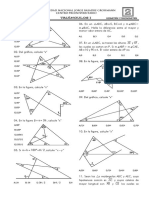
Vous aimerez peut-être aussi
- Diagrama de Cajas y Bigotes2.0Document10 pagesDiagrama de Cajas y Bigotes2.0Juan Carlos MárquezPas encore d'évaluation
- Guia 8Document4 pagesGuia 8saritamgPas encore d'évaluation
- EXAMEN DE Operaciones Con ENTEROSDocument2 pagesEXAMEN DE Operaciones Con ENTEROSLuz Amparo VaronPas encore d'évaluation
- Estadística 08 CNDocument4 pagesEstadística 08 CNAdrián ChancoPas encore d'évaluation
- Tablas de Frecuencia y de Contingencia 3roDocument2 pagesTablas de Frecuencia y de Contingencia 3roFredy LaricoPas encore d'évaluation
- Matematicas 9°Document181 pagesMatematicas 9°ARROYAVE OORPas encore d'évaluation
- 9 Taller 1 Números RealesDocument2 pages9 Taller 1 Números RealesHalver100% (1)
- Evaluacion de MatematicaDocument7 pagesEvaluacion de MatematicaMateo FajardoPas encore d'évaluation
- AritméticaDocument155 pagesAritméticaAroon Alex Santos ZuñigaPas encore d'évaluation
- Notación CientíficaDocument1 pageNotación CientíficaNuriaSantiagoPas encore d'évaluation
- RM Regla de Tres Simple y CompuestaDocument2 pagesRM Regla de Tres Simple y CompuestaerickesmePas encore d'évaluation
- Taller Razonamiento Matematico DecimoDocument2 pagesTaller Razonamiento Matematico DecimoMoni Bivi Betty Tizzo0% (1)
- Nuemros Enteros ADocument4 pagesNuemros Enteros AIsabel Moreno ZamoranoPas encore d'évaluation
- Ecuacones e InecuacionesDocument13 pagesEcuacones e InecuacionesaslyPas encore d'évaluation
- Repaso GeometriaDocument4 pagesRepaso GeometriasaulPas encore d'évaluation
- RM Operaciones Con Conjunto 1° BoscoDocument1 pageRM Operaciones Con Conjunto 1° BoscoBella AldamaPas encore d'évaluation
- Aritmética 1° Secundaria 2023 - Iii BimestreDocument21 pagesAritmética 1° Secundaria 2023 - Iii BimestreLUHANA GUADALUPE OLIDEN MILANPas encore d'évaluation
- Semana 2 Operadores IIDocument7 pagesSemana 2 Operadores IIwalter minchola mendozaPas encore d'évaluation
- P04 - Teoria de EcuacionesDocument2 pagesP04 - Teoria de EcuacionesKarla ChambillaPas encore d'évaluation
- Tablas de Ditribución de Frecuencias y GráficosDocument13 pagesTablas de Ditribución de Frecuencias y GráficosLeticia Bujahico RodriguezPas encore d'évaluation
- Conjuntos PrebasicasDocument4 pagesConjuntos PrebasicasRonald QuispePas encore d'évaluation
- Binomio de Newton-3Document4 pagesBinomio de Newton-3RobertoManuelLeccaRojasPas encore d'évaluation
- Ejercicios Propuestos de ConjuntosDocument5 pagesEjercicios Propuestos de ConjuntosAda Maria Perez Martinez0% (1)
- P02-Triangulos I 2017 FinalDocument3 pagesP02-Triangulos I 2017 FinalGilberto Platero AratiaPas encore d'évaluation
- Teoria de Conjuntos PracticaDocument7 pagesTeoria de Conjuntos PracticajhonabelPas encore d'évaluation
- Ficha 4 FraccionesDocument3 pagesFicha 4 FraccionesMANUEL LEAL FERNÁNDEZPas encore d'évaluation
- Sesion Numeros IrracionalesDocument7 pagesSesion Numeros IrracionalesAnonymous bSuk8BPas encore d'évaluation
- Matematic2 Sem12 Experiencia4 Actividad4 Razones y Proporciones RP24 Ccesa007Document1 pageMatematic2 Sem12 Experiencia4 Actividad4 Razones y Proporciones RP24 Ccesa007Demetrio Ccesa RaymePas encore d'évaluation
- Notacion CientificaDocument2 pagesNotacion CientificaMichael Slater Ocaña PuiconPas encore d'évaluation
- Solucionario PDFDocument86 pagesSolucionario PDFmiltonPas encore d'évaluation
- 248 Estadistica Catedra GonzalezDocument9 pages248 Estadistica Catedra GonzalezLaura ZorrillaPas encore d'évaluation
- Diapositivas Ecuaciones CuadraticasDocument11 pagesDiapositivas Ecuaciones CuadraticasTabian Toala FigueroaPas encore d'évaluation
- Ejercicios Parte IIDocument9 pagesEjercicios Parte IIAndre GarcesPas encore d'évaluation
- Operaciones BinariasDocument4 pagesOperaciones Binariascesar_al31_312184795Pas encore d'évaluation
- Ficha Lineas Notables Segundo AñoDocument8 pagesFicha Lineas Notables Segundo AñoBryan el proPas encore d'évaluation
- 3 - Taller Estadistica - Poblacion Muestra y VariablesDocument5 pages3 - Taller Estadistica - Poblacion Muestra y VariablesGABRIEL TORRES MORATOPas encore d'évaluation
- Trabajo Potencia Energía - Fisica Final - 2021Document13 pagesTrabajo Potencia Energía - Fisica Final - 2021Jose joel suncionPas encore d'évaluation
- Fraccion GeneratrizDocument1 pageFraccion GeneratrizEDILBERTO ATENCIO GRIJALVAPas encore d'évaluation
- WebQuest: Medidas de Tendencia Central, Un Enfoque Basado en CompetenciasDocument7 pagesWebQuest: Medidas de Tendencia Central, Un Enfoque Basado en CompetenciasM. en C. Arturo Vázquez CórdovaPas encore d'évaluation
- Sem4 - DinámicaDocument8 pagesSem4 - DinámicaCarlos Montañez MontenegroPas encore d'évaluation
- Ficha Números DecimalesDocument1 pageFicha Números DecimalesJhony WesPas encore d'évaluation
- Estadística VDocument24 pagesEstadística VNelly Baez RosalesPas encore d'évaluation
- Alren Bach G M1 U3Document7 pagesAlren Bach G M1 U3José100% (1)
- Estadistica IIDocument3 pagesEstadistica IIcesar benitoPas encore d'évaluation
- Cuartiles Equipos de Alto RendimientoDocument1 pageCuartiles Equipos de Alto RendimientoARTURO AVILAPas encore d'évaluation
- RM-5to UNI-OPERADORES MATEMÁTICOS-PPT SIN AUDIO - PPTXDocument11 pagesRM-5to UNI-OPERADORES MATEMÁTICOS-PPT SIN AUDIO - PPTXALEJANDRO ANDRE MONTENEGRO ROJASPas encore d'évaluation
- PROBLEMASSSSDocument8 pagesPROBLEMASSSSRitaly Rengifo OrtegaPas encore d'évaluation
- 10666-Texto Del Artículo-23131-1-10-20181203Document8 pages10666-Texto Del Artículo-23131-1-10-20181203Jose Luis Mendieta VilaPas encore d'évaluation
- Aritmetica PDFDocument8 pagesAritmetica PDFAlex H. SnccPas encore d'évaluation
- Sopa de Letras EstadisticaDocument3 pagesSopa de Letras EstadisticaSamuel HerreraPas encore d'évaluation
- Historia y Evolución Del ComputadorDocument7 pagesHistoria y Evolución Del ComputadoranyecriPas encore d'évaluation
- Ejercicios de Promedios para Primero de SecundariaDocument4 pagesEjercicios de Promedios para Primero de SecundariaAraceli Guerrero Apolinario100% (2)
- Guía1 Estadística 11°. Pablo Vi 3PDocument9 pagesGuía1 Estadística 11°. Pablo Vi 3PAngélica ChávezPas encore d'évaluation
- Relaciones MetricasDocument1 pageRelaciones Metricasbeqg_06Pas encore d'évaluation
- Est N1PDDocument2 pagesEst N1PDChristian López Aguilar100% (1)
- Aritm-Pre U-Ver23-Maraton-Ases-01Document2 pagesAritm-Pre U-Ver23-Maraton-Ases-01Zaira LalupuPas encore d'évaluation
- Presentación de DatosDocument2 pagesPresentación de DatosvirtualicPas encore d'évaluation
- Cuatro OperacionesDocument6 pagesCuatro OperacionesFélix Quispe YucraPas encore d'évaluation
- Ejercicios de RegrsiónDocument4 pagesEjercicios de RegrsiónJeferson PoncePas encore d'évaluation
- El Sesgo y La CurtosisDocument14 pagesEl Sesgo y La CurtosisTomas Negrete100% (1)
- Resumen de Expociciones de Fórmulas y GraficasDocument7 pagesResumen de Expociciones de Fórmulas y GraficasJuancho CervantesPas encore d'évaluation
- ProposicionesDocument279 pagesProposicionesCarlos MendozaPas encore d'évaluation
- Barras BrabasDocument3 pagesBarras BrabasJuancho CervantesPas encore d'évaluation
- Recepcion Del Sonido y de La ImagenDocument16 pagesRecepcion Del Sonido y de La ImagenJuancho CervantesPas encore d'évaluation
- El Carnero Capitulo 1Document4 pagesEl Carnero Capitulo 1maffe31567% (3)
- Carnero Cap 21Document22 pagesCarnero Cap 21Juancho CervantesPas encore d'évaluation
- VelasdeamistadDocument10 pagesVelasdeamistadapi-31918144Pas encore d'évaluation
- 1 Medidas de Posición y DispersiónDocument52 pages1 Medidas de Posición y Dispersiónhamletmata4869% (13)
- Estadistica InformeDocument11 pagesEstadistica InformegersonPas encore d'évaluation
- Datos AgrupadosDocument28 pagesDatos AgrupadosCesar Augusto Santos Ruano100% (2)
- Parcial1 GonzálezhsDocument12 pagesParcial1 GonzálezhsHarold GonzálezPas encore d'évaluation
- Medidas de PosiciónDocument9 pagesMedidas de PosiciónFRANCISCO JOSE CARRASCO CARRILLOPas encore d'évaluation
- Taller No1 - Estadistica DescriptivaDocument2 pagesTaller No1 - Estadistica DescriptivajuanpoopyPas encore d'évaluation
- Examen Unidad II Estadistica I Unicah PautaDocument3 pagesExamen Unidad II Estadistica I Unicah PautaCristian PadillaPas encore d'évaluation
- Medidas de Tendencia Central y DispersiónDocument32 pagesMedidas de Tendencia Central y DispersiónMaria Reneé FloresPas encore d'évaluation
- Proyecto Estadistica Grupo 4Document29 pagesProyecto Estadistica Grupo 4Agustin Perez yagualPas encore d'évaluation
- Taller Medidas de Tendencia Central y de PosiciónDocument4 pagesTaller Medidas de Tendencia Central y de PosiciónJulieth OrtegaPas encore d'évaluation
- Solucionario 4ESO Academicas U07 ESTADÍSTICADocument30 pagesSolucionario 4ESO Academicas U07 ESTADÍSTICACristina Pastor ServerPas encore d'évaluation
- Estadistica 01Document30 pagesEstadistica 01Alba MegiasPas encore d'évaluation
- Unidad 1 Estadistica DescriptivaDocument44 pagesUnidad 1 Estadistica DescriptivaMichelle100% (4)
- Paso 3 Análisis de La InformaciónDocument19 pagesPaso 3 Análisis de La InformaciónBetsy Josefina Rodriguez RiveraPas encore d'évaluation
- Medidas de Tendencia Central y de PosicionDocument22 pagesMedidas de Tendencia Central y de PosicionLucy BautistaPas encore d'évaluation
- Mineral Resource EstimationDocument19 pagesMineral Resource EstimationLouAntonPas encore d'évaluation
- ConsolidadoDocument35 pagesConsolidadoEdgar Pinzon50% (2)
- Estadistica - Aplicada A Los Proyectos de InversionDocument54 pagesEstadistica - Aplicada A Los Proyectos de InversionLuis Daniel Davalos PerezPas encore d'évaluation
- 04 Criterios de Homogeneidad, Cuartiles, Deciles y PercentilesDocument11 pages04 Criterios de Homogeneidad, Cuartiles, Deciles y PercentilesFelipe Escobar RubioPas encore d'évaluation
- Protocolo Individual (1) ESTADISTICADocument5 pagesProtocolo Individual (1) ESTADISTICALufeme50% (2)
- Pauta Ayudantía 1 Repaso Probabilidades y EstadísticaDocument6 pagesPauta Ayudantía 1 Repaso Probabilidades y EstadísticaciburgosPas encore d'évaluation
- Actividad 7 EpidemiologíaDocument16 pagesActividad 7 EpidemiologíaIsabel Montaño100% (1)
- Trabajo Grupo IntroduccionDocument38 pagesTrabajo Grupo IntroduccionCelina Ayde GironPas encore d'évaluation
- MOPECE3Document96 pagesMOPECE3Alberto Rebaza71% (7)
- Medidas de PosiciónDocument3 pagesMedidas de PosiciónKarelys CachagoPas encore d'évaluation
- Laboratorio 1Document5 pagesLaboratorio 1latincrow81Pas encore d'évaluation
- Hoja de Repaso No 1 2022 SoluciónDocument6 pagesHoja de Repaso No 1 2022 SoluciónYoselin Estephany Corado Sosa APas encore d'évaluation
- Estadistica Tarea 4to BachDocument16 pagesEstadistica Tarea 4to BachHaru ZbdPas encore d'évaluation
- Parcial 1 Semana 4Document16 pagesParcial 1 Semana 4David Galeano75% (8)
- Formulario de Estadística y ProbabilidadDocument7 pagesFormulario de Estadística y ProbabilidadYael LunaPas encore d'évaluation