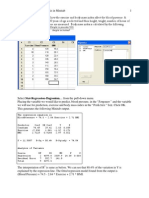
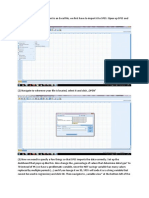
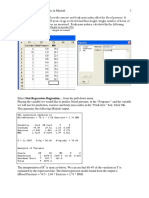
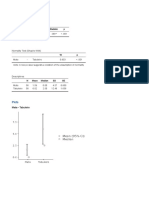
Vous aimerez peut-être aussi
- Problem Set 2 Quantitative Methods UNIGEDocument10 pagesProblem Set 2 Quantitative Methods UNIGEsancallonandez.95Pas encore d'évaluation
- Sales and AdvertisingDocument14 pagesSales and AdvertisingShaheen ZafarPas encore d'évaluation
- Regression Analysis Can Be Defined As The Process of Developing A MathematicalDocument21 pagesRegression Analysis Can Be Defined As The Process of Developing A MathematicalAmir Firdaus100% (1)
- Forecasting Techniques Chapter: Learn Linear Regression, Time Series, Index NumbersDocument44 pagesForecasting Techniques Chapter: Learn Linear Regression, Time Series, Index NumbersHamis MohamedPas encore d'évaluation
- Used BMW Prices Depend on Age and MileageDocument16 pagesUsed BMW Prices Depend on Age and Mileageamisha2562585Pas encore d'évaluation
- Salary Regression Explains College Degree ImpactDocument14 pagesSalary Regression Explains College Degree Impactamisha2562585Pas encore d'évaluation
- What Is Linear RegressionDocument14 pagesWhat Is Linear RegressionAvanijaPas encore d'évaluation
- Forecasting techniques for budgetsDocument15 pagesForecasting techniques for budgetspiyalhassanPas encore d'évaluation
- Analyze Dose-Response Curves & Compare ResultsDocument13 pagesAnalyze Dose-Response Curves & Compare ResultsSiti Zaleha RaduanPas encore d'évaluation
- BUS 5030 Module 4 - Problem Set Hypothesis Testing and Linear Regression WorksheDocument6 pagesBUS 5030 Module 4 - Problem Set Hypothesis Testing and Linear Regression WorksheDarlington OkonkwoPas encore d'évaluation
- Assignment IIDocument5 pagesAssignment IIsarah josephPas encore d'évaluation
- Statistical Inference, Regression SPSS ReportDocument73 pagesStatistical Inference, Regression SPSS ReportIjaz Hussain BajwaPas encore d'évaluation
- Data AnalysisDocument28 pagesData AnalysisDotRev Ibs100% (1)
- Minitab Simple Regression AnalysisDocument7 pagesMinitab Simple Regression AnalysisRadu VasilePas encore d'évaluation
- Marketing Engineering Notes Cover Response ModelsDocument46 pagesMarketing Engineering Notes Cover Response ModelsNeelesh KamathPas encore d'évaluation
- Report Group 8 FinalDocument13 pagesReport Group 8 FinalAnkit JaiswalPas encore d'évaluation
- Regression Analysis of Blood Pressure FactorsDocument6 pagesRegression Analysis of Blood Pressure FactorsEka Rahma Paramita100% (1)
- LR Predictors Hypertension SPSSDocument4 pagesLR Predictors Hypertension SPSSmushtaque61Pas encore d'évaluation
- Think Pair Share Team G1 - 7Document8 pagesThink Pair Share Team G1 - 7Akash Kashyap100% (1)
- Regression TutorialDocument5 pagesRegression TutorialBálint L'Obasso TóthPas encore d'évaluation
- Regression AnalysisDocument21 pagesRegression AnalysisAshish BaniwalPas encore d'évaluation
- Introduction To Sensitivity AnalysisDocument17 pagesIntroduction To Sensitivity AnalysisThảo UyênPas encore d'évaluation
- Lift Chart (Analysis Services - Data Mining)Document5 pagesLift Chart (Analysis Services - Data Mining)vlaresearchPas encore d'évaluation
- Linear Regression - Least-SquaresDocument5 pagesLinear Regression - Least-SquaresRongrong FuPas encore d'évaluation
- Regression AnalysisDocument3 pagesRegression AnalysisSumama IkhlasPas encore d'évaluation
- Linear Regression Analysis in ExcelDocument15 pagesLinear Regression Analysis in ExcelBertrand SomlarePas encore d'évaluation
- BSChem-Statistics in Chemical Analysis PDFDocument6 pagesBSChem-Statistics in Chemical Analysis PDFKENT BENEDICT PERALESPas encore d'évaluation
- Summarizing Lab Data with Descriptive StatisticsDocument6 pagesSummarizing Lab Data with Descriptive StatisticsLeon FouronePas encore d'évaluation
- Minitab Multiple Regression AnalysisDocument6 pagesMinitab Multiple Regression Analysisbuat akunPas encore d'évaluation
- Minitab Multiple Regression Analysis PDFDocument6 pagesMinitab Multiple Regression Analysis PDFBen GuhmanPas encore d'évaluation
- Econometrics Assignment Week 1-806979Document6 pagesEconometrics Assignment Week 1-806979jantien De GrootPas encore d'évaluation
- Regression Analysis: March 2014Document42 pagesRegression Analysis: March 2014Abhishek KansalPas encore d'évaluation
- Chapter 14 An Introduction To Multiple Linear Regression: No. of Emails % Discount Sales Customer X X yDocument9 pagesChapter 14 An Introduction To Multiple Linear Regression: No. of Emails % Discount Sales Customer X X yJayzie LiPas encore d'évaluation
- Linear Regression in 40 CharactersDocument21 pagesLinear Regression in 40 CharactersSweety 12Pas encore d'évaluation
- Quick and Dirty Regression TutorialDocument6 pagesQuick and Dirty Regression TutorialStefan Pius DsouzaPas encore d'évaluation
- Assignment - 1 - El - Ajouz CorrectionDocument9 pagesAssignment - 1 - El - Ajouz CorrectionMaroPas encore d'évaluation
- How Regression Predicts OutcomesDocument73 pagesHow Regression Predicts OutcomesjayroldparcedePas encore d'évaluation
- Regression Analysis in ExcelDocument20 pagesRegression Analysis in Excelsherryl caoPas encore d'évaluation
- Lecture Notes - Linear RegressionDocument26 pagesLecture Notes - Linear RegressionAmandeep Kaur GahirPas encore d'évaluation
- Excel FunctionsDocument28 pagesExcel FunctionskarunakaranPas encore d'évaluation
- Model Selection Loglinear Analysis ExplainedDocument4 pagesModel Selection Loglinear Analysis ExplainedGerónimo Maldonado-MartínezPas encore d'évaluation
- Topic 6 Mte3105Document9 pagesTopic 6 Mte3105Siva Piragash Mira BhaiPas encore d'évaluation
- Should A New Product Be IntroducedDocument7 pagesShould A New Product Be IntroducedMd. AsifPas encore d'évaluation
- Guiding PrinciplesDocument39 pagesGuiding PrinciplestiwariajaykPas encore d'évaluation
- Logistic RegressionDocument11 pagesLogistic RegressionGabriel DaneaPas encore d'évaluation
- FMD PRACTICAL FILEDocument61 pagesFMD PRACTICAL FILEMuskan AroraPas encore d'évaluation
- Linear Regression: What Is Regression Analysis?Document21 pagesLinear Regression: What Is Regression Analysis?sailusha100% (1)
- SSPSS Data Analysis Examples Poisson RegressionDocument34 pagesSSPSS Data Analysis Examples Poisson RegressionAhmad YangPas encore d'évaluation
- Regression AnalysisDocument17 pagesRegression AnalysisNk KumarPas encore d'évaluation
- EDA 4th ModuleDocument26 pagesEDA 4th Module205Abhishek KotagiPas encore d'évaluation
- Multiple Regression in SPSS: X X X y X X y X X yDocument13 pagesMultiple Regression in SPSS: X X X y X X y X X yRohit SikriPas encore d'évaluation
- Chapter 3&4 Lecture NotesDocument15 pagesChapter 3&4 Lecture NotesAshley ShepherdPas encore d'évaluation
- How To Build A Simple Demand Curve For A ProductDocument5 pagesHow To Build A Simple Demand Curve For A Productmsrron100% (3)
- Regression Explained SPSSDocument23 pagesRegression Explained SPSSAngel Sanu100% (1)
- Demand EstimationDocument27 pagesDemand EstimationAnonymous FmpblcLw0Pas encore d'évaluation
- Regression Analysis Linear and Multiple RegressionDocument6 pagesRegression Analysis Linear and Multiple RegressionPauline Kay Sunglao GayaPas encore d'évaluation
- Regression Analysis: Understanding Linear and Multiple Regression Models in 40 CharactersDocument6 pagesRegression Analysis: Understanding Linear and Multiple Regression Models in 40 CharactersPauline Kay Sunglao GayaPas encore d'évaluation
- Process Performance Models: Statistical, Probabilistic & SimulationD'EverandProcess Performance Models: Statistical, Probabilistic & SimulationPas encore d'évaluation
- Peran Humas Dalam Membentuk Citra Pemerintah: Evawani Elysa LubisDocument10 pagesPeran Humas Dalam Membentuk Citra Pemerintah: Evawani Elysa LubisAgnes FebrianaPas encore d'évaluation
- Soal Asi w7Document2 pagesSoal Asi w7Agnes FebrianaPas encore d'évaluation
- Stock Market Reaction To SEC Comment Letters PinS ReportDocument37 pagesStock Market Reaction To SEC Comment Letters PinS ReportAgnes FebrianaPas encore d'évaluation
- Soal Asi w6Document2 pagesSoal Asi w6Agnes FebrianaPas encore d'évaluation
- Soal ASIDocument2 pagesSoal ASIAgnes FebrianaPas encore d'évaluation
- Activity 5 - Measures of Central Tendency and VariabilityDocument5 pagesActivity 5 - Measures of Central Tendency and VariabilityGWYNETTE CAMIDCHOLPas encore d'évaluation
- EconometricsDocument25 pagesEconometricsLynda Mega SaputryPas encore d'évaluation
- Stat and ProbabDocument1 pageStat and Probabeden shane fortusPas encore d'évaluation
- Frequency Distribution, Cross-Tabulation, and Hypothesis TestingDocument4 pagesFrequency Distribution, Cross-Tabulation, and Hypothesis TestingThùyy VyPas encore d'évaluation
- Statistical Inference: Probability Distributions ExplainedDocument6 pagesStatistical Inference: Probability Distributions Explainedinaya khanPas encore d'évaluation
- Sampling Techniques ExplainedDocument72 pagesSampling Techniques ExplainedMohammed AbdelaPas encore d'évaluation
- Canonical CorrelationDocument44 pagesCanonical CorrelationLex AdiladPas encore d'évaluation
- Course Outline MATH 361 Probability and StatisticsDocument3 pagesCourse Outline MATH 361 Probability and StatisticsSkiwordy MediaPas encore d'évaluation
- Business Statistics Operations ResearchDocument8 pagesBusiness Statistics Operations ResearchSpank PrincePas encore d'évaluation
- Chapter 8 - Hypothesis TestingDocument90 pagesChapter 8 - Hypothesis TestingsamcareadamnPas encore d'évaluation
- Simple Linear RegressionDocument52 pagesSimple Linear RegressionTheGimhan123Pas encore d'évaluation
- Testul Chi PatratDocument9 pagesTestul Chi PatratgeorgianapetrescuPas encore d'évaluation
- Bayesian Lecture NotesDocument28 pagesBayesian Lecture NotesLIZPas encore d'évaluation
- Random VariableDocument19 pagesRandom VariableGemver Baula BalbasPas encore d'évaluation
- Melli Eliza (Kel - 10)Document18 pagesMelli Eliza (Kel - 10)RizkyPas encore d'évaluation
- Paired T-Test Results for Mata and TabuleiroDocument5 pagesPaired T-Test Results for Mata and TabuleiroJames Arturo Martinez GiraldoPas encore d'évaluation
- Answer: Script Cover SheetDocument17 pagesAnswer: Script Cover SheetParag Kumbhar07Pas encore d'évaluation
- AS Project ReportDocument22 pagesAS Project ReportLohitha PakalapatiPas encore d'évaluation
- 2a EDADocument11 pages2a EDASUMAN CHAUHANPas encore d'évaluation
- Weather and Climate Extremes: Eric M. La Amme, Ernst Linder, Yibin PanDocument9 pagesWeather and Climate Extremes: Eric M. La Amme, Ernst Linder, Yibin PanLuis AragonPas encore d'évaluation
- Homework8 Solutions EE131ADocument3 pagesHomework8 Solutions EE131AJohn TPas encore d'évaluation
- Business Statistics Communicating With Numbers 1st Edition Jaggia Test Bank DownloadDocument144 pagesBusiness Statistics Communicating With Numbers 1st Edition Jaggia Test Bank DownloadBernard Gulick100% (22)
- Gretl Guide (301 350)Document50 pagesGretl Guide (301 350)Taha NajidPas encore d'évaluation
- ThesisDocument8 pagesThesisdereckg_2Pas encore d'évaluation
- Solution Exercises List 2 Brownian Motion and Stochastic CalculusDocument9 pagesSolution Exercises List 2 Brownian Motion and Stochastic CalculusFrancis MtamboPas encore d'évaluation
- PJC h2 Math p2 SolutionsDocument7 pagesPJC h2 Math p2 SolutionsjimmytanlimlongPas encore d'évaluation
- Markov Chains ExplainedDocument51 pagesMarkov Chains ExplainedJessica TangPas encore d'évaluation
- IEOR E4525 Logistics 2017Document3 pagesIEOR E4525 Logistics 2017AngelaPas encore d'évaluation
- Lecture 4 Describing Variation & ProbabilityDocument22 pagesLecture 4 Describing Variation & ProbabilityDanang ArmanPas encore d'évaluation
- Information Theory and CodingDocument108 pagesInformation Theory and Codingsimodeb100% (2)