Vous aimerez peut-être aussi
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- Natural TracersDocument17 pagesNatural TracersAbhishek MajiPas encore d'évaluation
- Drinking Water Standards BIS 10500 2004 by BISDocument15 pagesDrinking Water Standards BIS 10500 2004 by BISkuntamPas encore d'évaluation
- General Studies UPSC Exam PaperDocument48 pagesGeneral Studies UPSC Exam PaperSonakshi BehlPas encore d'évaluation
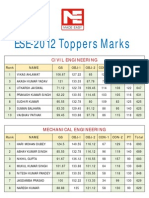
- Ese-12 Toppers Marks PDFDocument2 pagesEse-12 Toppers Marks PDFBanu SravanthPas encore d'évaluation
- WWW - Upsc.gov - in Exams Notifications 2014 Ese Notice ESE-2014 EngDocument7 pagesWWW - Upsc.gov - in Exams Notifications 2014 Ese Notice ESE-2014 EngSubhankar UncertainityPas encore d'évaluation
- 1172Document18 pages1172Ameya SohoniPas encore d'évaluation
- Study of Substitute Frame Method of Analysis For Lateral Loading ConditionsDocument39 pagesStudy of Substitute Frame Method of Analysis For Lateral Loading ConditionschauhannishargPas encore d'évaluation
- HP Bitumen HandbookDocument53 pagesHP Bitumen HandbookAnuj Mathur100% (1)
- MITRES 18 001 Strang TableseqDocument4 pagesMITRES 18 001 Strang TableseqSarandos KlikizosPas encore d'évaluation
- Graph TheoryDocument29 pagesGraph TheoryAbhishek MajiPas encore d'évaluation
- Tunnel Blasting TechniquesDocument24 pagesTunnel Blasting TechniquesAbhishek MajiPas encore d'évaluation
- Design of Steel StructuresDocument3 pagesDesign of Steel StructuresAbhishek Maji100% (1)
- Structural-Systems For Strands, Ropes and CablesDocument8 pagesStructural-Systems For Strands, Ropes and CablesAbhishek MajiPas encore d'évaluation
- Tata 4923 3Document2 pagesTata 4923 3Abhishek MajiPas encore d'évaluation
- Graph TheoryDocument29 pagesGraph TheoryAbhishek MajiPas encore d'évaluation
- SP16-Design Aid For RC To IS456-1978Document252 pagesSP16-Design Aid For RC To IS456-1978sateeshsingh90% (20)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (399)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (121)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- Abstract - Seminar - Hyderabad - 3-5 Dec 2008Document107 pagesAbstract - Seminar - Hyderabad - 3-5 Dec 2008kali1Pas encore d'évaluation
- Grohmann (2004) Morphometric Analysis in Geographic Information SystemsDocument13 pagesGrohmann (2004) Morphometric Analysis in Geographic Information SystemsJimmy GonzálezPas encore d'évaluation
- Applications of GIS & RS For Wetland Management in Mudigere Taluk, Chikkamagalur District, KarnatakaDocument7 pagesApplications of GIS & RS For Wetland Management in Mudigere Taluk, Chikkamagalur District, KarnatakaLPas encore d'évaluation
- FME 설명자료 How to Bring 2D Data into CesiumJSDocument12 pagesFME 설명자료 How to Bring 2D Data into CesiumJSstormstonePas encore d'évaluation
- DBT123 Chapter 6 - Calculation of Area and VolumeDocument38 pagesDBT123 Chapter 6 - Calculation of Area and Volumeiisya6232Pas encore d'évaluation
- CatchmentSIM ManualDocument156 pagesCatchmentSIM Manualpramod702487Pas encore d'évaluation
- Aerscreen User GuideDocument104 pagesAerscreen User GuideJean RisquezPas encore d'évaluation
- ROI - Pac Internals: Eric Fielding Jet Propulsion Laboratory, California Inst. of TechDocument71 pagesROI - Pac Internals: Eric Fielding Jet Propulsion Laboratory, California Inst. of Tech王文涛Pas encore d'évaluation
- The Significance of Morphometric Analysis To Understand The Hydrological and Morphological Characteristics in Two Different Morpho Climatic SettingsDocument16 pagesThe Significance of Morphometric Analysis To Understand The Hydrological and Morphological Characteristics in Two Different Morpho Climatic SettingsKhristian EnggarPas encore d'évaluation
- WRR 99Document10 pagesWRR 99aljmoralesparPas encore d'évaluation
- Hydrological Simulation of Runoff For A Watershed in Punpun Basin Using SWATDocument5 pagesHydrological Simulation of Runoff For A Watershed in Punpun Basin Using SWATAbdul QuadirPas encore d'évaluation
- Tetra Drone ID - WEBINAR - II - SharedDocument58 pagesTetra Drone ID - WEBINAR - II - SharedryithanPas encore d'évaluation
- Final Detail Report PHA RWP (04-08-2021)Document76 pagesFinal Detail Report PHA RWP (04-08-2021)Ahmed ButtPas encore d'évaluation
- Ain Shams Engineering Journal: Ismail ElkhrachyDocument11 pagesAin Shams Engineering Journal: Ismail ElkhrachyfajriPas encore d'évaluation
- Novel Landslide Susceptibility Mapping Based On Multi-Criteria Decision-Making in Ouro Preto, BrazilDocument18 pagesNovel Landslide Susceptibility Mapping Based On Multi-Criteria Decision-Making in Ouro Preto, BrazilEnner Herenio de AlcântaraPas encore d'évaluation
- April 14, 2023 1Document79 pagesApril 14, 2023 1tejeswarPas encore d'évaluation
- Case StudyDocument8 pagesCase StudygolmalmailPas encore d'évaluation
- Satellite Photogrammetry: Presented By-Sumit Singh (20520010) Sourav Sangam (20520008) Parth Solanki (20520004)Document46 pagesSatellite Photogrammetry: Presented By-Sumit Singh (20520010) Sourav Sangam (20520008) Parth Solanki (20520004)Sourav SangamPas encore d'évaluation
- اشتقاق المعلومات الجيمورفولوجية من البيانات الرادارية باستخدام نظم المعلومات الجغرافيةDocument15 pagesاشتقاق المعلومات الجيمورفولوجية من البيانات الرادارية باستخدام نظم المعلومات الجغرافيةmahmoud abdelrahmanPas encore d'évaluation
- Lab1 1Document2 pagesLab1 1Enoch ArdenPas encore d'évaluation
- Identification of Ground Water Recharge PotentialDocument6 pagesIdentification of Ground Water Recharge PotentialMario ignatioPas encore d'évaluation
- IKONOS Satellite, Imagery, and Products PDFDocument14 pagesIKONOS Satellite, Imagery, and Products PDFsanda anaPas encore d'évaluation
- Allplan 2009 Step by Step GeodesyDocument154 pagesAllplan 2009 Step by Step GeodesyagushayaPas encore d'évaluation
- Hydraulic Modeling of Magdalena River Using Sobek: July 2015Document14 pagesHydraulic Modeling of Magdalena River Using Sobek: July 2015Katharine Fitata SilvaPas encore d'évaluation
- GIS Work Book - teoretical curs - русDocument74 pagesGIS Work Book - teoretical curs - русblah2224Pas encore d'évaluation
- Morphometric Analysis in Varuna River Basin A Geoinformatics Based AnalysisDocument10 pagesMorphometric Analysis in Varuna River Basin A Geoinformatics Based AnalysisIJRASETPublicationsPas encore d'évaluation
- Laser Cutting A Topographical MapDocument15 pagesLaser Cutting A Topographical MapdsticPas encore d'évaluation
- Low Visibility Operation - Desktop AssessmentDocument4 pagesLow Visibility Operation - Desktop AssessmentBruno RamioullePas encore d'évaluation
- Catchment SIMDocument2 pagesCatchment SIMhectorh57Pas encore d'évaluation
- Analysis of Raster Coverage (MDE) of The Portoviejo River BasinDocument9 pagesAnalysis of Raster Coverage (MDE) of The Portoviejo River BasinJefferson SanchezPas encore d'évaluation