamos un conjunto puede ser ms adecuado que usar un RAID 5 con un disco de reserva (hotspare). La capacidad de datos de un conjunto RAID 6 es n-2, siendo n el nmero total de discos del conjunto. Un RAID 6 no penaliza el rendimiento de las operaciones de lectura, pero s el de las de escritura debido al proceso que exigen los clculos adicionales de paridad. Esta penalizacin puede minimizarse agrupando las escrituras en el menor nmero posible de divisiones (stripes), lo que puede lograrse mediante el uso de un sistema de archivos WAFL.
Las tablas (de metadatos) que estn relacionadas con los usuarios Los usuarios en Wamp server se pueden gestionan a travs de la base de datos llamada MySQL concretamente con la tabla user. Ac podemos observar mediante la aplicacin PHPMyAdmin que es una herramienta que provee para cualquier tabla de base de datos. Tambin se pueden dar de altas a usuarios, permisos de creacin de storedprocedure, mxima cantidad de filas para actualizar, etc. En este caso se puede manejar la parte de seguridad de base de datos en la cual se muestra en la siguiente pantalla.
Usuarios que vienen creados con el DBMS y la funcin de cada uno El usuario que viene creado por defecto es el userroot: este usuario tiene privilegio para realizar todas las operaciones sobre la base de datos. Este usuario solo puede acceder al motor de base de datos desde la mquina local pero se puede modificar la configuracin para dar acceso que no sea desde un equipo local.
Usuarios en el motor utilizando Grant, Rovoke y Deny para dar accesos y denegar sobre objetos y sentencias (insert, create, etc)
Para dar de alta a un nuevo usuario debemos insertar un nuevo registro para esto ingresamos en la pestaa Insertar. Host: determina el host desde el cual el usuario puede conectar a la db por defecto ponemos localhost pero se puede poner una IP con la terminal que tenga acceso. Usuario: nombre del usuario con el cual queremos conectar Password:Es la contrasea del usuario encriptado con la funcin password (CLAVE) Se puede observar que tiene un grupo de checkbox que determinan las operaciones que pueden realizar para este caso habilitaremos para que el usuario pueda realizar INSERT/DELETE y UPDATE solamente sobre tablas
De esta manera el usuario est restringido a realizar las operaciones bsicas de INSERT/DELETE y UPDATE no teniendo permisos de creacin de tablas, trigger, vista u storedprocedure.
XV. CONCLUSIN
Durante la realizacin de este trabajo vamos a enumerar en unas series de items nuestras conclusiones: Con el trabajo desarrollado para la aprobacin de la materia se alcanzo el objetivo propuesto por la ctedra. Como trabajo de esta materia realizada nos permiti afianzar los conocimientos de un administrador de base de datos y mejorar nuestra formacin como ingeniero.
No solo realizamos el trabajo para la aprobacin de la materia que nos sirvi para aplicar nuestros conocimientos sino que tambin adquirimos una serie de nuevos conocimientos. Por ltimo con todo este trabajo que se ha realizado El Sistema de Gestin Estratgico de Farmacia ha podido adquirir un valor agregado que incluye el esquema base para la construccin del sistema informtico, un alto grado de seguridad de los datos que va a manejar y una gran flexibilidad para afrontar los nuevos requerimientos que se puedan presentar.
XVI. REFERENCIAS [1] La Biblia del MySQL Autor: Lan Gilfilan Editor: ANAYA Multimedia. [2] Java How to Program, Autor: By H. M. Deitel - Deitel & Associates, Inc., P. J. Deitel - Deitel & Associates, Inc. Sixth Edition. http://www.mysql.com/ http://www.netbeans.org/ http://www.oracle.com/technetwork/java/javase/downloads/index.html http://jasperforge.org/projects/ireport
Vous aimerez peut-être aussi
- Cuestionario Grupo 4 Basede Datos RelacionalDocument12 pagesCuestionario Grupo 4 Basede Datos RelacionalJOSE MARIA COCA PEREIRAPas encore d'évaluation
- Formato Ieee 1362 Ejemplo 1Document43 pagesFormato Ieee 1362 Ejemplo 1Lewis Cordoba0% (3)
- Tran Soft ManualDocument16 pagesTran Soft ManualAlejandro MendezPas encore d'évaluation
- DN ExFfinalDocument21 pagesDN ExFfinalMarceloPas encore d'évaluation
- TEMA 6 Despliegue en Entornos WAMP-LAMPPDocument44 pagesTEMA 6 Despliegue en Entornos WAMP-LAMPPjavierroman1997Pas encore d'évaluation
- Sistemas Gestores BDDocument6 pagesSistemas Gestores BDOscar Miguel100% (1)
- 10 Sistemas Gestores de Base de DatosDocument29 pages10 Sistemas Gestores de Base de DatosAnonymous QhIkYBPas encore d'évaluation
- SENADocument16 pagesSENAAndrés MejiaPas encore d'évaluation
- Manual Eagle1Document32 pagesManual Eagle1Youkkat SamiPas encore d'évaluation
- Trabajo Final de Administración de Sistema de Información 1Document18 pagesTrabajo Final de Administración de Sistema de Información 1Ambar RodriguezPas encore d'évaluation
- Actualizar PHP 7 A 8Document20 pagesActualizar PHP 7 A 8Jaime GarcíaPas encore d'évaluation
- Programa Programación Con PHP y MySQLDocument3 pagesPrograma Programación Con PHP y MySQLSEBASTIANPas encore d'évaluation
- Caso - Practico - Gestion - Del - Sistema Telefonico de Un Locutorio PDFDocument39 pagesCaso - Practico - Gestion - Del - Sistema Telefonico de Un Locutorio PDFlopezmoleonPas encore d'évaluation
- Manual de Usuarios Modulo DenunciaDocument14 pagesManual de Usuarios Modulo DenunciaMauris AvilaPas encore d'évaluation
- SIGES ManualTecnicoDocument14 pagesSIGES ManualTecnicojose nuñezPas encore d'évaluation
- Syllabus Diplomado2020 2 Academia MovilesDocument8 pagesSyllabus Diplomado2020 2 Academia MovilesAbel SalazarPas encore d'évaluation
- Informe de Practicas - Ministerio de ProduccionDocument72 pagesInforme de Practicas - Ministerio de ProduccionEvelinCoahPas encore d'évaluation
- Cuenca Balanza Ruben PerfilDocument16 pagesCuenca Balanza Ruben PerfiljadielPas encore d'évaluation
- Manual Elgg en LinuxDocument21 pagesManual Elgg en Linuxjhoncanabi1Pas encore d'évaluation
- Práctica II MySQL and NavicatDocument15 pagesPráctica II MySQL and NavicatSpaik SPPas encore d'évaluation
- Glab - S09 - Dapaza - 2022-02 (Web)Document25 pagesGlab - S09 - Dapaza - 2022-02 (Web)Miluska Tatiana Laquise UgartePas encore d'évaluation
- Semana 1 - PDF - Ejemplo de Proyecto Final PillofonDocument61 pagesSemana 1 - PDF - Ejemplo de Proyecto Final PillofonErick Requiz de la CruzPas encore d'évaluation
- Curriculum Wilberth AyalaDocument2 pagesCurriculum Wilberth AyalawiliheroPas encore d'évaluation
- Informe TesisDocument209 pagesInforme TesisIgnacioZamoranoPerezPas encore d'évaluation
- Tema 3 - Acceso A BD Desde PHPDocument36 pagesTema 3 - Acceso A BD Desde PHPCarlosHEPas encore d'évaluation
- Administracion de Base de DtosDocument18 pagesAdministracion de Base de DtosAna Gabriela Mendoz'aPas encore d'évaluation
- Manejadores de Sistemas de Bases de DatosDocument27 pagesManejadores de Sistemas de Bases de DatosnereidathompsonPas encore d'évaluation
- Plan Estratégico de Tecnologías de Información de PerupetroDocument27 pagesPlan Estratégico de Tecnologías de Información de PerupetroiTzSydPas encore d'évaluation
- ABD 08 UNIDAD II TransaccionesDocument25 pagesABD 08 UNIDAD II Transaccionesyulery AnchundiaPas encore d'évaluation
- 5.1 Instalacion y Configuracion Mysql 5.5Document10 pages5.1 Instalacion y Configuracion Mysql 5.5Willian Cualchi MonterosPas encore d'évaluation