Vous aimerez peut-être aussi
- Conceptual Programming: Conceptual Programming: Learn Programming the old way!D'EverandConceptual Programming: Conceptual Programming: Learn Programming the old way!Pas encore d'évaluation
- CA Document 1Document8 pagesCA Document 1ToobaPas encore d'évaluation
- Interview Questions for IBM Mainframe DevelopersD'EverandInterview Questions for IBM Mainframe DevelopersÉvaluation : 1 sur 5 étoiles1/5 (1)
- Parallel ProcessingDocument4 pagesParallel Processingnikhilesh walde100% (1)
- Parallel ProcessingDocument31 pagesParallel ProcessingSantosh SinghPas encore d'évaluation
- Parallel Algorithm - Intro and Computational ModelsDocument5 pagesParallel Algorithm - Intro and Computational ModelszololuxyPas encore d'évaluation
- Parallel Computer Models: PCA Chapter 1Document61 pagesParallel Computer Models: PCA Chapter 1AYUSH KUMARPas encore d'évaluation
- Parallel AlgorithmDocument48 pagesParallel AlgorithmBipin SaraswatPas encore d'évaluation
- CA Unit IV Notes Part 1 PDFDocument17 pagesCA Unit IV Notes Part 1 PDFaarockiaabins AP - II - CSEPas encore d'évaluation
- Large Computer Systems and Pipelining: HomeworkDocument11 pagesLarge Computer Systems and Pipelining: HomeworkRyan ReyesPas encore d'évaluation
- Parallel Computing (Unit5)Document25 pagesParallel Computing (Unit5)Shriniwas YadavPas encore d'évaluation
- Artificial IntelligenceDocument12 pagesArtificial IntelligenceHimanshu MishraPas encore d'évaluation
- Parallel ComputingDocument32 pagesParallel ComputingKhushal BisaniPas encore d'évaluation
- Mpi, Openmp, Matlab P: 2.1 Programming StyleDocument15 pagesMpi, Openmp, Matlab P: 2.1 Programming StyleWeb devPas encore d'évaluation
- CA Classes-16-20Document5 pagesCA Classes-16-20SrinivasaRaoPas encore d'évaluation
- Unit 7 - Parallel Processing ParadigmDocument26 pagesUnit 7 - Parallel Processing ParadigmMUHMMAD ZAID KURESHIPas encore d'évaluation
- PDC - Lecture - No. 2Document31 pagesPDC - Lecture - No. 2nauman tariqPas encore d'évaluation
- CS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesDocument47 pagesCS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesNehaPas encore d'évaluation
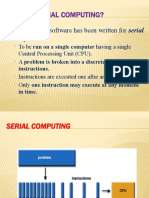
- What Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDocument22 pagesWhat Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDivya NigamPas encore d'évaluation
- 5 Marks Q. Describe Array Processor ArchitectureDocument11 pages5 Marks Q. Describe Array Processor ArchitectureGaurav BiswasPas encore d'évaluation
- Week1 - Parallel and Distributed ComputingDocument46 pagesWeek1 - Parallel and Distributed ComputingA NPas encore d'évaluation
- Introduction To Parallel ProcessingDocument29 pagesIntroduction To Parallel ProcessingAzri Mohd KhanilPas encore d'évaluation
- 24-25 - Parallel Processing PDFDocument36 pages24-25 - Parallel Processing PDFfanna786Pas encore d'évaluation
- TaxonomiesDocument15 pagesTaxonomiesBoris DJIONGOPas encore d'évaluation
- Introduction To Parallel ProcessingDocument49 pagesIntroduction To Parallel ProcessingShobhit MahawarPas encore d'évaluation
- Flynn's Taxonomy of Computer ArchitectureDocument8 pagesFlynn's Taxonomy of Computer ArchitectureRajani SurejaPas encore d'évaluation
- Use of DAG in Distributed Parallel ComputingDocument5 pagesUse of DAG in Distributed Parallel ComputingInternational Journal of Application or Innovation in Engineering & ManagementPas encore d'évaluation
- Esraa Assignment 3Document17 pagesEsraa Assignment 3رمقالحياةPas encore d'évaluation
- FinalDocument26 pagesFinalHứa Đăng KhoaPas encore d'évaluation
- FlynnDocument2 pagesFlynnhasanrazaa651Pas encore d'évaluation
- Parallel Computing Seminar ReportDocument35 pagesParallel Computing Seminar ReportAmeya Waghmare100% (3)
- Parallel Processing in Processor Organization: Prabhudev S IrabashettiDocument4 pagesParallel Processing in Processor Organization: Prabhudev S IrabashettiAdiq CoolPas encore d'évaluation
- Lecture Parallelism DC PDFDocument7 pagesLecture Parallelism DC PDFDivy Kumar GuptaPas encore d'évaluation
- Introduction To Parallel Processors: Coa SeminarDocument17 pagesIntroduction To Parallel Processors: Coa SeminarAyapilla Sri hari PranavPas encore d'évaluation
- Parallel ComputingDocument34 pagesParallel ComputingBittu VermaPas encore d'évaluation
- Parallel ProcessingDocument33 pagesParallel ProcessingShivansh tomarPas encore d'évaluation
- COMP28112 Lecture 2: Challenges/goals With Distributed SystemsDocument12 pagesCOMP28112 Lecture 2: Challenges/goals With Distributed Systemsed macPas encore d'évaluation
- Unit 3 NotesDocument9 pagesUnit 3 NotesPurvi ChaurasiaPas encore d'évaluation
- Advanced Computer ArchitectureDocument28 pagesAdvanced Computer ArchitectureSameer KhudePas encore d'évaluation
- Parallel Systems Quick AssesmentDocument5 pagesParallel Systems Quick AssesmentmgminaxPas encore d'évaluation
- Cluster Computing: Dr. C. Amalraj 12/02/2021 The University of Moratuwa Amalraj@uom - LKDocument34 pagesCluster Computing: Dr. C. Amalraj 12/02/2021 The University of Moratuwa Amalraj@uom - LKNishshanka CJPas encore d'évaluation
- ArticuloDocument7 pagesArticuloGonzalo Peñaloza PlataPas encore d'évaluation
- Programação Paralela e DistribuídaDocument39 pagesProgramação Paralela e DistribuídaMarcelo AzevedoPas encore d'évaluation
- SIMD ArchitectureDocument16 pagesSIMD Architecturebinzidd007100% (1)
- Chapter 14: Parallel AlgorithmsDocument23 pagesChapter 14: Parallel AlgorithmsabkavitharamPas encore d'évaluation
- Chapter 9Document28 pagesChapter 9Hiywot yesufPas encore d'évaluation
- 07 - Chapter 1 PDFDocument27 pages07 - Chapter 1 PDFنورالدنياPas encore d'évaluation
- COME6102 Chapter 1 Introduction 2 of 2Document8 pagesCOME6102 Chapter 1 Introduction 2 of 2Franck TiomoPas encore d'évaluation
- Infiniband (Ib) Is A Computer Networking Communications Standard Used in High-PerformanceDocument7 pagesInfiniband (Ib) Is A Computer Networking Communications Standard Used in High-PerformanceMugabe DeogratiousPas encore d'évaluation
- Serial and Parallel First 3 LectureDocument17 pagesSerial and Parallel First 3 LectureAsif KhanPas encore d'évaluation
- What Is Parallel ProcessingDocument4 pagesWhat Is Parallel ProcessingHarryPas encore d'évaluation
- CA Classes-221-225Document5 pagesCA Classes-221-225SrinivasaRaoPas encore d'évaluation
- Assignment # 2: Name: M. NasirDocument12 pagesAssignment # 2: Name: M. NasirMuhammad UmerPas encore d'évaluation
- Unit VI Parallel Programming ConceptsDocument90 pagesUnit VI Parallel Programming ConceptsPrathameshPas encore d'évaluation
- Parallel Architecture ClassificationDocument41 pagesParallel Architecture ClassificationAbhishek singh0% (1)
- Introduction To Parallel Processing: Shantanu Dutt University of Illinois at ChicagoDocument51 pagesIntroduction To Parallel Processing: Shantanu Dutt University of Illinois at ChicagoDattatray BhatePas encore d'évaluation
- Introduction To Concurrent Programming: Operating SystemsDocument18 pagesIntroduction To Concurrent Programming: Operating Systemsonkar khavalePas encore d'évaluation
- Interconnection Network ArchitecturesDocument54 pagesInterconnection Network ArchitecturesLe ProfessionistPas encore d'évaluation
- Maram Assignment IDocument7 pagesMaram Assignment Imemohzazi47Pas encore d'évaluation
- Data Parallel AlgorithmsDocument14 pagesData Parallel AlgorithmsmilhousevvpPas encore d'évaluation
- MS9200 Technical ManualDocument100 pagesMS9200 Technical ManualMarcelo OrtizPas encore d'évaluation
- Electricity EngineeringDocument120 pagesElectricity Engineeringttai76649Pas encore d'évaluation
- 9A04701 Embedded Real Time Operating SystemsDocument4 pages9A04701 Embedded Real Time Operating SystemssivabharathamurthyPas encore d'évaluation
- ChecklistDocument8 pagesChecklistSrikar Reddy GummadiPas encore d'évaluation
- PDS - II Lecture NotesDocument303 pagesPDS - II Lecture NotesVinitha.s SaravananPas encore d'évaluation
- Cds13190ev M190 VcuDocument8 pagesCds13190ev M190 VcuTeerajet Chumrunworakiat100% (1)
- Okuma Osp5000Document2 pagesOkuma Osp5000Zoran VujadinovicPas encore d'évaluation
- Booth MultiplierDocument5 pagesBooth MultiplierSyed HyderPas encore d'évaluation
- Slides 09Document41 pagesSlides 09ERIPIDIUSPas encore d'évaluation
- Iptv - RTMP RTSP HLSDocument9 pagesIptv - RTMP RTSP HLSpjvlenterprisesPas encore d'évaluation
- On Chip Variation and CRPRDocument12 pagesOn Chip Variation and CRPRnizam_shaik100% (6)
- Hamdard University Islamabad Campus: Lab TaskDocument4 pagesHamdard University Islamabad Campus: Lab TaskUmer FarooqPas encore d'évaluation
- MSI RTX3070 V390 PG142-B00 Rev 1.0Document54 pagesMSI RTX3070 V390 PG142-B00 Rev 1.0fremerc93Pas encore d'évaluation
- Clavia USB Driver v3.0x Installation InstructionsDocument2 pagesClavia USB Driver v3.0x Installation Instructionshammer32Pas encore d'évaluation
- Networking in AWS - Part 1Document39 pagesNetworking in AWS - Part 1sai bPas encore d'évaluation
- Sony mvs8000 Operation ManualDocument18 pagesSony mvs8000 Operation ManualIvan PetrofPas encore d'évaluation
- Emerson Automated Patch Management ServiceDocument8 pagesEmerson Automated Patch Management ServicebioPas encore d'évaluation
- B&R PackMLDocument20 pagesB&R PackMLgo4viewPas encore d'évaluation
- 8251 C Syllabus Anna UnivDocument1 page8251 C Syllabus Anna UnivGunasekaran K AP/CSE-TKECPas encore d'évaluation
- 14.1 Manage Red Hat Enterprise Linux NetworkingDocument9 pages14.1 Manage Red Hat Enterprise Linux Networkingamit_post2000Pas encore d'évaluation
- CSE 4512 Computer Networks-Lab 07Document17 pagesCSE 4512 Computer Networks-Lab 07Ahmad MukaddasPas encore d'évaluation
- Mindfire Solutions Sample Technical Placement Paper Level1Document5 pagesMindfire Solutions Sample Technical Placement Paper Level1placementpapersamplePas encore d'évaluation
- Introduction To Java Programming - RepetitionDocument14 pagesIntroduction To Java Programming - RepetitionElle Xevierre GPas encore d'évaluation
- Technical Application Papers No.9: Bus Communication With ABB Circuit-BreakersDocument116 pagesTechnical Application Papers No.9: Bus Communication With ABB Circuit-BreakersWilliam SilvaPas encore d'évaluation
- Windows Embedded Standard 7 For HP Thin Clients: Administrator GuideDocument24 pagesWindows Embedded Standard 7 For HP Thin Clients: Administrator GuideChaima MedhioubPas encore d'évaluation
- Disk Compression - WikipediaDocument8 pagesDisk Compression - Wikipediarommel baldagoPas encore d'évaluation
- Training Manual LSEDocument530 pagesTraining Manual LSEBulu Mihai100% (1)
- Demux, Encoder, Decoder, ALUDocument25 pagesDemux, Encoder, Decoder, ALUAllan RobeyPas encore d'évaluation
- Rel - Reliability of SystemsDocument11 pagesRel - Reliability of SystemsSusetyo RamadhanyPas encore d'évaluation
- Hardware Price ListDocument2 pagesHardware Price ListKiey WanPas encore d'évaluation
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindD'EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindPas encore d'évaluation
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessD'EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessPas encore d'évaluation
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldD'EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldÉvaluation : 4.5 sur 5 étoiles4.5/5 (107)
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveD'EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurvePas encore d'évaluation
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldD'EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldÉvaluation : 4.5 sur 5 étoiles4.5/5 (55)
- Generative AI: The Insights You Need from Harvard Business ReviewD'EverandGenerative AI: The Insights You Need from Harvard Business ReviewÉvaluation : 4.5 sur 5 étoiles4.5/5 (2)
- Power and Prediction: The Disruptive Economics of Artificial IntelligenceD'EverandPower and Prediction: The Disruptive Economics of Artificial IntelligenceÉvaluation : 4.5 sur 5 étoiles4.5/5 (38)
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesD'EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesÉvaluation : 4.5 sur 5 étoiles4.5/5 (13)
- Demystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)D'EverandDemystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)Évaluation : 4 sur 5 étoiles4/5 (1)
- HBR's 10 Must Reads on AI, Analytics, and the New Machine AgeD'EverandHBR's 10 Must Reads on AI, Analytics, and the New Machine AgeÉvaluation : 4.5 sur 5 étoiles4.5/5 (69)
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewD'EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewÉvaluation : 4.5 sur 5 étoiles4.5/5 (104)
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkD'EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkÉvaluation : 4 sur 5 étoiles4/5 (7)
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)D'EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)Pas encore d'évaluation
- 100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziD'Everand100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziPas encore d'évaluation
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepD'EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepÉvaluation : 4.5 sur 5 étoiles4.5/5 (19)
- AI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceD'EverandAI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceÉvaluation : 4 sur 5 étoiles4/5 (2)
- Artificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.D'EverandArtificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Évaluation : 4 sur 5 étoiles4/5 (15)
- Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsD'EverandYour AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsPas encore d'évaluation
- Four Battlegrounds: Power in the Age of Artificial IntelligenceD'EverandFour Battlegrounds: Power in the Age of Artificial IntelligenceÉvaluation : 5 sur 5 étoiles5/5 (5)
- Artificial Intelligence: A Guide for Thinking HumansD'EverandArtificial Intelligence: A Guide for Thinking HumansÉvaluation : 4.5 sur 5 étoiles4.5/5 (30)
- The Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsD'EverandThe Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsPas encore d'évaluation
- Fusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureD'EverandFusion Strategy: How Real-Time Data and AI Will Power the Industrial FuturePas encore d'évaluation