Vous aimerez peut-être aussi
- Solution of Data Structure ST-2 PDFDocument21 pagesSolution of Data Structure ST-2 PDFharshitPas encore d'évaluation
- DNN ALL Practical 28Document34 pagesDNN ALL Practical 284073Himanshu PatlePas encore d'évaluation
- Title: Implement Support Vector Machine Classifier: Department of Computer Science and EngineeringDocument5 pagesTitle: Implement Support Vector Machine Classifier: Department of Computer Science and EngineeringreilyshawnPas encore d'évaluation
- Chapter 3Document7 pagesChapter 3pavithrPas encore d'évaluation
- Assignment 2 With ProgramDocument8 pagesAssignment 2 With ProgramPalash SarowarePas encore d'évaluation
- Multiclass Recognition With Multiple Feature TreesDocument7 pagesMulticlass Recognition With Multiple Feature TreesCS & ITPas encore d'évaluation
- It-3031 (DMDW) - CS End Nov 2023Document23 pagesIt-3031 (DMDW) - CS End Nov 202321051796Pas encore d'évaluation
- ML Lab 11 Manual - Neural Networks (Ver4)Document8 pagesML Lab 11 Manual - Neural Networks (Ver4)dodela6303Pas encore d'évaluation
- Time Series Prediction With Recurrent Neural NetworksDocument7 pagesTime Series Prediction With Recurrent Neural Networksghoshayan1003Pas encore d'évaluation
- Convolution Neural Network: CP - 6 Machine Learning M S PrasadDocument37 pagesConvolution Neural Network: CP - 6 Machine Learning M S PrasadMani S Prasad100% (1)
- BakaDocument85 pagesBakaM NarendranPas encore d'évaluation
- NotesDocument5 pagesNotesSneha GowdaPas encore d'évaluation
- An Improved K-Means Algorithm Based On Mapreduce and Grid: Li Ma, Lei Gu, Bo Li, Yue Ma and Jin WangDocument12 pagesAn Improved K-Means Algorithm Based On Mapreduce and Grid: Li Ma, Lei Gu, Bo Li, Yue Ma and Jin WangjefferyleclercPas encore d'évaluation
- Artigo SmallexDocument17 pagesArtigo SmallexWill CorleonePas encore d'évaluation
- LFD 2005 Nearest NeighbourDocument6 pagesLFD 2005 Nearest NeighbourAnahi SánchezPas encore d'évaluation
- Machine LearningDocument46 pagesMachine Learningsussy.rebab19787Pas encore d'évaluation
- DS&a Lab Manual OrignalDocument94 pagesDS&a Lab Manual OrignalMemona LatifPas encore d'évaluation
- Solution First Point ML-HW4Document6 pagesSolution First Point ML-HW4Juan Sebastian Otálora Montenegro100% (1)
- Sihem JebariDocument10 pagesSihem JebariSihem JebariPas encore d'évaluation
- HW 3Document5 pagesHW 3AbbasPas encore d'évaluation
- Advantages:: Q.No 1.a AnsDocument12 pagesAdvantages:: Q.No 1.a AnsTiwari VivekPas encore d'évaluation
- Machine Learning (ML) :: Aim: Analysis and Implementation of Deep Neural Network. DefinitionsDocument6 pagesMachine Learning (ML) :: Aim: Analysis and Implementation of Deep Neural Network. DefinitionsVishal LuniaPas encore d'évaluation
- Introduction To Deep Learning Assignment 0: September 2023Document3 pagesIntroduction To Deep Learning Assignment 0: September 2023christiaanbergsma03Pas encore d'évaluation
- Oop Unit-3&4Document17 pagesOop Unit-3&4ZINKAL PATELPas encore d'évaluation
- AgnesDocument25 pagesAgnesDyah Septi AndryaniPas encore d'évaluation
- Data Structures and Algorithms - Chapter 1 - LMS2020Document28 pagesData Structures and Algorithms - Chapter 1 - LMS2020Balleta Mark Jay NorcioPas encore d'évaluation
- PythonfileDocument36 pagesPythonfilecollection58209Pas encore d'évaluation
- 10.3 One-Dimensional Search With First DerivativesDocument4 pages10.3 One-Dimensional Search With First DerivativesRajivSadewaPas encore d'évaluation
- Learning Complex Boolean Functions: Algorithms and ApplicationsDocument8 pagesLearning Complex Boolean Functions: Algorithms and ApplicationsMario Betanzos UnamPas encore d'évaluation
- Insem2 SchemeDocument6 pagesInsem2 SchemeBalathrinath ReddyPas encore d'évaluation
- Oefentt Jaar 3Document11 pagesOefentt Jaar 3Branco SieljesPas encore d'évaluation
- TY DS ADS Lab ManualDocument61 pagesTY DS ADS Lab ManualShreya JadhavPas encore d'évaluation
- Lab3Block1 2021-1Document3 pagesLab3Block1 2021-1Alex WidénPas encore d'évaluation
- Tutorial 6Document8 pagesTutorial 6POEASOPas encore d'évaluation
- IJRET - Scalable and Efficient Cluster-Based Framework For Multidimensional IndexingDocument5 pagesIJRET - Scalable and Efficient Cluster-Based Framework For Multidimensional IndexingInternational Journal of Research in Engineering and TechnologyPas encore d'évaluation
- Kernel MethodDocument37 pagesKernel MethodNisha KamarajPas encore d'évaluation
- Lecture 2: Basics and Definitions: Networks As Data ModelsDocument28 pagesLecture 2: Basics and Definitions: Networks As Data ModelsshardapatelPas encore d'évaluation
- Fast Training of Multilayer PerceptronsDocument15 pagesFast Training of Multilayer Perceptronsgarima_rathiPas encore d'évaluation
- GDBSCANDocument30 pagesGDBSCANkkoushikgmailcomPas encore d'évaluation
- Coincent - Data Science With Python AssignmentDocument23 pagesCoincent - Data Science With Python AssignmentSai Nikhil Nellore100% (2)
- E9 205 - Machine Learning For Signal ProcessingDocument3 pagesE9 205 - Machine Learning For Signal Processingrishi guptaPas encore d'évaluation
- Storage Technologies: Digital Assignment 1Document16 pagesStorage Technologies: Digital Assignment 1Yash PawarPas encore d'évaluation
- Evaluation of Different ClassifierDocument4 pagesEvaluation of Different ClassifierTiwari VivekPas encore d'évaluation
- Remember Java Data Types: October 24, 2005Document23 pagesRemember Java Data Types: October 24, 2005hdrzaman9439Pas encore d'évaluation
- ML Unit-5Document8 pagesML Unit-5Supriya alluriPas encore d'évaluation
- Chapter Parallel Prefix SumDocument21 pagesChapter Parallel Prefix SumAimee ReynoldsPas encore d'évaluation
- ML Lab - Sukanya RajaDocument23 pagesML Lab - Sukanya RajaRick MitraPas encore d'évaluation
- Chandigarh Group of Colleges College of Engineering Landran, MohaliDocument47 pagesChandigarh Group of Colleges College of Engineering Landran, Mohalitanvi wadhwaPas encore d'évaluation
- An Initial Seed Selection AlgorithmDocument11 pagesAn Initial Seed Selection Algorithmhamzarash090Pas encore d'évaluation
- Homework Exercise 4: Statistical Learning, Fall 2020-21Document3 pagesHomework Exercise 4: Statistical Learning, Fall 2020-21Elinor RahamimPas encore d'évaluation
- 134 Faster Cnns With Direct SparseDocument11 pages134 Faster Cnns With Direct SparseTampolenPas encore d'évaluation
- Chapter - 1: 1.1 OverviewDocument50 pagesChapter - 1: 1.1 Overviewkarthik0484Pas encore d'évaluation
- EX. No:1 Implementation of Graph Search AlgorithmsDocument55 pagesEX. No:1 Implementation of Graph Search AlgorithmsHexa RajasekarPas encore d'évaluation
- Noise Robust Classification Based On Spread Spectrum - ICDM - 08Document10 pagesNoise Robust Classification Based On Spread Spectrum - ICDM - 08Jörn DavidPas encore d'évaluation
- Ing, Prentice-Hall, Inc., Englewood Cliffs, New Jersey, 1984Document39 pagesIng, Prentice-Hall, Inc., Englewood Cliffs, New Jersey, 1984Sagor KhanPas encore d'évaluation
- Algorithm Its Clustering: DetectingDocument11 pagesAlgorithm Its Clustering: DetectingqqqqqPas encore d'évaluation
- Machine Learning: E0270 2015 Assignment 4: Due March 24 Before ClassDocument3 pagesMachine Learning: E0270 2015 Assignment 4: Due March 24 Before ClassMahesh YadaPas encore d'évaluation
- Team Members Register No: Class B.Tech (Cse) Year 2 YR Batch 2019-2023 SubjectDocument11 pagesTeam Members Register No: Class B.Tech (Cse) Year 2 YR Batch 2019-2023 SubjectSrisowmiya NPas encore d'évaluation
- HW 7Document4 pagesHW 7adithya604Pas encore d'évaluation
- Advanced C Concepts and Programming: First EditionD'EverandAdvanced C Concepts and Programming: First EditionÉvaluation : 3 sur 5 étoiles3/5 (1)
- Fabrication of High Speed Indication and Automatic Pneumatic Braking SystemDocument7 pagesFabrication of High Speed Indication and Automatic Pneumatic Braking Systemseventhsensegroup0% (1)
- Implementation of Single Stage Three Level Power Factor Correction AC-DC Converter With Phase Shift ModulationDocument6 pagesImplementation of Single Stage Three Level Power Factor Correction AC-DC Converter With Phase Shift ModulationseventhsensegroupPas encore d'évaluation
- Design, Development and Performance Evaluation of Solar Dryer With Mirror Booster For Red Chilli (Capsicum Annum)Document7 pagesDesign, Development and Performance Evaluation of Solar Dryer With Mirror Booster For Red Chilli (Capsicum Annum)seventhsensegroupPas encore d'évaluation
- Ijett V5N1P103Document4 pagesIjett V5N1P103Yosy NanaPas encore d'évaluation
- FPGA Based Design and Implementation of Image Edge Detection Using Xilinx System GeneratorDocument4 pagesFPGA Based Design and Implementation of Image Edge Detection Using Xilinx System GeneratorseventhsensegroupPas encore d'évaluation
- An Efficient and Empirical Model of Distributed ClusteringDocument5 pagesAn Efficient and Empirical Model of Distributed ClusteringseventhsensegroupPas encore d'évaluation
- Non-Linear Static Analysis of Multi-Storied BuildingDocument5 pagesNon-Linear Static Analysis of Multi-Storied Buildingseventhsensegroup100% (1)
- Analysis of The Fixed Window Functions in The Fractional Fourier DomainDocument7 pagesAnalysis of The Fixed Window Functions in The Fractional Fourier DomainseventhsensegroupPas encore d'évaluation
- Ijett V4i10p158Document6 pagesIjett V4i10p158pradeepjoshi007Pas encore d'évaluation
- Design and Implementation of Multiple Output Switch Mode Power SupplyDocument6 pagesDesign and Implementation of Multiple Output Switch Mode Power SupplyseventhsensegroupPas encore d'évaluation
- Experimental Analysis of Tobacco Seed Oil Blends With Diesel in Single Cylinder Ci-EngineDocument5 pagesExperimental Analysis of Tobacco Seed Oil Blends With Diesel in Single Cylinder Ci-EngineseventhsensegroupPas encore d'évaluation
- Editar Menu Contextual OperaDocument7 pagesEditar Menu Contextual OperaPedro José Suárez TorrealbaPas encore d'évaluation
- Topic Wise MCQ of Operating SystemsDocument27 pagesTopic Wise MCQ of Operating SystemsRuba NiaziPas encore d'évaluation
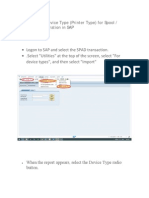
- How To Import Device Type in SAPDocument4 pagesHow To Import Device Type in SAPMuhammad ShoaibPas encore d'évaluation
- MA5600T MA5603T V800R010C00 Feature DescriptionDocument824 pagesMA5600T MA5603T V800R010C00 Feature DescriptionCutui MariusPas encore d'évaluation
- ProjectDocument22 pagesProjectSandeep SharmaPas encore d'évaluation
- Free Tiktok Followers Generator and Follower Bot For Tiktok and TynaDocument4 pagesFree Tiktok Followers Generator and Follower Bot For Tiktok and Tynaandrei ninciuleanuPas encore d'évaluation
- BarcodeDocument24 pagesBarcodeChidgana Hegde100% (1)
- Which of The Following Enables You To Monitor and Collect Log Files From Your Amazon EC2 Instances?Document4 pagesWhich of The Following Enables You To Monitor and Collect Log Files From Your Amazon EC2 Instances?ulysses_ramosPas encore d'évaluation
- How Cloud Computing Changed The WorldDocument35 pagesHow Cloud Computing Changed The WorldAshutosh SinghPas encore d'évaluation
- DP-8060 ServiceManual Ver.1.4Document955 pagesDP-8060 ServiceManual Ver.1.4Brad Hepper100% (3)
- What Is SitecoreDocument9 pagesWhat Is SitecoreKhaliq RehmanPas encore d'évaluation
- Dewan Mohammad Mahbubur RahmanDocument3 pagesDewan Mohammad Mahbubur RahmanMustafa Hussain100% (1)
- Lab Manual For CCNPDocument180 pagesLab Manual For CCNPblck bxPas encore d'évaluation
- UNIX Concepts: 1. How Are Devices Represented in UNIX?Document15 pagesUNIX Concepts: 1. How Are Devices Represented in UNIX?api-3764166Pas encore d'évaluation
- Auslogics Windows Slimmer LicenseDocument3 pagesAuslogics Windows Slimmer LicensemahamedPas encore d'évaluation
- GemFire Introduction Hands-On LabsDocument19 pagesGemFire Introduction Hands-On LabsNoelle JPas encore d'évaluation
- LU CroutDocument21 pagesLU CroutGregory WestPas encore d'évaluation
- ARM Instruction SetDocument25 pagesARM Instruction SetShivam JainPas encore d'évaluation
- CS2103 - T - Week 3 - TopicsDocument32 pagesCS2103 - T - Week 3 - TopicsQianhui QiuPas encore d'évaluation
- Coding BiodataDocument4 pagesCoding BiodataYoga Aji PratamaPas encore d'évaluation
- Release Note ACP 5103 PDFDocument14 pagesRelease Note ACP 5103 PDFuser proPas encore d'évaluation
- Catalog Modicon M221 Programmable Logic Controller - February 2023Document27 pagesCatalog Modicon M221 Programmable Logic Controller - February 2023Edgardo RivasPas encore d'évaluation
- Service Manual: Prosound Α6Document128 pagesService Manual: Prosound Α6Thanh HàPas encore d'évaluation
- Sorting Algorithms - PresentationDocument32 pagesSorting Algorithms - PresentationSuleiman Gargaare0% (1)
- CP 340 ManualDocument212 pagesCP 340 Manualthuong_hanPas encore d'évaluation
- Heliyon: Sathish Pasika, Sai Teja GandlaDocument9 pagesHeliyon: Sathish Pasika, Sai Teja GandlaAuras PopescuPas encore d'évaluation
- Project Tracker DocumentationDocument51 pagesProject Tracker DocumentationbhanuchandraPas encore d'évaluation
- MVC - Entity Framework - SQL Server-1Document56 pagesMVC - Entity Framework - SQL Server-1Mohan RaviPas encore d'évaluation
- Installation OS400 - Double Take - AS400 - IBM IDocument58 pagesInstallation OS400 - Double Take - AS400 - IBM IAdrianaSerriPas encore d'évaluation
- SMART DAS Solutions Ver01Document79 pagesSMART DAS Solutions Ver01Anup Kumar40% (5)