Vous aimerez peut-être aussi
- Elmalili Hamdi Yazir Hak Dini Kuran Dili TefsiriDocument12 pagesElmalili Hamdi Yazir Hak Dini Kuran Dili TefsiriYilmaz AltunPas encore d'évaluation
- Traditional Vs Agile Project ManagementDocument6 pagesTraditional Vs Agile Project ManagementSaurav Panda100% (1)
- Google Chrome Default CookiesDocument104 pagesGoogle Chrome Default CookiesAndrew ShevchenkoPas encore d'évaluation
- Zebra GC420tDocument2 pagesZebra GC420treginaldo2005100% (1)
- PgfganttDocument70 pagesPgfganttdleonarenPas encore d'évaluation
- HW4: Merge Sort: 1 Assignment GoalDocument6 pagesHW4: Merge Sort: 1 Assignment GoalRafael MendoncaPas encore d'évaluation
- Drawing Gantt Charts in L TEX with Tik ZDocument59 pagesDrawing Gantt Charts in L TEX with Tik ZCodera PurpaPas encore d'évaluation
- Emphasis On Topics Relevant To Financial Analysis © by Houston H. Stokes 20Document29 pagesEmphasis On Topics Relevant To Financial Analysis © by Houston H. Stokes 20TootieJeanPas encore d'évaluation
- WurtzEtAlGarch PDFDocument41 pagesWurtzEtAlGarch PDFmarcoPas encore d'évaluation
- An Introduction To The Package GeoRDocument17 pagesAn Introduction To The Package GeoRlocometrallaPas encore d'évaluation
- Maxima by Example8nintDocument20 pagesMaxima by Example8nintjgbarrPas encore d'évaluation
- Automatic Control Systems TheoryDocument9 pagesAutomatic Control Systems TheoryJames KabugoPas encore d'évaluation
- IRISDocument67 pagesIRISArinze7Pas encore d'évaluation
- COMT AssignmentDocument13 pagesCOMT AssignmentKekWPas encore d'évaluation
- Mapreduce Programming Model and Design Patterns: Andrea Lottarini January 17, 2012Document23 pagesMapreduce Programming Model and Design Patterns: Andrea Lottarini January 17, 2012Andrea LottariniPas encore d'évaluation
- Hardware Implementation of Finite Fields of Characteristic ThreeDocument11 pagesHardware Implementation of Finite Fields of Characteristic ThreehachiiiimPas encore d'évaluation
- Use, Tsset, Line Generate, Line, Arch, Mgarch, Tsset, Estat IcDocument10 pagesUse, Tsset, Line Generate, Line, Arch, Mgarch, Tsset, Estat Ic薛璐Pas encore d'évaluation
- Matlab/Octave Channel3DLab Package ManualDocument16 pagesMatlab/Octave Channel3DLab Package ManualAshish Kotwal100% (1)
- General Graph Optimization Framework for Robotics and Computer Vision ProblemsDocument7 pagesGeneral Graph Optimization Framework for Robotics and Computer Vision ProblemsSidharth SharmaPas encore d'évaluation
- Modelos de Despacho-1Document27 pagesModelos de Despacho-1edgarPas encore d'évaluation
- ESTAR Online AppendixDocument18 pagesESTAR Online AppendixHendraPas encore d'évaluation
- Matlab GUI for ISOLA Fortran seismic inversion codesDocument34 pagesMatlab GUI for ISOLA Fortran seismic inversion codesGunadi Suryo JatmikoPas encore d'évaluation
- BertTutorial TomographyDocument28 pagesBertTutorial Tomographymartinez_vladim3914Pas encore d'évaluation
- Inverse Gamma Model for Size of Loss DataDocument161 pagesInverse Gamma Model for Size of Loss DataAhmed FenneurPas encore d'évaluation
- Kruskal PascalDocument13 pagesKruskal PascalIonut MarinPas encore d'évaluation
- Modern Applied Statistics With SDocument48 pagesModern Applied Statistics With SGaluh Ayu Wulandari SriyantoPas encore d'évaluation
- BRT ToutorialDocument28 pagesBRT ToutorialAsem A. HassanPas encore d'évaluation
- Introduction To Ggplot2: Saier (Vivien) Ye September 16, 2013Document32 pagesIntroduction To Ggplot2: Saier (Vivien) Ye September 16, 201310yangb92Pas encore d'évaluation
- Time Varying Risk GARCH Models-Part1Document31 pagesTime Varying Risk GARCH Models-Part1knightbtwPas encore d'évaluation
- Vallemedina Mariaelena 2019 Ed269-100-221Document122 pagesVallemedina Mariaelena 2019 Ed269-100-221IBTISSAM ENNAMIRIPas encore d'évaluation
- Analyzing GRT Data in StataDocument17 pagesAnalyzing GRT Data in StataAnonymous EAineTizPas encore d'évaluation
- GARCH Model Selena, AnaDocument15 pagesGARCH Model Selena, AnaSelenaBelikovPas encore d'évaluation
- Lab01 Note RDocument7 pagesLab01 Note RsdcphdworkPas encore d'évaluation
- 1982 - Algorithm 583 LSQR Sparse LinearDocument15 pages1982 - Algorithm 583 LSQR Sparse LinearluongxuandanPas encore d'évaluation
- Beta and Gamma FunctionsDocument32 pagesBeta and Gamma FunctionsSa'ad Abd Ar RafiePas encore d'évaluation
- Chapter Parallel Prefix SumDocument21 pagesChapter Parallel Prefix SumAimee ReynoldsPas encore d'évaluation
- QuickGuide 2018Document7 pagesQuickGuide 2018daliPas encore d'évaluation
- A-Bootstrap Prediction in Univariate Volatility Models With Leverage EffectDocument21 pagesA-Bootstrap Prediction in Univariate Volatility Models With Leverage EffectRodrigo CaldasPas encore d'évaluation
- C3-2016 GJPAM Vol. 12 No 2 Pp. 1201-1210Document10 pagesC3-2016 GJPAM Vol. 12 No 2 Pp. 1201-1210julia wulandariPas encore d'évaluation
- GMSH GuidelineDocument19 pagesGMSH GuidelineQuazi Shammas100% (1)
- Multi-Model Control of Nonlinear Systems Using Closed-Loop Gap MetricDocument5 pagesMulti-Model Control of Nonlinear Systems Using Closed-Loop Gap MetricAhmed TaharPas encore d'évaluation
- Sample1Document5 pagesSample1Anonymous EqlLa9VPas encore d'évaluation
- Atom-4 2 0Document17 pagesAtom-4 2 0Elias BritoPas encore d'évaluation
- Fuzzy clustering R package fclust provides toolsDocument19 pagesFuzzy clustering R package fclust provides toolsLuciano BorgoglioPas encore d'évaluation
- Arch Model and Time-Varying VolatilityDocument17 pagesArch Model and Time-Varying VolatilityJorge Vega RodríguezPas encore d'évaluation
- CYK Algorithm - A Haskell ImplementationDocument3 pagesCYK Algorithm - A Haskell ImplementationPaul WintereisePas encore d'évaluation
- SvarDocument27 pagesSvarMirza KudumovićPas encore d'évaluation
- Software Implementation and Testing of GARCH ModelsDocument33 pagesSoftware Implementation and Testing of GARCH ModelsmeetmauroPas encore d'évaluation
- An Embedded Controller For The PendubotDocument6 pagesAn Embedded Controller For The PendubotCarlos Alberto Cribillero VegaPas encore d'évaluation
- A First Course in Computational Algebraic GeometryDocument133 pagesA First Course in Computational Algebraic Geometryjoe schmoe100% (1)
- CH Var Basic PDFDocument48 pagesCH Var Basic PDFTPNPas encore d'évaluation
- Garch23 TutorialDocument71 pagesGarch23 TutorialHoracio Moyano BorquezPas encore d'évaluation
- Aand B, Which Gets Called Via The GUI, Reads As FollowsDocument5 pagesAand B, Which Gets Called Via The GUI, Reads As FollowslatinwolfPas encore d'évaluation
- On The Root System of E: January 2014Document35 pagesOn The Root System of E: January 2014Enrique EscalantePas encore d'évaluation
- AerDocument6 pagesAerchuck89Pas encore d'évaluation
- Introduction To The TIDYVERSEDocument4 pagesIntroduction To The TIDYVERSEFor ThingsPas encore d'évaluation
- Jim Holmström - Growing Neural Gas: Experiments With GNG, GNG With Utility and Supervised GNGDocument42 pagesJim Holmström - Growing Neural Gas: Experiments With GNG, GNG With Utility and Supervised GNGTuhmaPas encore d'évaluation
- Maple DuhamelDocument6 pagesMaple DuhamelMatteo SoruPas encore d'évaluation
- Diagram Macros for Tangles and Braided Hopf AlgebrasDocument7 pagesDiagram Macros for Tangles and Braided Hopf AlgebrasAbichou IssaPas encore d'évaluation
- Engineers and ScientitsDocument26 pagesEngineers and ScientitsKarthi RamachandranPas encore d'évaluation
- DFA Book 03 Pressure Transient AnalysisDocument32 pagesDFA Book 03 Pressure Transient AnalysisLuis LazardePas encore d'évaluation
- Gabor FilterDocument9 pagesGabor Filterjohn_puppy31100% (1)
- GARCH Models: Structure, Statistical Inference and Financial ApplicationsD'EverandGARCH Models: Structure, Statistical Inference and Financial ApplicationsÉvaluation : 5 sur 5 étoiles5/5 (1)
- SvarDocument27 pagesSvarMirza KudumovićPas encore d'évaluation
- SvarDocument27 pagesSvarMirza KudumovićPas encore d'évaluation
- Capturing The StarsDocument1 pageCapturing The StarssmudxxPas encore d'évaluation
- 2 Glossary of TermsDocument13 pages2 Glossary of TermssmudxxPas encore d'évaluation
- Research Scholarships 798Document3 pagesResearch Scholarships 798smudxxPas encore d'évaluation
- Yerp Mid-Term 2012Document58 pagesYerp Mid-Term 2012smudxxPas encore d'évaluation
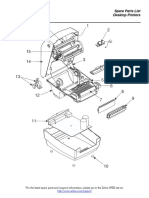
- Magnum Manual Mmg155 PartsDocument70 pagesMagnum Manual Mmg155 PartsFrancisco SandovalPas encore d'évaluation
- License Company Brochure Mockup 2560900Document2 pagesLicense Company Brochure Mockup 2560900Anonymous rPV6LRE1Pas encore d'évaluation
- Need of Cloud in DevOpsDocument17 pagesNeed of Cloud in DevOpsSuneetha BullaPas encore d'évaluation
- Dhanasimmaraja Subramani - Page 1Document3 pagesDhanasimmaraja Subramani - Page 1mukthesh9Pas encore d'évaluation
- Explore Usage of Basic Linux Commands and System Calls For File, Directory and Process ManagementDocument10 pagesExplore Usage of Basic Linux Commands and System Calls For File, Directory and Process ManagementAmruta PoojaryPas encore d'évaluation
- Script MafiaDocument2 pagesScript MafiaHassan FethiPas encore d'évaluation
- Backup Script DocumentationDocument22 pagesBackup Script DocumentationJuan CarlosPas encore d'évaluation
- 2023 BlackRock Summer Analyst Program AcceleratorDocument1 page2023 BlackRock Summer Analyst Program AcceleratorOlaoluwa OgunleyePas encore d'évaluation
- How To Design The Perfect PCBDocument33 pagesHow To Design The Perfect PCBDiego Ricardo Paez ArdilaPas encore d'évaluation
- Note: Extra Spare Switches Need To Be Available As Backup Incase of FailuresDocument21 pagesNote: Extra Spare Switches Need To Be Available As Backup Incase of Failuresrajugs_lgPas encore d'évaluation
- Social Media Marketing Overview: Benefits and StrategyDocument3 pagesSocial Media Marketing Overview: Benefits and StrategyFarah TahirPas encore d'évaluation
- Export CKD Files Read MeDocument4 pagesExport CKD Files Read Mevladko_mi_lin4222Pas encore d'évaluation
- TLE 7 1st Quarter Exam SY 2022-2023Document3 pagesTLE 7 1st Quarter Exam SY 2022-2023dodongmakattigbasPas encore d'évaluation
- Critical Path Method (CPM) in Project ManagementDocument27 pagesCritical Path Method (CPM) in Project ManagementendhaPas encore d'évaluation
- Cluster Could Not StartDocument4 pagesCluster Could Not StartMartaSekulicPas encore d'évaluation
- Introduction To Image Processing Using MatlabDocument85 pagesIntroduction To Image Processing Using MatlabAkankhya BeheraPas encore d'évaluation
- Java PracticalDocument37 pagesJava PracticalSimran ShresthaPas encore d'évaluation
- Basic SSL Certificates: Features & BenefitsDocument4 pagesBasic SSL Certificates: Features & BenefitsAnugrah Damai Pratama SolusiPas encore d'évaluation
- Check Lagarconne - Coms SEODocument13 pagesCheck Lagarconne - Coms SEOUmar HanifPas encore d'évaluation
- Michael W Hughes 2020 RESUME CVDocument4 pagesMichael W Hughes 2020 RESUME CVrecruiterkkPas encore d'évaluation
- DevOps с Laravel 3. KubernetesDocument92 pagesDevOps с Laravel 3. Kubernetesagris.markusPas encore d'évaluation
- SECTION 4 - RF System DesignDocument44 pagesSECTION 4 - RF System DesignBelachew AndualemPas encore d'évaluation
- Olimex Eeg Users Manual Revision CDocument25 pagesOlimex Eeg Users Manual Revision CalderenPas encore d'évaluation
- Introduction To Java HomeworkDocument2 pagesIntroduction To Java Homeworkstefan16394Pas encore d'évaluation
- Resume: Niraj Kr. TripathyDocument2 pagesResume: Niraj Kr. Tripathyniraj1947Pas encore d'évaluation
- Minishell: As Beautiful As A ShellDocument7 pagesMinishell: As Beautiful As A ShellAll CapsPas encore d'évaluation