Vous aimerez peut-être aussi
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5795)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (74)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (400)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (121)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- EmulsionsDocument85 pagesEmulsionsRamchandra Keny100% (2)
- Acoustical Determinations On A Composite Materials (Extruded Polystyrene Type/ Cork)Document6 pagesAcoustical Determinations On A Composite Materials (Extruded Polystyrene Type/ Cork)pinoyarkiPas encore d'évaluation
- d17 Vega Using SqltraceDocument66 pagesd17 Vega Using SqltraceViorel PanaitePas encore d'évaluation
- An Introduction To Windows Communication FoundationDocument18 pagesAn Introduction To Windows Communication FoundationArdit MeziniPas encore d'évaluation
- Research Paper Two ColumnsDocument5 pagesResearch Paper Two Columnskgtyigvkg100% (1)
- NCP Risk For InfectionDocument2 pagesNCP Risk For InfectionI Am SmilingPas encore d'évaluation
- Pak Emergency Sukkur PDFDocument58 pagesPak Emergency Sukkur PDFNaeemullahPas encore d'évaluation
- Exam IDocument7 pagesExam IJoshMatthewsPas encore d'évaluation
- Memes As Participatory Politics: Understanding Internet Memes As A Form of American Political Culture in The 2016 United States Presidential ElectionDocument117 pagesMemes As Participatory Politics: Understanding Internet Memes As A Form of American Political Culture in The 2016 United States Presidential ElectionEmma Balfour91% (11)
- EBOOK IDEO - HCD - ToolKit PDFDocument200 pagesEBOOK IDEO - HCD - ToolKit PDFangy_brooksPas encore d'évaluation
- New Analytical Approach To Calculate The Melt Flow Within The Co-Rotating Twin Screw Extruder by Using The Performance Mapping MethodDocument6 pagesNew Analytical Approach To Calculate The Melt Flow Within The Co-Rotating Twin Screw Extruder by Using The Performance Mapping MethodGabriel PóvoaPas encore d'évaluation
- Micro Lab Act 2Document3 pagesMicro Lab Act 2RHINROMEPas encore d'évaluation
- Commercial Drafting and Detailing 4th Edition by Jefferis and Smith ISBN Solution ManualDocument8 pagesCommercial Drafting and Detailing 4th Edition by Jefferis and Smith ISBN Solution Manualmatthew100% (22)
- Srs TemplateDocument8 pagesSrs Templateferrys37Pas encore d'évaluation
- Simpson S RuleDocument13 pagesSimpson S RuleJunaid AhmedPas encore d'évaluation
- Rman Command DocumentDocument22 pagesRman Command DocumentanandPas encore d'évaluation
- Schumann Piano Concerto in A Minor Op 54 SM PDFDocument101 pagesSchumann Piano Concerto in A Minor Op 54 SM PDFMKGUPas encore d'évaluation
- Line Follower RobotDocument16 pagesLine Follower RobotVenkat Munnangi100% (1)
- Philosophy of Charlie Kaufman PDFDocument319 pagesPhilosophy of Charlie Kaufman PDFCherey Peña RojasPas encore d'évaluation
- Oracle Fusion Middleware Developer GuideDocument1 422 pagesOracle Fusion Middleware Developer GuideahsunPas encore d'évaluation
- Acknowledgemt: at The Outset of This Project, I Would Like To Express My Deep Gratitude To Mr. RajnishDocument6 pagesAcknowledgemt: at The Outset of This Project, I Would Like To Express My Deep Gratitude To Mr. RajnishPraveen SehgalPas encore d'évaluation
- Data Profiling OverviewDocument11 pagesData Profiling OverviewyprajuPas encore d'évaluation
- தசம பின்னம் ஆண்டு 4Document22 pagesதசம பின்னம் ஆண்டு 4Jessica BarnesPas encore d'évaluation
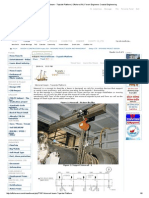
- Monorail Beam - Topside Platform - OffshoreDocument6 pagesMonorail Beam - Topside Platform - OffshoreBolarinwaPas encore d'évaluation
- xr602t Receiver ManualDocument7 pagesxr602t Receiver Manualrizky tantyoPas encore d'évaluation
- ReleaseNotes 30101R1 131015Document10 pagesReleaseNotes 30101R1 131015pnh mcsaPas encore d'évaluation
- Itil Intermediate Capability Stream:: Operational Support and Analysis (Osa) CertificateDocument33 pagesItil Intermediate Capability Stream:: Operational Support and Analysis (Osa) CertificateNitinPas encore d'évaluation
- Survey CompressedDocument394 pagesSurvey CompressedAjay PakharePas encore d'évaluation
- INVESTIGATION REPORT eFNCR 076 - BOP Test Plug Stuck in CHHDocument4 pagesINVESTIGATION REPORT eFNCR 076 - BOP Test Plug Stuck in CHHOmer Abd Al NasserPas encore d'évaluation
- MBDRDocument4 pagesMBDRenjoydasilencePas encore d'évaluation