Vous aimerez peut-être aussi
- Gerencia de Marca Proyecto Final 3er ParcialDocument14 pagesGerencia de Marca Proyecto Final 3er ParcialJorge GonzalezPas encore d'évaluation
- Tipos de ConcentradoresDocument5 pagesTipos de ConcentradoresNestor Martiñon ValdezPas encore d'évaluation
- Comercion Electronico Unidad No.5 Grupo 2 Seccion W12Document7 pagesComercion Electronico Unidad No.5 Grupo 2 Seccion W12Michelle RomeroPas encore d'évaluation
- Microsoft ProjectDocument23 pagesMicrosoft ProjectGaspar RodriguezPas encore d'évaluation
- ¿Cual Es La Importancia de La Auditoría InformáticaDocument2 pages¿Cual Es La Importancia de La Auditoría InformáticanicolediiazPas encore d'évaluation
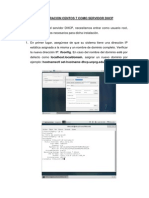
- Configuracion Centos 7 Como Servidor DHCP PDFDocument6 pagesConfiguracion Centos 7 Como Servidor DHCP PDFHanks DíazPas encore d'évaluation
- Evolución de Los MicroprocesadoresDocument15 pagesEvolución de Los MicroprocesadoresJhon Vivero100% (1)
- TP #2 EncriptadoClasicoDocument8 pagesTP #2 EncriptadoClasicoYapmfl FloresPas encore d'évaluation
- Trabajo Monografia de CompiladoresDocument17 pagesTrabajo Monografia de CompiladoresKatherin MestasPas encore d'évaluation
- Code 2 CONJUNTO DE INSTRUCCIONES c6 - v2 PDFDocument87 pagesCode 2 CONJUNTO DE INSTRUCCIONES c6 - v2 PDFJefferson ParedesPas encore d'évaluation
- Informe Del Robot de 3 Grados de LibertadDocument32 pagesInforme Del Robot de 3 Grados de LibertadCristhian Garcia VillarroelPas encore d'évaluation
- TP 01 UaiDocument10 pagesTP 01 UaiLucas RomanoPas encore d'évaluation
- Control2 2Document53 pagesControl2 2Walter Medina LopezPas encore d'évaluation
- Ensamblador Arreglos Final4Document35 pagesEnsamblador Arreglos Final4ShiLd DN0% (1)
- Herramienta Radio LinkDocument14 pagesHerramienta Radio LinkMilena ColmenaresPas encore d'évaluation
- Proyecto Servicios en RedDocument4 pagesProyecto Servicios en RedJose Roman Exposito MartínezPas encore d'évaluation
- FP SolucionesDocument12 pagesFP SolucionesChisco AlarcónPas encore d'évaluation
- Sistema PertDocument22 pagesSistema Pertrodriahum100% (1)
- Historia de La TelefoníaDocument3 pagesHistoria de La TelefoníaDiego Andres GuachaminPas encore d'évaluation
- Sena Vectores en C++Document18 pagesSena Vectores en C++xxxAFDxPas encore d'évaluation
- Ecuaciones No Lineales-Trabajo GrupalDocument18 pagesEcuaciones No Lineales-Trabajo GrupalFernando GeronimoPas encore d'évaluation
- Ejemplo de Trafico TelefonicoDocument4 pagesEjemplo de Trafico TelefonicoLuis AngelPas encore d'évaluation
- Tema 6 MRU IDocument11 pagesTema 6 MRU IAngel JesusPas encore d'évaluation
- Estado Del Arte de Los PLC'sDocument3 pagesEstado Del Arte de Los PLC'sBernie EscobarPas encore d'évaluation
- Practica2 QosDocument30 pagesPractica2 QoswilberPas encore d'évaluation
- Error de CuantificaciónDocument2 pagesError de CuantificaciónLuis Ernesto Palmar100% (1)
- 4.3.2.3 Lab - Using Steganography - AlexandraDocument3 pages4.3.2.3 Lab - Using Steganography - AlexandraAle Ortiz SolisPas encore d'évaluation
- Practica 2Document1 pagePractica 2L0G4N J0RELPas encore d'évaluation
- Matrices y Vectores ProgramacionDocument2 pagesMatrices y Vectores ProgramacionFrank Saldaña ReyesPas encore d'évaluation
- Web SemanticaDocument4 pagesWeb SemanticaIsmael FugfjgjPas encore d'évaluation
- Aplicacion Del Analisis Estadistico Gestion MantenimientoDocument54 pagesAplicacion Del Analisis Estadistico Gestion MantenimientoAngela Centofanti RodriguezPas encore d'évaluation
- Plantilla Examen ParcialDocument3 pagesPlantilla Examen ParcialalessandroPas encore d'évaluation
- Ejercicios Sobre Cálculo ProposicionalDocument7 pagesEjercicios Sobre Cálculo Proposicionaldirección de tecnologíaPas encore d'évaluation
- Aero Pendu LoDocument21 pagesAero Pendu LoDaniel Zuñiga100% (1)
- Instrucciones para La Instalacion de ISE en WindowsDocument22 pagesInstrucciones para La Instalacion de ISE en WindowsSalazar UchihaPas encore d'évaluation
- EnsayoDocument16 pagesEnsayoEduardo Martinez RamirezPas encore d'évaluation
- Modelo de TransportaciónDocument11 pagesModelo de TransportaciónMiguel Angel Berihuete ReyesPas encore d'évaluation
- Normas Icontec Relacionadas Con Control Numerico de MáquinasDocument14 pagesNormas Icontec Relacionadas Con Control Numerico de MáquinasDanilo Ariza GtzPas encore d'évaluation
- Especialidad ITICDocument7 pagesEspecialidad ITICAnonymous p1O7OpKjK5Pas encore d'évaluation
- ZapateriaDocument10 pagesZapateriaUser0% (1)
- Capitulo 7Document6 pagesCapitulo 7lizetharomeroc9585Pas encore d'évaluation
- Copia El Siguiente TextoDocument2 pagesCopia El Siguiente TextoMaria Alonso PérezPas encore d'évaluation
- Practica 1Document3 pagesPractica 1Alexandra De la CruzPas encore d'évaluation
- Costos Del ProyectoDocument4 pagesCostos Del ProyectoDAVID ESTEBAN GARNICA HERNANDEZPas encore d'évaluation
- Guia 2 Informe Final MicroprocesadoresDocument29 pagesGuia 2 Informe Final MicroprocesadoresCarlos Zevallos100% (1)
- Informe Planta NeumáticosDocument10 pagesInforme Planta NeumáticosAndres Torres100% (1)
- Electronics WorkbenchDocument6 pagesElectronics WorkbenchwosnathairPas encore d'évaluation
- Antecedentes HistóricosDocument2 pagesAntecedentes HistóricosFlor TorresPas encore d'évaluation
- Microondas 1Document48 pagesMicroondas 1JoelRafaelPas encore d'évaluation
- 11.6.6 Lab - Calcular Subnets Ipv4Document4 pages11.6.6 Lab - Calcular Subnets Ipv4ROBERTH MARTIN GONZALEZ TAPIA100% (1)
- Informe Laboratorio MPLSDocument36 pagesInforme Laboratorio MPLSEdu Cartagena100% (1)
- Ejemplo de Análisis Dofa para Una Empresa 2017-01-26 PDFDocument4 pagesEjemplo de Análisis Dofa para Una Empresa 2017-01-26 PDFJuvenal Córdoba ValoyesPas encore d'évaluation
- TEMA-6 Procedure y FuncionesDocument4 pagesTEMA-6 Procedure y FuncionesJean Carlos Abreu ColladoPas encore d'évaluation
- Informe - Amplificador de SonidoDocument12 pagesInforme - Amplificador de SonidoErick LlamucaPas encore d'évaluation
- Circuito en Serie AnlogoDocument6 pagesCircuito en Serie AnlogoRaul de la Paz100% (1)
- EA3 EOyEII JDTADocument5 pagesEA3 EOyEII JDTAjorgePas encore d'évaluation
- Tarea de Funciones #4Document2 pagesTarea de Funciones #4Bladii TorresPas encore d'évaluation
- Unidad I Introduccion Al Sistema Manejador de Base de Datos (SMBD)Document12 pagesUnidad I Introduccion Al Sistema Manejador de Base de Datos (SMBD)Juan Lopez SarrelanguePas encore d'évaluation
- Analisis de Algoritmos ParalelosDocument38 pagesAnalisis de Algoritmos ParalelosVictor Hugo BustamantePas encore d'évaluation
- Analisis de Algoritmos Paralelos2Document44 pagesAnalisis de Algoritmos Paralelos2Victor Hugo BustamantePas encore d'évaluation
- Perfil de PracticanteDocument1 pagePerfil de PracticanteosemavPas encore d'évaluation
- Procesos - Antecedentes Generales3 - HAcia La Gestion Por ProcesosDocument37 pagesProcesos - Antecedentes Generales3 - HAcia La Gestion Por ProcesososemavPas encore d'évaluation
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Libro - Las Redes Sociales PDFDocument159 pagesLibro - Las Redes Sociales PDFosemavPas encore d'évaluation
- Curso de Gestion Por ProcesosDocument165 pagesCurso de Gestion Por ProcesososemavPas encore d'évaluation
- Gauss JordanDocument59 pagesGauss JordanJhonny CahuayaPas encore d'évaluation
- Curva - S Proyecto PDFDocument7 pagesCurva - S Proyecto PDFosemavPas encore d'évaluation
- 1plandeempresa (AR) EsDocument15 pages1plandeempresa (AR) EsLa consentida de Los SonesPas encore d'évaluation
- Entorno Politico 2Document48 pagesEntorno Politico 2Jose PavezPas encore d'évaluation
- El Método Delphi, Prospectiva en Ciencias Sociales A Través Del Análisis de Un CasoDocument25 pagesEl Método Delphi, Prospectiva en Ciencias Sociales A Través Del Análisis de Un CasoosemavPas encore d'évaluation
- Poder Estadistico2Document7 pagesPoder Estadistico2Mara_UriPas encore d'évaluation
- TFM JoseMGrandaDocument0 pageTFM JoseMGrandaLuis QuilluyaPas encore d'évaluation
- Uso de Mds en PsicoterapiaDocument30 pagesUso de Mds en PsicoterapiaosemavPas encore d'évaluation
- El Analisisi de Escalamiento-MultidimensionalDocument20 pagesEl Analisisi de Escalamiento-MultidimensionalosemavPas encore d'évaluation
- Analisis Multivariante - Tecnicas Estadisticas Multivariante para La Generacion de Variables LatentesDocument12 pagesAnalisis Multivariante - Tecnicas Estadisticas Multivariante para La Generacion de Variables LatentesosemavPas encore d'évaluation
- Prueba T y Levene SPSSDocument25 pagesPrueba T y Levene SPSSosemavPas encore d'évaluation
- Analisis FactorialDocument5 pagesAnalisis FactorialJordan Camarena HinostrozaPas encore d'évaluation
- Taller InstrumentosDocument56 pagesTaller InstrumentosNash Rodriguez RomeroPas encore d'évaluation
- Test Psicometricos Conf y ValdDocument24 pagesTest Psicometricos Conf y ValdRafael E Jimenez ContrerasPas encore d'évaluation
- 5.analisis ClusterDocument20 pages5.analisis ClusterJuany Li BritanniaPas encore d'évaluation
- Validez de Los Tests y El Análisis Factorial - Nociones GeneralesDocument5 pagesValidez de Los Tests y El Análisis Factorial - Nociones GeneralesosemavPas encore d'évaluation
- Tema6 - MulticolinealidadDocument10 pagesTema6 - MulticolinealidadosemavPas encore d'évaluation
- La Distribución Normal y RDocument39 pagesLa Distribución Normal y RosemavPas encore d'évaluation
- Olivo Batanero 2011Document8 pagesOlivo Batanero 2011osemavPas encore d'évaluation
- Valor GanadoDocument3 pagesValor GanadoNely Tipula QuispePas encore d'évaluation
- Analisis Multivariantes - TecnicasDocument17 pagesAnalisis Multivariantes - TecnicasosemavPas encore d'évaluation
- Analisis Multivariante - Psicologia ExperimentalDocument12 pagesAnalisis Multivariante - Psicologia ExperimentalosemavPas encore d'évaluation
- Cluster 1Document17 pagesCluster 1Anonymous iH6noeaX7Pas encore d'évaluation
- Libro - Fao Manual Herramientas Gerenciales para Empresas AgroindustrialesDocument577 pagesLibro - Fao Manual Herramientas Gerenciales para Empresas AgroindustrialesosemavPas encore d'évaluation
- Demanda Individual y Del Mercado 02Document32 pagesDemanda Individual y Del Mercado 02lilianmaribellaPas encore d'évaluation
- Calculo en Instalaciones NeomaticasDocument12 pagesCalculo en Instalaciones NeomaticasRoberto MartinezPas encore d'évaluation
- Potencial ElectricoDocument15 pagesPotencial ElectricoVictor Castro :vPas encore d'évaluation
- ¿Matemático, Yo ¡Claro Que Sí! (Parte 2) 11-11-2020Document5 pages¿Matemático, Yo ¡Claro Que Sí! (Parte 2) 11-11-2020Noelia CarrilloPas encore d'évaluation
- Conociendo Mis Logros 2024-Reunión InformativaDocument19 pagesConociendo Mis Logros 2024-Reunión Informativaerasmo64100% (2)
- MPRL (3) Examen Inc 4Document26 pagesMPRL (3) Examen Inc 4fernandoPas encore d'évaluation
- Actividad # 3 Estudio de Caso Métodos de Interpretación JuridicaDocument20 pagesActividad # 3 Estudio de Caso Métodos de Interpretación Juridicaxiomara benitezPas encore d'évaluation
- Caracteristicas de La Industria QuimicaDocument22 pagesCaracteristicas de La Industria Quimicaprincesslove521_4165Pas encore d'évaluation
- Curso Gratuito Formacion de Capacitadores CertificadosDocument102 pagesCurso Gratuito Formacion de Capacitadores CertificadosCarlos RiveraPas encore d'évaluation
- DD072 Herramientas Inform Ticas de Gesti N de ProyectosDocument4 pagesDD072 Herramientas Inform Ticas de Gesti N de Proyectosalvaro villamizarPas encore d'évaluation
- Tesis Doctoral Valoracion de La Satisfaccion, El Desempeño y La Imagen Del Destino Por Los Guias de TurismoDocument255 pagesTesis Doctoral Valoracion de La Satisfaccion, El Desempeño y La Imagen Del Destino Por Los Guias de TurismomidumePas encore d'évaluation
- Elementos de La Pre LecturaDocument1 pageElementos de La Pre LecturaFernando YzfPas encore d'évaluation
- Injertacion de CacaoDocument18 pagesInjertacion de CacaorosaPas encore d'évaluation
- Sistema Nervioso CentralDocument7 pagesSistema Nervioso CentralMondongo gokuPas encore d'évaluation
- Trabajo Final de ProceDocument66 pagesTrabajo Final de ProcenormancolindresPas encore d'évaluation
- Maribel y La Extraña FamiliaDocument8 pagesMaribel y La Extraña FamiliaPaloma GomisPas encore d'évaluation
- CerusitaDocument28 pagesCerusitaCarlos LlonaPas encore d'évaluation
- TRIPTICODocument2 pagesTRIPTICOkatherinePas encore d'évaluation
- Examen Parcial de CultivosDocument2 pagesExamen Parcial de CultivosKony MbgPas encore d'évaluation
- Trabajo Práctico MagnetismoDocument4 pagesTrabajo Práctico Magnetismontvg_3Pas encore d'évaluation
- Canino InferiorDocument1 pageCanino Inferiormaru palloPas encore d'évaluation
- Plan Educativo 2021 SmaDocument85 pagesPlan Educativo 2021 SmaCarlos BravoPas encore d'évaluation
- AlimentaciónDocument8 pagesAlimentaciónFausto Snk GarcesPas encore d'évaluation
- MIC-MONITOR y EVALUACIONDocument19 pagesMIC-MONITOR y EVALUACIONMilena GuaripaPas encore d'évaluation
- Requisitos para La Autorizacion Sanitaria para El Funcionamiento de Mataderos y Su Renovacion PDFDocument4 pagesRequisitos para La Autorizacion Sanitaria para El Funcionamiento de Mataderos y Su Renovacion PDFPatricia Pereda SimoniPas encore d'évaluation
- GASOMETRÍA - para CombinarDocument12 pagesGASOMETRÍA - para Combinarkotikokura15Pas encore d'évaluation
- Empresas Quiebra Supermercado GuatemalaDocument2 pagesEmpresas Quiebra Supermercado GuatemalaYesus EspinozaPas encore d'évaluation
- Guia de Aprendizaje Conservacion de Recursos NaturalesDocument7 pagesGuia de Aprendizaje Conservacion de Recursos Naturalesdairo100% (6)
- Linea Del TiempoDocument5 pagesLinea Del TiempoDavid Ferreyra25% (4)
- Formato de Presupuesto de CasaDocument12 pagesFormato de Presupuesto de CasaAB Sagma100% (1)
- Informe Final Accidente HK2118Document28 pagesInforme Final Accidente HK2118Alexander VasquezPas encore d'évaluation