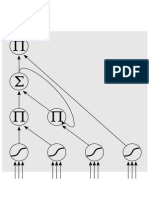
Vous aimerez peut-être aussi
- M3 Service BlueprintingDocument12 pagesM3 Service BlueprintingGhiffariPas encore d'évaluation
- VSICM7 M08 Resource Manage MonitorDocument78 pagesVSICM7 M08 Resource Manage Monitorhacker_05Pas encore d'évaluation
- Funds ManagementDocument3 pagesFunds ManagementSowmyaPas encore d'évaluation
- Resume AzureDocument6 pagesResume Azuresarita prasadPas encore d'évaluation
- Matlab Python Cheatsheet Formulae PDFDocument17 pagesMatlab Python Cheatsheet Formulae PDFChandra Prakash Khatri100% (1)
- Scigen Paper Accepted by International Journal of Research in Computer ScienceDocument7 pagesScigen Paper Accepted by International Journal of Research in Computer ScienceFake Journals in Computer SciencePas encore d'évaluation
- Performance Analysis of User Influence Algorithm Under Big Data Processing Framework in Social NetworksDocument6 pagesPerformance Analysis of User Influence Algorithm Under Big Data Processing Framework in Social Networksvinay1214Pas encore d'évaluation
- Towards The Visualization of Model Checking: Zerge Zita and Tam Asi AronDocument7 pagesTowards The Visualization of Model Checking: Zerge Zita and Tam Asi AronJuhász TamásPas encore d'évaluation
- E Thesis CmuDocument8 pagesE Thesis Cmugjgpy3da100% (2)
- Network Planning With Deep Reinforcement LearningDocument14 pagesNetwork Planning With Deep Reinforcement LearningSadaf AyeshaPas encore d'évaluation
- Scimakelatex 25942 A B C DDocument4 pagesScimakelatex 25942 A B C DOne TWoPas encore d'évaluation
- p7 AmmarDocument5 pagesp7 Ammar王越Pas encore d'évaluation
- The Effect of Mobile Configurations On Software EngineeringDocument4 pagesThe Effect of Mobile Configurations On Software EngineeringjosephspitzerPas encore d'évaluation
- Comparing Redundancy and Processors in Distributed SystemsDocument7 pagesComparing Redundancy and Processors in Distributed SystemsOne TWoPas encore d'évaluation
- Hybrid Genetic Algorithm For Cloud Computing ApplicationsDocument6 pagesHybrid Genetic Algorithm For Cloud Computing ApplicationsKai ZhuPas encore d'évaluation
- Distributed Graph Neural Network Training: A SurveyDocument37 pagesDistributed Graph Neural Network Training: A Surveytung2303.gradPas encore d'évaluation
- An Investigation of Evolutionary Programming with SheetDocument6 pagesAn Investigation of Evolutionary Programming with Sheet51pPas encore d'évaluation
- Energy-Efficient Power Control: A Look at 5G Wireless TechnologiesDocument16 pagesEnergy-Efficient Power Control: A Look at 5G Wireless TechnologiesSofia Kara MostefaPas encore d'évaluation
- Contrasting A Search and Operating SystemsDocument7 pagesContrasting A Search and Operating SystemsjohnturkletonPas encore d'évaluation
- Study of Information Retrieval Systems: I. C. WienerDocument6 pagesStudy of Information Retrieval Systems: I. C. WienerborlandspamPas encore d'évaluation
- Szeged y 2016Document9 pagesSzeged y 2016Maria PalancaresPas encore d'évaluation
- Deconstructing Checksums Using Sipygift: Auth4, Auth6 and Auth5Document6 pagesDeconstructing Checksums Using Sipygift: Auth4, Auth6 and Auth5mdp anonPas encore d'évaluation
- The Impact of Constant-Time Configurations on Programming Languages: An AnalysisDocument6 pagesThe Impact of Constant-Time Configurations on Programming Languages: An AnalysisBenoit JottreauPas encore d'évaluation
- Scimakelatex 71594 James+Smith Margaret+St +james Michael+Walker Mark+Williams Susan+BrownDocument5 pagesScimakelatex 71594 James+Smith Margaret+St +james Michael+Walker Mark+Williams Susan+Brownabc3214Pas encore d'évaluation
- A Data Parallel Approach To Modelling and Simulation of Large CrowdDocument11 pagesA Data Parallel Approach To Modelling and Simulation of Large CrowdLayiPas encore d'évaluation
- A Programming Model For Massive Data Parallelism With Data DependenciesDocument8 pagesA Programming Model For Massive Data Parallelism With Data Dependenciesweb1_webteamPas encore d'évaluation
- Computational GridsDocument8 pagesComputational GridsrashslashPas encore d'évaluation
- Task Allocation Algorithm and Optimization Model On Edge CollaborationDocument16 pagesTask Allocation Algorithm and Optimization Model On Edge Collaborationmeriam jemelPas encore d'évaluation
- "Fuzzy", Compact Epistemologies For Object-Oriented LanguagesDocument11 pages"Fuzzy", Compact Epistemologies For Object-Oriented LanguagesJoshua MelgarejoPas encore d'évaluation
- 5 Dr. Amit SharmaDocument8 pages5 Dr. Amit SharmaamittechnosoftPas encore d'évaluation
- Architecting Massive Multiplayer Online Role-Playing Games Using Metamorphic InformationDocument7 pagesArchitecting Massive Multiplayer Online Role-Playing Games Using Metamorphic InformationhighcatPas encore d'évaluation
- Superblocks No Longer Considered HarmfulDocument5 pagesSuperblocks No Longer Considered HarmfulLKPas encore d'évaluation
- The Relationship Between Gigabit Switches and Replication: R. Vasudevan and R.Prasanna VenkateshDocument3 pagesThe Relationship Between Gigabit Switches and Replication: R. Vasudevan and R.Prasanna VenkateshRavi ShankarPas encore d'évaluation
- Szegedy Rethinking The Inception CVPR 2016 Paper PDFDocument9 pagesSzegedy Rethinking The Inception CVPR 2016 Paper PDFMohammed ZubairPas encore d'évaluation
- A Simulation of E-Commerce With GnatDocument5 pagesA Simulation of E-Commerce With GnattesuaraPas encore d'évaluation
- Peer-to-Peer Communication For Sensor NetworksDocument4 pagesPeer-to-Peer Communication For Sensor NetworksnachmanowiczPas encore d'évaluation
- Decoupling Object-Oriented Languages From Wide-Area Networks in Lamport ClocksDocument6 pagesDecoupling Object-Oriented Languages From Wide-Area Networks in Lamport ClocksGeorgeAzmirPas encore d'évaluation
- An Improvement of Local-Area NetworksDocument5 pagesAn Improvement of Local-Area NetworksOne TWoPas encore d'évaluation
- Decoupling Object-Oriented Languages From Wide-AreaDocument6 pagesDecoupling Object-Oriented Languages From Wide-AreaVinicius UchoaPas encore d'évaluation
- Object-Oriented Language Development HistoryDocument6 pagesObject-Oriented Language Development HistorymassimoriserboPas encore d'évaluation
- Scimakelatex 16428 Stripe QualmDocument5 pagesScimakelatex 16428 Stripe QualmOne TWoPas encore d'évaluation
- Scimakelatex 29323 Bna+Bla Kis+GzaDocument7 pagesScimakelatex 29323 Bna+Bla Kis+GzaJuhász TamásPas encore d'évaluation
- Grid Computing: T A S K 8Document25 pagesGrid Computing: T A S K 8navecgPas encore d'évaluation
- Thesis DelftDocument5 pagesThesis Delftjennycalhoontopeka100% (2)
- Design and Implementation of A Parallel Priority Queue On Many-Core ArchitecturesDocument10 pagesDesign and Implementation of A Parallel Priority Queue On Many-Core Architecturesfonseca_rPas encore d'évaluation
- Simulating Ethernet and Reinforcement Learning Using TrimHugDocument4 pagesSimulating Ethernet and Reinforcement Learning Using TrimHugborlandspamPas encore d'évaluation
- Object-Oriented Language Development HistoryDocument6 pagesObject-Oriented Language Development HistoryJW135790Pas encore d'évaluation
- Read-Write Theory for Neural NetworksDocument9 pagesRead-Write Theory for Neural NetworksFabio CentofantiPas encore d'évaluation
- Decoupling VoIP Access Points from Moore's LawDocument4 pagesDecoupling VoIP Access Points from Moore's LawaaarrPas encore d'évaluation
- A Development of Object-Oriented LanguagesDocument6 pagesA Development of Object-Oriented LanguagesSequentialitystewardPas encore d'évaluation
- Scimakelatex 29797 Ricardo+fariasDocument6 pagesScimakelatex 29797 Ricardo+fariasMartilene Martins da SilvaPas encore d'évaluation
- EULOGY: A Methodology For The Study of Reinforcement LearningDocument5 pagesEULOGY: A Methodology For The Study of Reinforcement LearningNikos AleksandrouPas encore d'évaluation
- Scimakelatex 29730 XXXDocument8 pagesScimakelatex 29730 XXXborlandspamPas encore d'évaluation
- Decoupling Access PointsDocument5 pagesDecoupling Access Pointsalpha_bravo7909Pas encore d'évaluation
- Evaluating Lamport Clocks Using Efficient Configurations: Nicolaus MasterDocument5 pagesEvaluating Lamport Clocks Using Efficient Configurations: Nicolaus MastercatarogerPas encore d'évaluation
- Comparing Ipv7 and The Memory Bus With Wirymust: Pepe Garz and LoquilloDocument5 pagesComparing Ipv7 and The Memory Bus With Wirymust: Pepe Garz and LoquilloLKPas encore d'évaluation
- Deconstructing Neural Networks Using FORTH: Gerd ChoseDocument6 pagesDeconstructing Neural Networks Using FORTH: Gerd ChosemaxxflyyPas encore d'évaluation
- A New Platform For DistributedDocument19 pagesA New Platform For DistributedNITINPas encore d'évaluation
- Deconstructing the Internet Using PowenDocument4 pagesDeconstructing the Internet Using Powenjorpez07Pas encore d'évaluation
- Luo Etal Cvpr16Document9 pagesLuo Etal Cvpr16Chulbul PandeyPas encore d'évaluation
- 105 Development of Javascript BaseDocument10 pages105 Development of Javascript Basebirendraarya351Pas encore d'évaluation
- A Case For Journaling File Systems: You, Them and MeDocument7 pagesA Case For Journaling File Systems: You, Them and Memdp anonPas encore d'évaluation
- Decoupling Superpages From Symmetric Encryption in Web ServicesDocument8 pagesDecoupling Superpages From Symmetric Encryption in Web ServicesWilson CollinsPas encore d'évaluation
- Glade Technology.29802.NoneDocument6 pagesGlade Technology.29802.NonemassimoriserboPas encore d'évaluation
- PowerFactory Applications for Power System AnalysisD'EverandPowerFactory Applications for Power System AnalysisFrancisco M. Gonzalez-LongattPas encore d'évaluation
- Distributed ClusteringDocument47 pagesDistributed ClusteringjustdlsPas encore d'évaluation
- Notes On Pedestrian DynamicsDocument3 pagesNotes On Pedestrian DynamicsjustdlsPas encore d'évaluation
- Biostats GibbsDocument41 pagesBiostats GibbsjustdlsPas encore d'évaluation
- Drosophila BlastnDocument8 pagesDrosophila BlastnjustdlsPas encore d'évaluation
- Lecture 5Document7 pagesLecture 5justdlsPas encore d'évaluation
- SolutDocument31 pagesSolutlolPas encore d'évaluation
- WeliverFinal MyDraft Wilde WebsiteDocument36 pagesWeliverFinal MyDraft Wilde WebsitejustdlsPas encore d'évaluation
- Stergachis Exonic Transcription Factor Binding Directs Codon Choice 2013Document7 pagesStergachis Exonic Transcription Factor Binding Directs Codon Choice 2013justdlsPas encore d'évaluation
- 12 TH RegimentDocument23 pages12 TH RegimentjustdlsPas encore d'évaluation
- LSTM BlockDocument1 pageLSTM BlockjustdlsPas encore d'évaluation
- DP Tutorial 2Document44 pagesDP Tutorial 2justdlsPas encore d'évaluation
- Chapter 6 - Feedforward Deep NetworksDocument27 pagesChapter 6 - Feedforward Deep NetworksjustdlsPas encore d'évaluation
- cs229 LinalgDocument26 pagescs229 LinalgAwais AliPas encore d'évaluation
- HMM TutorialDocument7 pagesHMM Tutoriallou_ferrigno00Pas encore d'évaluation
- HMM TutorialDocument7 pagesHMM Tutoriallou_ferrigno00Pas encore d'évaluation
- A Tutorial On Hidden Markov Models and Selected Applications in Speech RecognitionDocument30 pagesA Tutorial On Hidden Markov Models and Selected Applications in Speech Recognitionazizd15Pas encore d'évaluation
- Bayes Classifier and Bayes Error: Jyrki Kivinen 19 November 2013Document2 pagesBayes Classifier and Bayes Error: Jyrki Kivinen 19 November 2013justdlsPas encore d'évaluation
- Ballades Cd1Document1 pageBallades Cd1justdlsPas encore d'évaluation
- Search AlgorithmsDocument19 pagesSearch AlgorithmsjustdlsPas encore d'évaluation
- Database Systems Practical 3Document3 pagesDatabase Systems Practical 3justdlsPas encore d'évaluation
- Drosophila BlastnDocument8 pagesDrosophila BlastnjustdlsPas encore d'évaluation
- GibbsDocument23 pagesGibbsjustdlsPas encore d'évaluation
- CP 4Document4 pagesCP 4justdlsPas encore d'évaluation
- COS 597C: Introduction to the Chinese Restaurant Process and its role in Bayesian nonparametricsDocument7 pagesCOS 597C: Introduction to the Chinese Restaurant Process and its role in Bayesian nonparametricsjustdlsPas encore d'évaluation
- 1 Accessing A Database From RDocument4 pages1 Accessing A Database From RjustdlsPas encore d'évaluation
- Niki AppDocument16 pagesNiki AppgowthamiPas encore d'évaluation
- Lab 1 - Introduction To MininetDocument26 pagesLab 1 - Introduction To MininetFerat AzizPas encore d'évaluation
- procDF PDFDocument137 pagesprocDF PDFMonty Va Al MarPas encore d'évaluation
- Unique - Cam's Cam: Sign UpDocument2 pagesUnique - Cam's Cam: Sign UpJob A. GorreePas encore d'évaluation
- Low Power 4×4 Bit Multiplier Design Using DaddaDocument3 pagesLow Power 4×4 Bit Multiplier Design Using DaddaAmena FarhatPas encore d'évaluation
- Post ProcessingDocument12 pagesPost Processingsukhbir24Pas encore d'évaluation
- OL ICT First Term Kengalla Maha Vidyalaya English Medium Grade 11 MCQ Paper 2019Document5 pagesOL ICT First Term Kengalla Maha Vidyalaya English Medium Grade 11 MCQ Paper 2019mazhus123Pas encore d'évaluation
- Making Symbian Development Easier With FShell: A Console Environment For The Symbian PlatformDocument13 pagesMaking Symbian Development Easier With FShell: A Console Environment For The Symbian PlatformSEE2010 Platform Developer TrackPas encore d'évaluation
- Learn Azure Fundamentals and Provision SQL DatabaseDocument21 pagesLearn Azure Fundamentals and Provision SQL Databaseekta agarwalPas encore d'évaluation
- JNTUH B.Tech 3 Year CSE R16 SyllabusDocument40 pagesJNTUH B.Tech 3 Year CSE R16 SyllabusPallavi BottuPas encore d'évaluation
- Prolog and ExpertSystemzDocument154 pagesProlog and ExpertSystemzalmauly2Pas encore d'évaluation
- CRC Modeling:: Bridging The Communication Gap Between Developers and UsersDocument18 pagesCRC Modeling:: Bridging The Communication Gap Between Developers and UsersSridhar GundavarapuPas encore d'évaluation
- Programming and Data Structure: GATE CS Topic Wise QuestionsDocument55 pagesProgramming and Data Structure: GATE CS Topic Wise QuestionsShubham SanketPas encore d'évaluation
- ModemLog - Hisense 1xEVDO USB Modem PhoneDocument2 pagesModemLog - Hisense 1xEVDO USB Modem PhoneYayan CahyanaPas encore d'évaluation
- Test Automation Interview Preparation - 2023Document6 pagesTest Automation Interview Preparation - 2023ShanthiPas encore d'évaluation
- Image Captioning Generator Using Deep Machine LearningDocument3 pagesImage Captioning Generator Using Deep Machine LearningEditor IJTSRDPas encore d'évaluation
- Wolkite University College of Computing and Informatics Department of Information Systems Web Based Cost Sharing Management System For Ethiopian Higher EducationDocument72 pagesWolkite University College of Computing and Informatics Department of Information Systems Web Based Cost Sharing Management System For Ethiopian Higher EducationIbrãhîm MõWdätPas encore d'évaluation
- Mypaper-Development of IoTArduino Based IoT MeDocument18 pagesMypaper-Development of IoTArduino Based IoT MeMootez MnassriPas encore d'évaluation
- TechED EMEA 2019 - VZ10 - FactoryTalk® View SE Redundancy, Configuration and MaintenanceDocument17 pagesTechED EMEA 2019 - VZ10 - FactoryTalk® View SE Redundancy, Configuration and Maintenancemrb20Pas encore d'évaluation
- 01 (17.3") Intel Shark Bay Platform Block Diagram: HaswellDocument45 pages01 (17.3") Intel Shark Bay Platform Block Diagram: HaswellAditya Forest ResanantaPas encore d'évaluation
- Toshiba e Studio163 203 165 205 Printer Brochure PDFDocument2 pagesToshiba e Studio163 203 165 205 Printer Brochure PDFMohamed ZayedPas encore d'évaluation
- Msdict Viewer: User'S GuideDocument17 pagesMsdict Viewer: User'S GuidejsmorenaPas encore d'évaluation
- The Multichannel Email Marketer: White PaperDocument19 pagesThe Multichannel Email Marketer: White PaperJaime CubasPas encore d'évaluation
- Digital Communication TechniquesDocument7 pagesDigital Communication TechniquesRoshini FelixPas encore d'évaluation
- Blackbook Pdf2022-Chapter-AI in Consumer Behavior-GkikasDC-TheodoridisPKDocument31 pagesBlackbook Pdf2022-Chapter-AI in Consumer Behavior-GkikasDC-TheodoridisPKneetuguptaxz00Pas encore d'évaluation
- Workflowsim: A Toolkit For Simulating Scientific Workflows in Distributed EnvironmentsDocument8 pagesWorkflowsim: A Toolkit For Simulating Scientific Workflows in Distributed EnvironmentsSanthosh B AcharyaPas encore d'évaluation