Vous aimerez peut-être aussi
- A Home Buyer's Guide To A Seller's Market - WSJ PDFDocument8 pagesA Home Buyer's Guide To A Seller's Market - WSJ PDFkr0465Pas encore d'évaluation
- One Algorithm From The Book: A Tribute To Ira Pohl: Alexander StepanovDocument27 pagesOne Algorithm From The Book: A Tribute To Ira Pohl: Alexander Stepanovkr0465Pas encore d'évaluation
- 14 1120 Memo Business Actions PDFDocument5 pages14 1120 Memo Business Actions PDFkr0465Pas encore d'évaluation
- 2012 Workshop Tues NVME WindowsDocument27 pages2012 Workshop Tues NVME Windowskr0465Pas encore d'évaluation
- Exercise 1Document29 pagesExercise 1kr0465Pas encore d'évaluation
- NVM Express 1 - 1 PDFDocument163 pagesNVM Express 1 - 1 PDFkr0465Pas encore d'évaluation
- 00 AgendaDocument14 pages00 Agendaachilles7Pas encore d'évaluation
- Lesson 3 Data Storage and RetrievingDocument22 pagesLesson 3 Data Storage and Retrievingkr0465Pas encore d'évaluation
- AnilVasudeva NVMe NextGen SSD Interface-r1-Nc1Document25 pagesAnilVasudeva NVMe NextGen SSD Interface-r1-Nc1kr0465Pas encore d'évaluation
- SPC-4 ChangesDocument10 pagesSPC-4 Changeskr0465Pas encore d'évaluation
- 2 4 Errata ADocument2 296 pages2 4 Errata Akr0465Pas encore d'évaluation
- S5 Wolpers Friedrich U2x 4 PleDocument5 pagesS5 Wolpers Friedrich U2x 4 Plekr0465Pas encore d'évaluation
- NVMe SCSI TranslationDocument55 pagesNVMe SCSI Translationkr0465Pas encore d'évaluation
- Exam List Part 1Document9 pagesExam List Part 1kr0465Pas encore d'évaluation
- InfonoiseDocument37 pagesInfonoisekr0465Pas encore d'évaluation
- Pci Pcie FaqDocument14 pagesPci Pcie Faqkr0465Pas encore d'évaluation
- Info LecDocument139 pagesInfo Lecronics123Pas encore d'évaluation
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Openstack Compute DatasheetDocument4 pagesOpenstack Compute DatasheetRubén Alonso Cavieres CarvajalPas encore d'évaluation
- ECE 723 - Information Theory and CodingDocument23 pagesECE 723 - Information Theory and CodingHrishikesh VpPas encore d'évaluation
- 50 Years ShannonDocument22 pages50 Years Shannonkr0465Pas encore d'évaluation
- T REC H (1) .222.0 200403 I!Amd3!PDF EDocument28 pagesT REC H (1) .222.0 200403 I!Amd3!PDF Ekr0465Pas encore d'évaluation
- HandoutDocument7 pagesHandoutkr0465Pas encore d'évaluation
- A Quick Start Guide On Lua For C C ProgrammeDocument37 pagesA Quick Start Guide On Lua For C C Programmekr0465Pas encore d'évaluation
- EcdsaDocument35 pagesEcdsakr0465Pas encore d'évaluation
- Linux USB DriversDocument95 pagesLinux USB DriversFlorin AfilipoaeiPas encore d'évaluation
- GlobalPlatform TEE White Paper Feb2011Document26 pagesGlobalPlatform TEE White Paper Feb2011kr0465Pas encore d'évaluation
- Afi SamplesDocument20 pagesAfi SamplesEli Ben EliPas encore d'évaluation
- Paper 1498Document23 pagesPaper 1498kr0465Pas encore d'évaluation
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5783)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (72)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (119)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- Simulation of Lumbar Spine Biomechanics Using AbaqusDocument1 pageSimulation of Lumbar Spine Biomechanics Using AbaqusSIMULIACorpPas encore d'évaluation
- Lecture 07 - DebuggingDocument10 pagesLecture 07 - DebuggingKJ SaysPas encore d'évaluation
- PSSE ReferenceDocument66 pagesPSSE ReferenceeddisonfhPas encore d'évaluation
- Cryptex TutDocument15 pagesCryptex Tutaditya7398Pas encore d'évaluation
- Tapestry TutorialDocument48 pagesTapestry TutorialNarasimha RaoPas encore d'évaluation
- WWW - Goair.In: Go Airlines (India) LTDDocument2 pagesWWW - Goair.In: Go Airlines (India) LTDdhavalesh1Pas encore d'évaluation
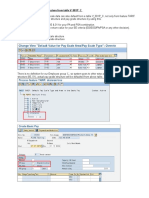
- Default Pay Scale/Grade Structure From Table V - 001P - CDocument7 pagesDefault Pay Scale/Grade Structure From Table V - 001P - CDeepa ShiligireddyPas encore d'évaluation
- Group 4 - Comm Rehab Comm Project Charter (EDIT Maryon)Document3 pagesGroup 4 - Comm Rehab Comm Project Charter (EDIT Maryon)Kool Bhardwaj33% (3)
- Features of Research ProfessionalDocument4 pagesFeatures of Research ProfessionalakanyilmazPas encore d'évaluation
- Health Informatics Course Overview and Learning ObjectivesDocument4 pagesHealth Informatics Course Overview and Learning ObjectivesYhaz VillaPas encore d'évaluation
- Shafhi Mohammad Vs The State of Himachal Pradesh On 30 January, 2018 PDFDocument4 pagesShafhi Mohammad Vs The State of Himachal Pradesh On 30 January, 2018 PDFSwaraj SiddhantPas encore d'évaluation
- VHDL Guidelines PDFDocument19 pagesVHDL Guidelines PDFrakheep123Pas encore d'évaluation
- Sathyabama: (Deemed To Be University)Document3 pagesSathyabama: (Deemed To Be University)viktahjmPas encore d'évaluation
- OpenSees Navigator GUIDocument52 pagesOpenSees Navigator GUIjames_frankPas encore d'évaluation
- Functions Summary: Domain RuleDocument2 pagesFunctions Summary: Domain RuleJiongHow SosadPas encore d'évaluation
- CAD/CAM Design and Manufacturing ProcessDocument14 pagesCAD/CAM Design and Manufacturing ProcessDanielRaoPas encore d'évaluation
- Swot MatrixDocument2 pagesSwot MatrixAltaf HussainPas encore d'évaluation
- Debugging RFC Calls From The XIDocument4 pagesDebugging RFC Calls From The XIManish SinghPas encore d'évaluation
- Chapter 2 MethodologyDocument11 pagesChapter 2 MethodologyRizalene AgustinPas encore d'évaluation
- KX-TES824 or KX-TA824 PC Programming Manual Up To Page 47 Out of 164Document47 pagesKX-TES824 or KX-TA824 PC Programming Manual Up To Page 47 Out of 164Lucas CoaquiraPas encore d'évaluation
- Manual Configuracion Easygen 3200 - 1Document448 pagesManual Configuracion Easygen 3200 - 1pabloPas encore d'évaluation
- Setting Up Adaptation Transport OrganizerDocument2 pagesSetting Up Adaptation Transport Organizerteejay.tarunPas encore d'évaluation
- Business PartnerDocument12 pagesBusiness PartnerNatraj Rangoju100% (1)
- How To Implement and Use ABAP Channels - Video ..Document3 pagesHow To Implement and Use ABAP Channels - Video ..abhilashPas encore d'évaluation
- Hynix Memory PDFDocument60 pagesHynix Memory PDFTobiasAngererPas encore d'évaluation
- Intel 440BX AGPset 82443BX Host BridgeController - Pdf.raw-Conversion - Utf-8Document244 pagesIntel 440BX AGPset 82443BX Host BridgeController - Pdf.raw-Conversion - Utf-8bokidxPas encore d'évaluation
- 1 Constrained Optimization: 1.1 Structure of The ProblemDocument4 pages1 Constrained Optimization: 1.1 Structure of The ProblemSam SmrdaPas encore d'évaluation
- Function Block & Organization Block: SiemensDocument14 pagesFunction Block & Organization Block: SiemensSofiane BenseghirPas encore d'évaluation
- Deep Blue MarketingDocument6 pagesDeep Blue MarketingdondegPas encore d'évaluation
- Optimize Oracle General Ledger average balances configurationDocument16 pagesOptimize Oracle General Ledger average balances configurationSingh Anish K.Pas encore d'évaluation