Vous aimerez peut-être aussi
- Performance Analysis of Partition Algorithms For Parallel Solution of Nonlinear Systems of EquationsDocument4 pagesPerformance Analysis of Partition Algorithms For Parallel Solution of Nonlinear Systems of EquationsBlueOneGaussPas encore d'évaluation
- Determination of Modal Residues and Residual Flexibility For Time-Domain System RealizationDocument31 pagesDetermination of Modal Residues and Residual Flexibility For Time-Domain System RealizationSamagassi SouleymanePas encore d'évaluation
- Learning Reduced-Order Models of Quadratic Dynamical Systems From Input-Output DataDocument6 pagesLearning Reduced-Order Models of Quadratic Dynamical Systems From Input-Output Datasho bhaPas encore d'évaluation
- A Sparse Matrix Approach To Reverse Mode AutomaticDocument10 pagesA Sparse Matrix Approach To Reverse Mode Automaticgorot1Pas encore d'évaluation
- Analisis Matricial de Segundo OrdenDocument21 pagesAnalisis Matricial de Segundo OrdenZulma WaraPas encore d'évaluation
- Ij N×NDocument5 pagesIj N×NLaila Azwani PanjaitanPas encore d'évaluation
- Efficient Parallel Implementation of The Fox AlgorithmDocument8 pagesEfficient Parallel Implementation of The Fox Algorithmmariame8Pas encore d'évaluation
- Dynamic Analysis of A Car Chassis Frame Using The Finite Element MethodDocument10 pagesDynamic Analysis of A Car Chassis Frame Using The Finite Element MethodNir ShoPas encore d'évaluation
- DSP Implementation of Cholesky DecompositionDocument4 pagesDSP Implementation of Cholesky DecompositionNayim MohammadPas encore d'évaluation
- DGFDFDDocument8 pagesDGFDFDjs9999Pas encore d'évaluation
- DSP Implementation of Cholesky DecompositionDocument4 pagesDSP Implementation of Cholesky DecompositionBaruch CyzsPas encore d'évaluation
- Computers and Mathematics With Applications: D. Mierke, C.F. Janßen, T. RungDocument22 pagesComputers and Mathematics With Applications: D. Mierke, C.F. Janßen, T. RungAT8iPas encore d'évaluation
- LDL FactorizacionDocument7 pagesLDL FactorizacionMiguel PerezPas encore d'évaluation
- Computer Solution: Digital Electromagnetic Transients Multiphase NetworksDocument12 pagesComputer Solution: Digital Electromagnetic Transients Multiphase NetworksObed GarcíaPas encore d'évaluation
- Domme 1967Document12 pagesDomme 1967Carlos ChávezPas encore d'évaluation
- Adaptive Refinement in Vibrational Analysis and Isogemetric AnalysisDocument22 pagesAdaptive Refinement in Vibrational Analysis and Isogemetric AnalysisAbhishek KumarPas encore d'évaluation
- Sparse Implementation of Revised Simplex Algorithms On Parallel ComputersDocument8 pagesSparse Implementation of Revised Simplex Algorithms On Parallel ComputersKaram SalehPas encore d'évaluation
- Computer Solution: Digital Electromagnetic Transients Multiphase NetworksDocument12 pagesComputer Solution: Digital Electromagnetic Transients Multiphase NetworksMuhammed Cihat AltınPas encore d'évaluation
- Latex SubmissionDocument6 pagesLatex SubmissionguluPas encore d'évaluation
- Safe and Effective Determinant Evaluation: February 25, 1994Document16 pagesSafe and Effective Determinant Evaluation: February 25, 1994David ImmanuelPas encore d'évaluation
- 3D Morphing Without User Interaction: Submitted To Eurographics Symposium On Geometry Processing (2004)Document10 pages3D Morphing Without User Interaction: Submitted To Eurographics Symposium On Geometry Processing (2004)tsigelakistisPas encore d'évaluation
- Investigation of Quantum Algorithms For Direct Numerical Simulation of The Navier-Stokes EquationsDocument17 pagesInvestigation of Quantum Algorithms For Direct Numerical Simulation of The Navier-Stokes EquationsマルワPas encore d'évaluation
- Mathematical and Computational Modeling: With Applications in Natural and Social Sciences, Engineering, and the ArtsD'EverandMathematical and Computational Modeling: With Applications in Natural and Social Sciences, Engineering, and the ArtsRoderick MelnikPas encore d'évaluation
- The Adaptive Cross-Approximation Technique For The 3-D Boundary-Element Method PDFDocument4 pagesThe Adaptive Cross-Approximation Technique For The 3-D Boundary-Element Method PDFJonathan MillerPas encore d'évaluation
- Seismic 4 425: T (C TTZ), D, NRL, S, TT, W)Document5 pagesSeismic 4 425: T (C TTZ), D, NRL, S, TT, W)SyedFaridAliPas encore d'évaluation
- A New Parallel Version of The DDSCAT Code For Electromagnetic Scattering From Big TargetsDocument5 pagesA New Parallel Version of The DDSCAT Code For Electromagnetic Scattering From Big TargetsMartín FigueroaPas encore d'évaluation
- Breaking Through Memory Limitation in GPU Parallel Processing Using Strassen AlgorithmDocument5 pagesBreaking Through Memory Limitation in GPU Parallel Processing Using Strassen AlgorithmDonkeyTankPas encore d'évaluation
- 2m PDFDocument5 pages2m PDFSAKTHI SANTHOSH BPas encore d'évaluation
- Icfd10 Eg 30i1Document8 pagesIcfd10 Eg 30i1NextScribePas encore d'évaluation
- Reddy Chap3-4Document68 pagesReddy Chap3-4Juan CarlosPas encore d'évaluation
- Profile Front MinimizationDocument12 pagesProfile Front MinimizationvttrlcPas encore d'évaluation
- Convex Hull 3dDocument12 pagesConvex Hull 3dsqc150Pas encore d'évaluation
- Numerical Accuracy in The Solution of The ShallowDocument8 pagesNumerical Accuracy in The Solution of The ShallowFernando Robles AguilarPas encore d'évaluation
- Fast Sparse Matrix MultiplicationDocument11 pagesFast Sparse Matrix MultiplicationRocky BarusPas encore d'évaluation
- Recursive and Residual Algorithms For The Efficient Numerical Integration of Multi-Body SystemsDocument31 pagesRecursive and Residual Algorithms For The Efficient Numerical Integration of Multi-Body SystemsCleves AxiomaPas encore d'évaluation
- A Practical Performance Comparison of Parallel Matrix Multiplication Algorithms On Networks of WorkstationsDocument2 pagesA Practical Performance Comparison of Parallel Matrix Multiplication Algorithms On Networks of WorkstationsPhulturoo KhanPas encore d'évaluation
- Content PDFDocument14 pagesContent PDFrobbyyuPas encore d'évaluation
- Intelligent Simulation of Multibody Dynamics: Space-State and Descriptor Methods in Sequential and Parallel Computing EnvironmentsDocument19 pagesIntelligent Simulation of Multibody Dynamics: Space-State and Descriptor Methods in Sequential and Parallel Computing EnvironmentsChernet TugePas encore d'évaluation
- Discontinuous Finite Difference and Spectral Methods For Self Force ApplicationsDocument29 pagesDiscontinuous Finite Difference and Spectral Methods For Self Force ApplicationsbabistokasPas encore d'évaluation
- Gorong - GorongDocument9 pagesGorong - GorongMuh IzdiharPas encore d'évaluation
- Modern Model Order Reduction For Industrial ApplicationsDocument6 pagesModern Model Order Reduction For Industrial ApplicationsAnonymous lEBdswQXmxPas encore d'évaluation
- Accelerating Marching Cubes With Graphics HardwareDocument6 pagesAccelerating Marching Cubes With Graphics HardwareGustavo Urquizo RodríguezPas encore d'évaluation
- A Mixed Precision Semi-Lagrangian Algorithm and Its Performance On AcceleratorsDocument7 pagesA Mixed Precision Semi-Lagrangian Algorithm and Its Performance On Acceleratorsrtfss13666Pas encore d'évaluation
- A Fast Modal Technique For The Computation of The Campbell Diagram of Multi-Degree-Of-Freedom RotorsDocument18 pagesA Fast Modal Technique For The Computation of The Campbell Diagram of Multi-Degree-Of-Freedom RotorsRafael SoaresPas encore d'évaluation
- Icase: IIII11l11ll IllDocument26 pagesIcase: IIII11l11ll IllSk SharmaPas encore d'évaluation
- Franklin Note 2Document21 pagesFranklin Note 2WyliePas encore d'évaluation
- Nelson L. Passos Robert P. Light Virgil Andronache Edwin H.-M. Sha Midwestern State UniversityDocument6 pagesNelson L. Passos Robert P. Light Virgil Andronache Edwin H.-M. Sha Midwestern State UniversityAkhil KsPas encore d'évaluation
- A Wavelet-Based Anytime Algorithm For K-Means Clustering of Time SeriesDocument12 pagesA Wavelet-Based Anytime Algorithm For K-Means Clustering of Time SeriesYaseen HussainPas encore d'évaluation
- A 2589 Line Topology Optimization Code Written For The Graphics CardDocument20 pagesA 2589 Line Topology Optimization Code Written For The Graphics Cardgorot1Pas encore d'évaluation
- Solution To Industry Benchmark Problems With The Lattice-Boltzmann Code XFlowDocument22 pagesSolution To Industry Benchmark Problems With The Lattice-Boltzmann Code XFlowCFDiran.irPas encore d'évaluation
- 6 59 1 PBDocument8 pages6 59 1 PBSaifizi SaidonPas encore d'évaluation
- Orlando Newmark Bogday 05Document15 pagesOrlando Newmark Bogday 05Alex AraújoPas encore d'évaluation
- Final Project Report Transient Stability of Power System (Programming Massively Parallel Graphics Multiprocessors Using CUDA)Document5 pagesFinal Project Report Transient Stability of Power System (Programming Massively Parallel Graphics Multiprocessors Using CUDA)shotorbariPas encore d'évaluation
- Mcgill University School of Computer Science Acaps LaboratoryDocument34 pagesMcgill University School of Computer Science Acaps Laboratorywoxawi6937Pas encore d'évaluation
- Large Scale Optimization Strategies For Zone Configuration of Simulated Moving BedsDocument18 pagesLarge Scale Optimization Strategies For Zone Configuration of Simulated Moving BedsDoctorObermanPas encore d'évaluation
- Efficient Simplificaiton of Point Sampled SurfacesDocument8 pagesEfficient Simplificaiton of Point Sampled SurfacesVivian LiPas encore d'évaluation
- Finite-Element Method For Elastic Wave PropagationDocument10 pagesFinite-Element Method For Elastic Wave Propagationbahar1234Pas encore d'évaluation
- Journal of Statistical Software: Warping Functional Data in R and C Via A Bayesian Multiresolution ApproachDocument22 pagesJournal of Statistical Software: Warping Functional Data in R and C Via A Bayesian Multiresolution Approacha a aPas encore d'évaluation
- ECSE 420 - Parallel Cholesky Algorithm - ReportDocument17 pagesECSE 420 - Parallel Cholesky Algorithm - ReportpiohmPas encore d'évaluation
- Evolutionary Algorithms for Mobile Ad Hoc NetworksD'EverandEvolutionary Algorithms for Mobile Ad Hoc NetworksPas encore d'évaluation
- Notice: Hostel in From WillDocument1 pageNotice: Hostel in From WilldaskhagoPas encore d'évaluation
- Nodal Position and Element Connectivity of 200 Element Dielectric Placed Between Two Electrodes Whose Potential Difference Is 1VDocument1 pageNodal Position and Element Connectivity of 200 Element Dielectric Placed Between Two Electrodes Whose Potential Difference Is 1VdaskhagoPas encore d'évaluation
- Pranveer Singh Group of Institutions, Nh-2, Bhauti, Kanpur Bus Route No.1 ONLY Dated .11.11.2018Document2 pagesPranveer Singh Group of Institutions, Nh-2, Bhauti, Kanpur Bus Route No.1 ONLY Dated .11.11.2018daskhagoPas encore d'évaluation
- Cug August PaymentDocument1 pageCug August PaymentdaskhagoPas encore d'évaluation
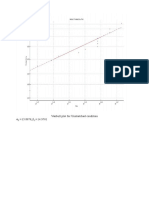
- Weibull Plot For Unstretched ConditionDocument3 pagesWeibull Plot For Unstretched ConditiondaskhagoPas encore d'évaluation
- Moonish Crazing PDFDocument1 pageMoonish Crazing PDFdaskhagoPas encore d'évaluation
- DcascascDocument16 pagesDcascascdaskhagoPas encore d'évaluation
- DVSVVDocument4 pagesDVSVVdaskhagoPas encore d'évaluation
- New Work 6Document4 pagesNew Work 6daskhagoPas encore d'évaluation
- SgfbsfbsDocument6 pagesSgfbsfbsdaskhagoPas encore d'évaluation
- SDVSZZSFBDocument10 pagesSDVSZZSFBdaskhagoPas encore d'évaluation
- ErverjvberkDocument379 pagesErverjvberkdaskhagoPas encore d'évaluation
- ErverjvberkDocument379 pagesErverjvberkdaskhagoPas encore d'évaluation
- ErverjvberkDocument379 pagesErverjvberkdaskhagoPas encore d'évaluation
- ErverjvberkDocument379 pagesErverjvberkdaskhagoPas encore d'évaluation
- ErverjvberkDocument379 pagesErverjvberkdaskhagoPas encore d'évaluation
- ErverjvberkDocument379 pagesErverjvberkdaskhagoPas encore d'évaluation
- ErverjvberkDocument379 pagesErverjvberkdaskhagoPas encore d'évaluation
- ErverjvberkDocument379 pagesErverjvberkdaskhagoPas encore d'évaluation
- Application Form Regular Faculty150816111245 PDFDocument7 pagesApplication Form Regular Faculty150816111245 PDFdaskhagoPas encore d'évaluation
- New Work 4Document3 pagesNew Work 4daskhagoPas encore d'évaluation
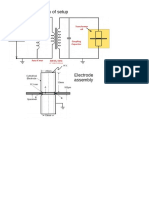
- Schematic Diagram Electrode Assembly PDFDocument1 pageSchematic Diagram Electrode Assembly PDFdaskhagoPas encore d'évaluation
- Mess DuesDocument1 pageMess DuesdaskhagoPas encore d'évaluation
- September Mess Bill-2016Document365 pagesSeptember Mess Bill-2016daskhagoPas encore d'évaluation
- Marc Mess PaymentDocument1 pageMarc Mess PaymentdaskhagoPas encore d'évaluation
- Freely-Jointed Chain: For Up To Date Version of This Document, See Z. SuoDocument6 pagesFreely-Jointed Chain: For Up To Date Version of This Document, See Z. SuokhayatPas encore d'évaluation
- Full Length Paper INCAM2015 1Document3 pagesFull Length Paper INCAM2015 1daskhagoPas encore d'évaluation
- Paymnet and Receipt Onward June-16..Document31 pagesPaymnet and Receipt Onward June-16..daskhagoPas encore d'évaluation
- Mess Menu 1 December 2016Document2 pagesMess Menu 1 December 2016daskhagoPas encore d'évaluation
- Me 201 Engineering Mechanics Statics3121Document19 pagesMe 201 Engineering Mechanics Statics3121tugskulPas encore d'évaluation
- VCE Maths Methods Units 1 & 2Document3 pagesVCE Maths Methods Units 1 & 2Asmaa MannasahebPas encore d'évaluation
- Mathematics 9 2ndDocument6 pagesMathematics 9 2ndAngelo Morcilla TiquioPas encore d'évaluation
- ME458 FEM - L2 - Intro To Stiffness MethodDocument90 pagesME458 FEM - L2 - Intro To Stiffness MethodHamza KhizarPas encore d'évaluation
- Emsyll 2Document4 pagesEmsyll 2Pareekshith KattiPas encore d'évaluation
- Q1 - Math 10 ReviewersDocument2 pagesQ1 - Math 10 ReviewersJerry Bhoy ReniedoPas encore d'évaluation
- Weak & Strong FormDocument23 pagesWeak & Strong FormZainuri NorliyatiPas encore d'évaluation
- Example 1: A Natural Number Is Also A Whole Number.: Classification of Real Numbers ExamplesDocument5 pagesExample 1: A Natural Number Is Also A Whole Number.: Classification of Real Numbers Examplescykool_2kPas encore d'évaluation
- Clifford AlgebraDocument22 pagesClifford AlgebraChandra Prakash100% (1)
- Maths Quiz Questions Without Ans (Class 7)Document3 pagesMaths Quiz Questions Without Ans (Class 7)Student Service CellPas encore d'évaluation
- CylinderDocument5 pagesCylinderMohammadFaizanPas encore d'évaluation
- Terminating and Non-Terminating DecimalsDocument2 pagesTerminating and Non-Terminating Decimalshasan bishPas encore d'évaluation
- Taylor Series PDFDocument16 pagesTaylor Series PDFIhsan ALrashidPas encore d'évaluation
- Adding and Subtracting PolynomialsDocument8 pagesAdding and Subtracting PolynomialsHyung BaePas encore d'évaluation
- EEP 311L Laboratory Activity 4Document1 pageEEP 311L Laboratory Activity 4Lemonade TVPas encore d'évaluation
- Sem 2 Maths Chap 2Document19 pagesSem 2 Maths Chap 2Mohammed Abdul Räfåè100% (2)
- Functions and Their RepresentationsDocument7 pagesFunctions and Their RepresentationsLuis Ignacio Lomeli GalazPas encore d'évaluation
- Vectors Tensors Complete PDFDocument198 pagesVectors Tensors Complete PDFsujayan2005Pas encore d'évaluation
- Olympiad Stuff You Should Know For International Olympiad :DDocument10 pagesOlympiad Stuff You Should Know For International Olympiad :DInkePas encore d'évaluation
- Abacus Math Worksheets FreeDocument10 pagesAbacus Math Worksheets FreeBrenda YeePas encore d'évaluation
- Semi Direct ProductDocument5 pagesSemi Direct ProductalbanianretardPas encore d'évaluation
- Ch1 - Laplace Transform L.T. - 26 Pgs PDFDocument26 pagesCh1 - Laplace Transform L.T. - 26 Pgs PDFMohamad Duhoki100% (1)
- Mac1114 m5 ws2Document3 pagesMac1114 m5 ws2api-276143540Pas encore d'évaluation
- Chap 1Document17 pagesChap 1Batma ThurgaPas encore d'évaluation
- Matlab 1Document6 pagesMatlab 1Wafaa AimanPas encore d'évaluation
- Matlab SolverDocument3 pagesMatlab SolverSudhanwa KulkarniPas encore d'évaluation
- Name: - Date: - Grade Level and Section: - ScoreDocument2 pagesName: - Date: - Grade Level and Section: - ScoreJustine Antiojo CruzPas encore d'évaluation
- Sample Quiz LMDocument5 pagesSample Quiz LMA LPas encore d'évaluation
- Generalized Inverses and Solutions of Linear Systems: John Z. HearonDocument6 pagesGeneralized Inverses and Solutions of Linear Systems: John Z. HearonvahidPas encore d'évaluation
- 121 EEE110 LabSheet01Document11 pages121 EEE110 LabSheet01bkmmizanPas encore d'évaluation