Vous aimerez peut-être aussi
- Statistics for Bioinformatics: Methods for Multiple Sequence AlignmentD'EverandStatistics for Bioinformatics: Methods for Multiple Sequence AlignmentPas encore d'évaluation
- CLG418 (Dcec) PM 201409022-EnDocument1 143 pagesCLG418 (Dcec) PM 201409022-EnMauricio WijayaPas encore d'évaluation
- BackgroundsDocument13 pagesBackgroundsRaMinah100% (8)
- A Copula Approach For Detecting Prognostic Genes Associated With Survival Outcome in MICROARRAY STUDIESDocument10 pagesA Copula Approach For Detecting Prognostic Genes Associated With Survival Outcome in MICROARRAY STUDIESaaasidPas encore d'évaluation
- Using Bayesian Networks To Analyze Expression Data: Nir Friedman Michal LinialDocument25 pagesUsing Bayesian Networks To Analyze Expression Data: Nir Friedman Michal LinialAgung Prihadi SuharyonoPas encore d'évaluation
- Sequence AnalysisDocument6 pagesSequence Analysisharrison9Pas encore d'évaluation
- Applications of Combinatorics To Molecular Biology: Michael S. WATERMANDocument18 pagesApplications of Combinatorics To Molecular Biology: Michael S. WATERMANMarcos Valero TorresPas encore d'évaluation
- Network-Based Regulatory Pathways AnalysisDocument11 pagesNetwork-Based Regulatory Pathways Analysispanna1Pas encore d'évaluation
- Jackson 1993 - Stopping Rules in PCADocument12 pagesJackson 1993 - Stopping Rules in PCAvojarufosiPas encore d'évaluation
- DownloadDocument19 pagesDownloadJude Sopulu OzoikePas encore d'évaluation
- Computational GenomicsDocument5 pagesComputational Genomicswatson191Pas encore d'évaluation
- Using Bayesian Networks To Analyze Expression DataDocument20 pagesUsing Bayesian Networks To Analyze Expression DataSaad Murtaza KhanPas encore d'évaluation
- Perbutational Single Cell OmicsDocument16 pagesPerbutational Single Cell OmicsGANYA U 2022 Batch,PES UniversityPas encore d'évaluation
- Integration and Variable Selection of Omics' Datap87Document20 pagesIntegration and Variable Selection of Omics' Datap87gustavo rodriguezPas encore d'évaluation
- Computer Science and High Dimensional Data ModellingDocument6 pagesComputer Science and High Dimensional Data ModellingIJRASETPublicationsPas encore d'évaluation
- Bio in For Ma TicsDocument8 pagesBio in For Ma TicsAdrian IvanPas encore d'évaluation
- Bio in For Ma TicsDocument7 pagesBio in For Ma TicsHarshit TayalPas encore d'évaluation
- Systematic Validation and Improvement of Quantum Chemistry Methods For The Prediction of Physical and Chemical PropertiesDocument2 pagesSystematic Validation and Improvement of Quantum Chemistry Methods For The Prediction of Physical and Chemical PropertiesElectro_LitePas encore d'évaluation
- Lampe 2018Document11 pagesLampe 2018Chloe FanningPas encore d'évaluation
- Debinfer: Bayesian Inference For Dynamical Models of Biological Systems in RDocument27 pagesDebinfer: Bayesian Inference For Dynamical Models of Biological Systems in RshidaoPas encore d'évaluation
- Bio in For Ma TicsDocument9 pagesBio in For Ma TicsRashmi SinhaPas encore d'évaluation
- List of Abstracts: Francis BachDocument5 pagesList of Abstracts: Francis BachTDLemonNhPas encore d'évaluation
- Acta Crystallographica Section D - 2018 - Kovalevskiy - Overview of Refinement Procedures Within REFMAC5 Utilizing DataDocument13 pagesActa Crystallographica Section D - 2018 - Kovalevskiy - Overview of Refinement Procedures Within REFMAC5 Utilizing DataAnna ŚciukPas encore d'évaluation
- Predicting rRNA-, RNA-, and DNA-binding Proteins From Primary Structure With Support Vector MachinesDocument10 pagesPredicting rRNA-, RNA-, and DNA-binding Proteins From Primary Structure With Support Vector MachinesPaula CyntiaPas encore d'évaluation
- Research Paper On RnaDocument7 pagesResearch Paper On Rnagw10ka6s100% (1)
- Mathematical Biology: On The Role of Algebra in Models in Molecular BiologyDocument3 pagesMathematical Biology: On The Role of Algebra in Models in Molecular Biologyreqiqie reqeqePas encore d'évaluation
- Modeling and Simulation of Genetic Regulatory Systems: A Literature ReviewDocument37 pagesModeling and Simulation of Genetic Regulatory Systems: A Literature ReviewsamuelamdePas encore d'évaluation
- Modeling and Simulation of Genetic Regulatory Systems: A Literature ReviewDocument58 pagesModeling and Simulation of Genetic Regulatory Systems: A Literature ReviewKevian ZepedaPas encore d'évaluation
- Phylogenetic Tree of Prokaryotes Based On Complete Genomes Using Fractal and Correlation AnalysesDocument6 pagesPhylogenetic Tree of Prokaryotes Based On Complete Genomes Using Fractal and Correlation AnalysesDeboraRikaAngelitaPas encore d'évaluation
- Genomics 4Document9 pagesGenomics 4MoriwamPas encore d'évaluation
- Groth 2012Document21 pagesGroth 2012László SágiPas encore d'évaluation
- STS Research Paper FinalDocument17 pagesSTS Research Paper FinalericthecmhPas encore d'évaluation
- 1 s2.0 S0006349511022739 MainDocument1 page1 s2.0 S0006349511022739 Mainrully1234Pas encore d'évaluation
- Algorithmic Applications of XPCR: Nat Comput DOI 10.1007/s11047-010-9199-8Document15 pagesAlgorithmic Applications of XPCR: Nat Comput DOI 10.1007/s11047-010-9199-8api-253266324Pas encore d'évaluation
- EcologicalModelling 2002Document16 pagesEcologicalModelling 2002jsyadav.nithPas encore d'évaluation
- 1 s2.0 S0303264718302843 MainDocument12 pages1 s2.0 S0303264718302843 Mainttnb.linuxPas encore d'évaluation
- Modeling T-Cell Activation Using Gene Expression Profiling and State Space ModelsDocument12 pagesModeling T-Cell Activation Using Gene Expression Profiling and State Space ModelsMiguel Angel CastroPas encore d'évaluation
- Microarray ReviewDocument5 pagesMicroarray ReviewhimaPas encore d'évaluation
- Multivariate Curve Resolution: A Possible Tool in The Detection of Intermediate Structures in Protein FoldingDocument13 pagesMultivariate Curve Resolution: A Possible Tool in The Detection of Intermediate Structures in Protein Foldingakshdeep singhPas encore d'évaluation
- DNA Sequencing - Dr. Mirko JancDocument8 pagesDNA Sequencing - Dr. Mirko JancuserscrybdPas encore d'évaluation
- BIO401 Wikipedia Bioinformatics 2.7.2012Document9 pagesBIO401 Wikipedia Bioinformatics 2.7.2012kinjalpcPas encore d'évaluation
- Multivariate Techniques For Parameter Selection and Data Analysis Exemplified by A Study of Pyrethroid NeurotoxicityDocument8 pagesMultivariate Techniques For Parameter Selection and Data Analysis Exemplified by A Study of Pyrethroid NeurotoxicityAnisa FitriaPas encore d'évaluation
- Flexible MeccanoDocument8 pagesFlexible MeccanoFatima Herranz TrilloPas encore d'évaluation
- Physica A: R. Alvarez-Martínez, G. Cocho, R.F. Rodríguez, G. Martínez-MeklerDocument11 pagesPhysica A: R. Alvarez-Martínez, G. Cocho, R.F. Rodríguez, G. Martínez-MeklerJoel RamosPas encore d'évaluation
- A Novel Model For Dna Sequence Similarity Analysis Based On Graph TheoryDocument10 pagesA Novel Model For Dna Sequence Similarity Analysis Based On Graph TheoryMohd TaufikPas encore d'évaluation
- Using Bayesian Networks To Analyze Expression DataDocument9 pagesUsing Bayesian Networks To Analyze Expression DataChristian BuraboPas encore d'évaluation
- Computational Molecular BiologyDocument27 pagesComputational Molecular Biologyci8084102Pas encore d'évaluation
- Barbosa 2018Document26 pagesBarbosa 2018Bikash Ranjan SamalPas encore d'évaluation
- Computacional BiologyDocument201 pagesComputacional BiologyBruno MartinsPas encore d'évaluation
- An Overview of Gene IdentificationDocument9 pagesAn Overview of Gene IdentificationReadycute ReadyPas encore d'évaluation
- Borodovsky Bioinformatics 2001 PDFDocument3 pagesBorodovsky Bioinformatics 2001 PDFNaura CorporationPas encore d'évaluation
- Bio in For MaticsDocument18 pagesBio in For Maticsowloabi ridwanPas encore d'évaluation
- Image-Based Spatiotemporal Causality Inference For Protein Signaling NetworksDocument8 pagesImage-Based Spatiotemporal Causality Inference For Protein Signaling Networksmtallis3142275Pas encore d'évaluation
- Synopsis: Data Mining Feasibility in Gene Expression Data Analysis Using WekaDocument12 pagesSynopsis: Data Mining Feasibility in Gene Expression Data Analysis Using WekaSharique Afridi KhanPas encore d'évaluation
- CollectionDocument8 pagesCollectionb9226276Pas encore d'évaluation
- An Assimilated Approach For Statistical Genome Streak Assay Between Matriclinous DatasetsDocument6 pagesAn Assimilated Approach For Statistical Genome Streak Assay Between Matriclinous Datasetsvol1no2Pas encore d'évaluation
- Expert Systems With Applications: J.H. Ang, K.C. Tan, A.A. MamunDocument14 pagesExpert Systems With Applications: J.H. Ang, K.C. Tan, A.A. MamunAnonymous TxPyX8cPas encore d'évaluation
- INTERFEROMICSDocument15 pagesINTERFEROMICSAnshul Joshi100% (1)
- Legendre Fortin MER 2010Document14 pagesLegendre Fortin MER 2010Catalina Verdugo ArriagadaPas encore d'évaluation
- Multi-Scale Modeling in Materials Science and EngineeringDocument12 pagesMulti-Scale Modeling in Materials Science and EngineeringonebyzerooutlookPas encore d'évaluation
- Chemometrics in MetabonomicsDocument11 pagesChemometrics in Metabonomicsgustavo rodriguezPas encore d'évaluation
- BIAN How To Guide Developing Content V7.0 Final V1.0 PDFDocument72 pagesBIAN How To Guide Developing Content V7.0 Final V1.0 PDFميلاد نوروزي رهبرPas encore d'évaluation
- When A Snobbish Gangster Meets A Pervert CassanovaDocument62 pagesWhen A Snobbish Gangster Meets A Pervert CassanovaMaria Shiela Mae Baratas100% (1)
- NABARD R&D Seminar FormatDocument7 pagesNABARD R&D Seminar FormatAnupam G. RatheePas encore d'évaluation
- Playing With Pop-Ups - The Art of Dimensional, Moving Paper DesignsDocument147 pagesPlaying With Pop-Ups - The Art of Dimensional, Moving Paper DesignsSara100% (4)
- Codan Rubber Modern Cars Need Modern Hoses WebDocument2 pagesCodan Rubber Modern Cars Need Modern Hoses WebYadiPas encore d'évaluation
- Pulmonary EmbolismDocument48 pagesPulmonary Embolismganga2424100% (3)
- Dwnload Full Beckers World of The Cell 9th Edition Hardin Solutions Manual PDFDocument35 pagesDwnload Full Beckers World of The Cell 9th Edition Hardin Solutions Manual PDFgebbielean1237100% (12)
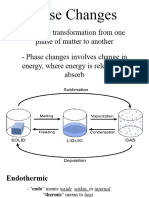
- General Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveDocument19 pagesGeneral Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveJolo Allexice R. PinedaPas encore d'évaluation
- HSCC SRH 0705 PDFDocument1 pageHSCC SRH 0705 PDFBhawna KapoorPas encore d'évaluation
- Csu Cep Professional Dispositions 1Document6 pagesCsu Cep Professional Dispositions 1api-502440235Pas encore d'évaluation
- TESTDocument27 pagesTESTLegal CheekPas encore d'évaluation
- Focus Edition From GC: Phosphate Bonded Investments For C&B TechniquesDocument35 pagesFocus Edition From GC: Phosphate Bonded Investments For C&B TechniquesAlexis De Jesus FernandezPas encore d'évaluation
- BLP#1 - Assessment of Community Initiative (3 Files Merged)Document10 pagesBLP#1 - Assessment of Community Initiative (3 Files Merged)John Gladhimer CanlasPas encore d'évaluation
- Data StructuresDocument4 pagesData StructuresBenjB1983Pas encore d'évaluation
- This Study Resource Was: For The Next 6 ItemsDocument9 pagesThis Study Resource Was: For The Next 6 ItemsJames CastañedaPas encore d'évaluation
- Binge Eating Disorder ANNADocument12 pagesBinge Eating Disorder ANNAloloasbPas encore d'évaluation
- ThorpeDocument267 pagesThorpezaeem73Pas encore d'évaluation
- Asterisk NowDocument82 pagesAsterisk Nowkambojk100% (1)
- 24 DPC-422 Maintenance ManualDocument26 pages24 DPC-422 Maintenance ManualalternativbluePas encore d'évaluation
- Decision Trees For Management of An Avulsed Permanent ToothDocument2 pagesDecision Trees For Management of An Avulsed Permanent ToothAbhi ThakkarPas encore d'évaluation
- 2016 IT - Sheilding Guide PDFDocument40 pages2016 IT - Sheilding Guide PDFlazarosPas encore d'évaluation
- Maritta Koch-Weser, Scott Guggenheim - Social Development in The World Bank - Essays in Honor of Michael M. Cernea-Springer (2021)Document374 pagesMaritta Koch-Weser, Scott Guggenheim - Social Development in The World Bank - Essays in Honor of Michael M. Cernea-Springer (2021)IacobPas encore d'évaluation
- ResumeDocument3 pagesResumeapi-280300136Pas encore d'évaluation
- Chemistry Investigatory Project (R)Document23 pagesChemistry Investigatory Project (R)BhagyashreePas encore d'évaluation
- EKC 202ABC ManualDocument16 pagesEKC 202ABC ManualJose CencičPas encore d'évaluation
- Trade MarkDocument2 pagesTrade MarkRohit ThoratPas encore d'évaluation
- 928 Diagnostics Manual v2.7Document67 pages928 Diagnostics Manual v2.7Roger Sego100% (2)
- Angle Grinder Gws 7 100 06013880f0Document128 pagesAngle Grinder Gws 7 100 06013880f0Kartik ParmeshwaranPas encore d'évaluation