Vous aimerez peut-être aussi
- Fans Reference GuideDocument160 pagesFans Reference Guidekarthikraja21100% (13)
- Exponential & Logarithmic FunctionsDocument13 pagesExponential & Logarithmic FunctionsRahul SankaranPas encore d'évaluation
- Centrifugal Compressor Operation and MaintenanceDocument16 pagesCentrifugal Compressor Operation and MaintenanceNEMSPas encore d'évaluation
- Mitsubishi diesel forklifts 1.5-3.5 tonnesDocument2 pagesMitsubishi diesel forklifts 1.5-3.5 tonnesJoniPas encore d'évaluation
- 12 Animation Q1 AnswerDocument38 pages12 Animation Q1 AnswerBilly Joe TanPas encore d'évaluation
- 04.protection of 33KV Feeder.Document16 pages04.protection of 33KV Feeder.gnpr_10106080Pas encore d'évaluation
- (2Nd and Revised Edition) S F Borg-Earthquake Engineering - Mechanism, Damage Assessment and Structural Design-Wspc (1988)Document347 pages(2Nd and Revised Edition) S F Borg-Earthquake Engineering - Mechanism, Damage Assessment and Structural Design-Wspc (1988)Haddad samirPas encore d'évaluation
- Vtol Design PDFDocument25 pagesVtol Design PDFElner CrystianPas encore d'évaluation
- Grade 5 Mtap Compilation 2011,2013 2015 2016 2017 Division OralsDocument5 pagesGrade 5 Mtap Compilation 2011,2013 2015 2016 2017 Division OralsChristine De San JosePas encore d'évaluation
- 000 200 1210 Guidelines For Minimum Deliverables 3 November 2011Document22 pages000 200 1210 Guidelines For Minimum Deliverables 3 November 2011Raul Bautista100% (1)
- Asoc Published PDFDocument15 pagesAsoc Published PDFCESAR CANEOPas encore d'évaluation
- Journal of Computer Applications - WWW - Jcaksrce.org - Volume 4 Issue 2Document3 pagesJournal of Computer Applications - WWW - Jcaksrce.org - Volume 4 Issue 2Journal of Computer ApplicationsPas encore d'évaluation
- An Improved K-Means Clustering Algorithm For Global Earthquake Catalogs and Earthquake Magnitude PredictionDocument16 pagesAn Improved K-Means Clustering Algorithm For Global Earthquake Catalogs and Earthquake Magnitude PredictionCaller Ex.2Pas encore d'évaluation
- Improving Earthquake Prediction With Principal Component Analysis: Application To ChileDocument13 pagesImproving Earthquake Prediction With Principal Component Analysis: Application To ChileLohit KPas encore d'évaluation
- Prediction of Response Spectra Via Real-Time Earthquake MeasurementsDocument14 pagesPrediction of Response Spectra Via Real-Time Earthquake MeasurementsKurinjivelan PalaniyandiPas encore d'évaluation
- Seismic Hazard Zonation of Catalonia, Spain, Integrating Random UncertaintiesDocument16 pagesSeismic Hazard Zonation of Catalonia, Spain, Integrating Random UncertaintiesdharmPas encore d'évaluation
- CONESCAPAN 2022 Paper 24741Document6 pagesCONESCAPAN 2022 Paper 24741HICHAM LAHMAIDIPas encore d'évaluation
- Fast EEW Algorithm Using 3s P-Wave CodaDocument13 pagesFast EEW Algorithm Using 3s P-Wave CodaMARIA DEL CARMEN RIOS PEREAPas encore d'évaluation
- Earthquake Final Report PRINTDocument52 pagesEarthquake Final Report PRINTManickavasagamPas encore d'évaluation
- Ahumada Et Al-Expert SystemsDocument42 pagesAhumada Et Al-Expert SystemsSudip ShresthaPas encore d'évaluation
- 2015 - 05 AAS Predict Magnitude Earthquakes BGTA 2015Document30 pages2015 - 05 AAS Predict Magnitude Earthquakes BGTA 2015Nurmal ItaPas encore d'évaluation
- Solar Radiation Prediction For Dimensioning Photovoltaic Systems Using Artificial Neural NetworksDocument9 pagesSolar Radiation Prediction For Dimensioning Photovoltaic Systems Using Artificial Neural NetworksfloraPas encore d'évaluation
- Isprsannals II 5 289 2014Document7 pagesIsprsannals II 5 289 2014Iván PuentePas encore d'évaluation
- Design of A Unified Scale For The Characterization of Seismic ActivityDocument16 pagesDesign of A Unified Scale For The Characterization of Seismic ActivityInternational Journal of Innovative Science and Research TechnologyPas encore d'évaluation
- PIP920 FinalDocument14 pagesPIP920 FinalDaniel OsPas encore d'évaluation
- Statistical Modeling For Global Solar Radiation Forecasting in Bogota PDFDocument6 pagesStatistical Modeling For Global Solar Radiation Forecasting in Bogota PDFOmar VillarrealPas encore d'évaluation
- ANN Prediction of Reservoir Water LevelDocument3 pagesANN Prediction of Reservoir Water LevelMOHAMAD AFIQ ASHRAF AMRANPas encore d'évaluation
- 20202579029-Angie Moreno (Comparación de Modelos de Regresión y Redes Neuronales para Estimar La Radiación Solar)Document8 pages20202579029-Angie Moreno (Comparación de Modelos de Regresión y Redes Neuronales para Estimar La Radiación Solar)Angie MorenoPas encore d'évaluation
- Time Series Prediction of Earthquake Input by Using Soft ComputingDocument6 pagesTime Series Prediction of Earthquake Input by Using Soft ComputingIlich_Garc_a_9133Pas encore d'évaluation
- Real-Time Earthquake Tracking and Localisation: A Formulation for Elements in Earthquake Early Warning Systems (Eews)D'EverandReal-Time Earthquake Tracking and Localisation: A Formulation for Elements in Earthquake Early Warning Systems (Eews)Pas encore d'évaluation
- First Physics News From The Cms Experiment at The LHCDocument14 pagesFirst Physics News From The Cms Experiment at The LHCperica21Pas encore d'évaluation
- Performance Evaluation of Earthquake Detection Algorithm Used by Mexico's Seismic Alert SystemDocument14 pagesPerformance Evaluation of Earthquake Detection Algorithm Used by Mexico's Seismic Alert SystemMARIA DEL CARMEN RIOS PEREAPas encore d'évaluation
- Seismic Risk in Sri LankaDocument11 pagesSeismic Risk in Sri LankaSusanthbuPas encore d'évaluation
- 7-MS-760 M ArifDocument11 pages7-MS-760 M ArifFarzana IsmailPas encore d'évaluation
- Application of Real Time GPS To Earthquake Early Warning: Richard M. Allen and Alon ZivDocument7 pagesApplication of Real Time GPS To Earthquake Early Warning: Richard M. Allen and Alon Zivmahnaz sabahiPas encore d'évaluation
- Aman Kaura Gurinder Singh Role of Simulation in Weather ForecastingDocument4 pagesAman Kaura Gurinder Singh Role of Simulation in Weather ForecastingHarmon CentinoPas encore d'évaluation
- MineriaDocument16 pagesMineriapaulPas encore d'évaluation
- Cipitech 09Document6 pagesCipitech 09mmm_rcPas encore d'évaluation
- Geophys. J. Int.-1994-Ordaz-335-44Document10 pagesGeophys. J. Int.-1994-Ordaz-335-44Alex VCPas encore d'évaluation
- Conference Paper - Coil Group 3Document7 pagesConference Paper - Coil Group 3RedPas encore d'évaluation
- 4 OLADE Risk Management Course Module 4 Climate ModelsDocument29 pages4 OLADE Risk Management Course Module 4 Climate ModelsCristian PerezPas encore d'évaluation
- Faccioli Et Al 2004 DDBDDocument30 pagesFaccioli Et Al 2004 DDBDLobsang MatosPas encore d'évaluation
- Bastias Et Al Evalu GMPEsDocument9 pagesBastias Et Al Evalu GMPEsAlejandro Patricio Maureira GomezPas encore d'évaluation
- C23 AgusDocument12 pagesC23 Aguskeke razkaPas encore d'évaluation
- The ISC Bulletin As A Comprehensive Source of Eart-1Document14 pagesThe ISC Bulletin As A Comprehensive Source of Eart-1afaf boudeboudaPas encore d'évaluation
- Comparing Predictive Power in Climate Data: Clustering MattersDocument17 pagesComparing Predictive Power in Climate Data: Clustering Mattersdiana hertantiPas encore d'évaluation
- Geomagnetic indices: derivation, meaning and availabilityDocument5 pagesGeomagnetic indices: derivation, meaning and availabilityShahbaz AhmadPas encore d'évaluation
- Dikshant EarthquakeDocument20 pagesDikshant EarthquakeDIKSHANT GHIMIREPas encore d'évaluation
- Takbash2018 - THE PREDICTION OF EXTREME VALUE WIND SPEEDS AND WAVE HEIGHTS FROMDocument1 pageTakbash2018 - THE PREDICTION OF EXTREME VALUE WIND SPEEDS AND WAVE HEIGHTS FROMsaenuddinPas encore d'évaluation
- George 2018Document23 pagesGeorge 2018Nikhil Arun KumarPas encore d'évaluation
- DownloadDocument9 pagesDownloadjimakosjpPas encore d'évaluation
- Study On Techniques of Earthquake Prediction: G.Preethi B.SanthiDocument4 pagesStudy On Techniques of Earthquake Prediction: G.Preethi B.Santhinadia8008Pas encore d'évaluation
- The H/V Spectral Ratio Technique: Experimental Conditions, Data Processing and Empirical Reliability AssessmentDocument12 pagesThe H/V Spectral Ratio Technique: Experimental Conditions, Data Processing and Empirical Reliability AssessmentGianfranco TacoPas encore d'évaluation
- InterpolationDocument7 pagesInterpolationluis moyaPas encore d'évaluation
- Environmental Science and Sustainable DevelopmentDocument8 pagesEnvironmental Science and Sustainable DevelopmentIEREK PressPas encore d'évaluation
- A Deep Learning Framework For The Detection of Tropical Cyclones From Satellite ImagesDocument5 pagesA Deep Learning Framework For The Detection of Tropical Cyclones From Satellite Imagestusharcool009Pas encore d'évaluation
- Project Compass 2 0 Preliminary AnalysisDocument24 pagesProject Compass 2 0 Preliminary AnalysisSorel BellasPas encore d'évaluation
- Jcea Jamaica PshaDocument23 pagesJcea Jamaica PshaDrift KingPas encore d'évaluation
- Short Term Load Forecasting Using Trend Information and Process ReconstructionDocument10 pagesShort Term Load Forecasting Using Trend Information and Process ReconstructiongsaibabaPas encore d'évaluation
- Ijettcs 2015 02 25 109Document5 pagesIjettcs 2015 02 25 109International Journal of Application or Innovation in Engineering & ManagementPas encore d'évaluation
- JGR Solid Earth - 2018 - Anantrasirichai - Application of Machine Learning To Classification of Volcanic Deformation inDocument15 pagesJGR Solid Earth - 2018 - Anantrasirichai - Application of Machine Learning To Classification of Volcanic Deformation insen duPas encore d'évaluation
- Remotesensing 12 02089 v2Document23 pagesRemotesensing 12 02089 v2Jashley VillalbaPas encore d'évaluation
- Background SubtractionDocument4 pagesBackground SubtractionlatecPas encore d'évaluation
- IJRET - Supervised Machine Learning Based Dynamic Estimation of Bulk Soil Moisture Using Cosmic Ray SensorDocument6 pagesIJRET - Supervised Machine Learning Based Dynamic Estimation of Bulk Soil Moisture Using Cosmic Ray SensorInternational Journal of Research in Engineering and TechnologyPas encore d'évaluation
- Identification of Rainfall Patterns Over The Valley of MexicoDocument9 pagesIdentification of Rainfall Patterns Over The Valley of MexicokamutmazPas encore d'évaluation
- A Fast Algorithm For Classifying Seismic Events Using Distributed Computations in Apache Spark FrameworkDocument14 pagesA Fast Algorithm For Classifying Seismic Events Using Distributed Computations in Apache Spark FrameworkLUIS JONATHAN RIVERA SUDARIOPas encore d'évaluation
- Lanari Et Al., 2018. Quantitative Compositional Mapping of Mineral Phases by Electron Probe Micro-Analyser PDFDocument25 pagesLanari Et Al., 2018. Quantitative Compositional Mapping of Mineral Phases by Electron Probe Micro-Analyser PDFAndrés FabiánPas encore d'évaluation
- Nonlinear Time Series Analysis of Volcanic Tremor Events Recorded at Sangay Volcano, EcuadorDocument19 pagesNonlinear Time Series Analysis of Volcanic Tremor Events Recorded at Sangay Volcano, EcuadorHania O. AlmdPas encore d'évaluation
- Pre-Earthquake Processes: A Multidisciplinary Approach to Earthquake Prediction StudiesD'EverandPre-Earthquake Processes: A Multidisciplinary Approach to Earthquake Prediction StudiesPas encore d'évaluation
- Material Balance of Naphtha Hydrotreater and Reformer ReactorsDocument22 pagesMaterial Balance of Naphtha Hydrotreater and Reformer ReactorsSukirtha GaneshanPas encore d'évaluation
- Product Presentation Nova Blood Gas AnalyzerDocument38 pagesProduct Presentation Nova Blood Gas Analyzerlaboratorium rsdmadani100% (1)
- DasibiOzoneMonitorManual 1008Document183 pagesDasibiOzoneMonitorManual 1008api-26966403100% (2)
- Efficiency Evaluation of The Ejector Cooling Cycle PDFDocument18 pagesEfficiency Evaluation of The Ejector Cooling Cycle PDFzoom_999Pas encore d'évaluation
- Solution of Homework 4Document4 pagesSolution of Homework 4Kamalakar Reddy100% (2)
- HowTo Work With CR 90Document87 pagesHowTo Work With CR 90WagBezerraPas encore d'évaluation
- PresiometroDocument25 pagesPresiometrojoseprepaPas encore d'évaluation
- Goniophotometer T1: OxytechDocument6 pagesGoniophotometer T1: OxytechGustavo CeccopieriPas encore d'évaluation
- Huawei Mediapad m5 10.8inch Ръководство За Потребителя (Cmr-Al09, 01, Neu)Document6 pagesHuawei Mediapad m5 10.8inch Ръководство За Потребителя (Cmr-Al09, 01, Neu)Галина ЦеноваPas encore d'évaluation
- Geotehnical Engg. - AEE - CRPQsDocument48 pagesGeotehnical Engg. - AEE - CRPQsSureshKonamPas encore d'évaluation
- 997-3 CIP Safety Adapter: Single Point Lesson (SPL) - Configure CIP Safety Adapter and A-B PLCDocument18 pages997-3 CIP Safety Adapter: Single Point Lesson (SPL) - Configure CIP Safety Adapter and A-B PLCTensaigaPas encore d'évaluation
- NewsDocument26 pagesNewsMaria Jose Soliz OportoPas encore d'évaluation
- Climate Change: The Fork at The End of NowDocument28 pagesClimate Change: The Fork at The End of NowMomentum Press100% (1)
- Seksioni I Kabllos Per Rrymat e Lidhjes Se ShkurteDocument1 pageSeksioni I Kabllos Per Rrymat e Lidhjes Se ShkurteDukagjin Ramqaj100% (1)
- © Ncert Not To Be Republished: AlgebraDocument12 pages© Ncert Not To Be Republished: Algebrakritagyasharma29Pas encore d'évaluation
- Reliability EngineeringDocument9 pagesReliability Engineeringnvaradharajan1971Pas encore d'évaluation
- R8557B KCGGDocument178 pagesR8557B KCGGRinda_RaynaPas encore d'évaluation
- PDS - GulfSea Hydraulic AW Series-1Document2 pagesPDS - GulfSea Hydraulic AW Series-1Zaini YaakubPas encore d'évaluation
- AND Optimization OF Three Existing Ethylbenzene Dehydrogenation Reactors in SeriesDocument5 pagesAND Optimization OF Three Existing Ethylbenzene Dehydrogenation Reactors in SeriesMuhammad Ridwan TanjungPas encore d'évaluation
- 1 05 Lab Crime Scene Sketch GADocument2 pages1 05 Lab Crime Scene Sketch GAthis is hardly gonna be usedPas encore d'évaluation
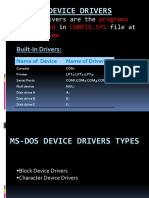
- Ms-Dos Device Drivers: Device Drivers Are The That in File atDocument13 pagesMs-Dos Device Drivers: Device Drivers Are The That in File atJass GillPas encore d'évaluation