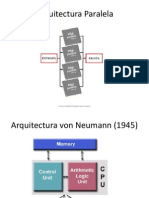
Vous aimerez peut-être aussi
- Arquitecturas MPP & SMPDocument7 pagesArquitecturas MPP & SMPMagaly CedroPas encore d'évaluation
- Sistemas de multiprocesamiento y procesamiento paraleloDocument9 pagesSistemas de multiprocesamiento y procesamiento paraleloElmerCuencaBalabarca0% (1)
- MPP y SMPDocument5 pagesMPP y SMPEfra26100% (1)
- Arquitectura SMP, MPP, SPPDocument4 pagesArquitectura SMP, MPP, SPPZuzan PeñaPas encore d'évaluation
- Arquitectura SMP MPPDocument4 pagesArquitectura SMP MPPAlfredo MontoyaPas encore d'évaluation
- Multiprocesamiento Paralelo 3 - 3parte 1PDocument6 pagesMultiprocesamiento Paralelo 3 - 3parte 1PTomiko FelizPas encore d'évaluation
- Arquitectura SMP y MPPDocument4 pagesArquitectura SMP y MPPManuel71110Pas encore d'évaluation
- Procesamiento ParaleloDocument35 pagesProcesamiento ParaleloJEFFERSON MUÑOZ PARDOPas encore d'évaluation
- Memoria CompartidaDocument5 pagesMemoria CompartidaRolando HuayllaniPas encore d'évaluation
- SMP Arquitectura Multiprocesamiento SimétricoDocument4 pagesSMP Arquitectura Multiprocesamiento Simétricotoxic_gabriel1207Pas encore d'évaluation
- La Arquitectura SMPDocument4 pagesLa Arquitectura SMPliracruzgustavoPas encore d'évaluation
- MPPDocument1 pageMPPchicharo09Pas encore d'évaluation
- Definicion de NUMA y OtrosDocument41 pagesDefinicion de NUMA y OtrosRamón Moreno MalavéPas encore d'évaluation
- Procesamiento ParaleloDocument6 pagesProcesamiento ParaleloResendiz AguilaPas encore d'évaluation
- Programacion en ParaleloDocument6 pagesProgramacion en ParaleloJoshep DPas encore d'évaluation
- Arquitectura ParalelaDocument37 pagesArquitectura ParalelaHitsuji KuroiPas encore d'évaluation
- MultiprocesadoresDocument7 pagesMultiprocesadoresmorris starPas encore d'évaluation
- Procesos Concurrentes - Sistemas OperativosDocument10 pagesProcesos Concurrentes - Sistemas OperativosMICHAELPas encore d'évaluation
- Multi Pro Ces AdoresDocument5 pagesMulti Pro Ces AdoreslalometallicaPas encore d'évaluation
- 4.5 Casos de EstudioDocument5 pages4.5 Casos de EstudioSilvio Dresser0% (1)
- Arquitectura SMPDocument2 pagesArquitectura SMPAldo Buchon GarciaPas encore d'évaluation
- UNIPROCESADORES y MultiprocesadoresDocument21 pagesUNIPROCESADORES y MultiprocesadoresLuis Soriano OsoresPas encore d'évaluation
- Actividad 1.1.1Document14 pagesActividad 1.1.1luisPas encore d'évaluation
- Procesamiento paralelo MIMD: Multiprocesadores y MulticomputadorasDocument11 pagesProcesamiento paralelo MIMD: Multiprocesadores y MulticomputadorasdysanPas encore d'évaluation
- Sistemas MIMD y formas de acoplamiento multiprocesadoresDocument8 pagesSistemas MIMD y formas de acoplamiento multiprocesadoresHernan CastroPas encore d'évaluation
- Configuraciones de MCDDocument12 pagesConfiguraciones de MCDSergio RiveraPas encore d'évaluation
- Tipos de Arquitectura Del Procesador 1 Marzo 2021Document24 pagesTipos de Arquitectura Del Procesador 1 Marzo 2021Jose Luis ZabaletaPas encore d'évaluation
- Arquitectura MPPDocument2 pagesArquitectura MPPBereb RosqueroPas encore d'évaluation
- MultiprocesadorDocument19 pagesMultiprocesadorCHINO JIMENEZPas encore d'évaluation
- Aspectos Basicos de La Computacion Paralela y DistribuidaDocument10 pagesAspectos Basicos de La Computacion Paralela y Distribuidaluis hernandez100% (1)
- Arquitectura de ComputadorasDocument8 pagesArquitectura de ComputadorasSorel TorresPas encore d'évaluation
- 00881-Tema 3.3 Multiples ProcesadoresDocument45 pages00881-Tema 3.3 Multiples ProcesadoresAbraham SanchezPas encore d'évaluation
- Multiprocesadores SimétricosDocument9 pagesMultiprocesadores SimétricosRobin PereiraPas encore d'évaluation
- MemoriaDocument5 pagesMemoriaMaryi Becerra TorresPas encore d'évaluation
- Memoria Compartida DistribuidaDocument11 pagesMemoria Compartida DistribuidaRoger VaaPas encore d'évaluation
- Arquitecturas y Procesamiento ParaleloDocument17 pagesArquitecturas y Procesamiento ParaleloRaul L. Zamorano FerrerPas encore d'évaluation
- Arquitectura MIMDDocument6 pagesArquitectura MIMDpdelacruzrPas encore d'évaluation
- 53 Unidad6 Coherencia de CacheDocument12 pages53 Unidad6 Coherencia de CacheDoracelia Gazga LovePas encore d'évaluation
- Como Funciona El Procesamiento en ParaleloDocument4 pagesComo Funciona El Procesamiento en ParaleloFrancesco RuggieroPas encore d'évaluation
- SMP (Symmetric Multi-Processing Ó Multiproceso Simétrico)Document2 pagesSMP (Symmetric Multi-Processing Ó Multiproceso Simétrico)Markos MartinPas encore d'évaluation
- Arquitecturas Paralelas Existentes en El MercadoDocument4 pagesArquitecturas Paralelas Existentes en El MercadoEmma Collin100% (1)
- Procesamiento ParaleloDocument23 pagesProcesamiento ParaleloAlejandro Pérez García0% (1)
- Actividad 3 - Procesos y ProcesamientoDocument9 pagesActividad 3 - Procesos y ProcesamientoErik Ramírez MonteroPas encore d'évaluation
- Guía de Estudio - Arquitectura de Las ComputadorasDocument8 pagesGuía de Estudio - Arquitectura de Las ComputadorasSHAINA ALEXANDRA XOCHITIOTZI ROJASPas encore d'évaluation
- Trabajo de Investigación Unidad 4 Arquitectura Del ComputadorDocument6 pagesTrabajo de Investigación Unidad 4 Arquitectura Del ComputadorFrandersson BarretoPas encore d'évaluation
- Computación ParalelaDocument7 pagesComputación ParalelaLuis HermenegildoPas encore d'évaluation
- Sistemas de Memoria Compartida DistribuidaDocument15 pagesSistemas de Memoria Compartida DistribuidaJuan Carlos Gonzalez GutierrezPas encore d'évaluation
- Arquitectura MultiprocesamientoDocument10 pagesArquitectura MultiprocesamientoWiler Falcon CarbajalPas encore d'évaluation
- La Arquitectura SMPDocument5 pagesLa Arquitectura SMPKevin Hernandez RamosPas encore d'évaluation
- Arquitecturas Cisc, Risc o en ParaleloDocument12 pagesArquitecturas Cisc, Risc o en ParaleloArmand DarkPas encore d'évaluation
- MultiprocesamientoDocument5 pagesMultiprocesamientoEberth A. LeónPas encore d'évaluation
- Tendencias de Los Sistemas Operativos DistribuidosDocument7 pagesTendencias de Los Sistemas Operativos Distribuidosbaghead8Pas encore d'évaluation
- Modelos de Máquinas ParalelasDocument7 pagesModelos de Máquinas ParalelasPablo JonasPas encore d'évaluation
- MultiprocesadoresDocument17 pagesMultiprocesadoresmorris starPas encore d'évaluation
- Resumen MultiprocesadoresDocument6 pagesResumen MultiprocesadoresYohan MorelPas encore d'évaluation
- 03306-Tema 4. Organización ParalelaDocument8 pages03306-Tema 4. Organización Paralelapapatv100% (1)
- Unidad 4 Arqui de ComputadorasDocument11 pagesUnidad 4 Arqui de ComputadorasIrving CobainPas encore d'évaluation
- Sistemas MultiprocesamientoDocument9 pagesSistemas MultiprocesamientolalometallicaPas encore d'évaluation
- Programación de microcontroladores paso a paso: Ejemplos prácticos desarrollados en la nubeD'EverandProgramación de microcontroladores paso a paso: Ejemplos prácticos desarrollados en la nubePas encore d'évaluation
- UF0852 - Instalación y actualización de sistemas operativosD'EverandUF0852 - Instalación y actualización de sistemas operativosÉvaluation : 5 sur 5 étoiles5/5 (1)
- Programacion AsincronaDocument53 pagesProgramacion AsincronaCarlos EQPas encore d'évaluation
- Rúbrica T3 APLICAC Videojuegos Aplicaciones Móviles 2016 2Document10 pagesRúbrica T3 APLICAC Videojuegos Aplicaciones Móviles 2016 2Carlos EQPas encore d'évaluation
- Sesion 4-Geometría ComputacionalDocument9 pagesSesion 4-Geometría ComputacionalCarlos EQPas encore d'évaluation
- Bicicle TaDocument5 pagesBicicle TaCarlos EQPas encore d'évaluation
- Silabo 2014-I Informatica ADocument6 pagesSilabo 2014-I Informatica ACarlos EQPas encore d'évaluation
- Geometría Computacional-Sesion 2Document8 pagesGeometría Computacional-Sesion 2Carlos EQPas encore d'évaluation
- Lab 2 Especif Formal 2015 IiDocument3 pagesLab 2 Especif Formal 2015 IiCarlos EQPas encore d'évaluation
- Resume NDocument1 pageResume NCarlos EQPas encore d'évaluation
- Estado de Un Proceso01Document5 pagesEstado de Un Proceso01Carlos EQPas encore d'évaluation
- BdinfoalumDocument1 pageBdinfoalumCarlos EQPas encore d'évaluation
- Spring Framework - ArquitectureDocument2 pagesSpring Framework - ArquitectureCarlos EQPas encore d'évaluation
- Todo Excepto 4.1 y 4.2 S.ODocument24 pagesTodo Excepto 4.1 y 4.2 S.OCarlos EQPas encore d'évaluation
- Transform AdoresDocument4 pagesTransform AdoresgonzalochecalimaPas encore d'évaluation
- Configuración de Apache, PHP y MySQL para desarrollo localDocument114 pagesConfiguración de Apache, PHP y MySQL para desarrollo localJesus BolivarPas encore d'évaluation
- Carga Por Aula.Document9 pagesCarga Por Aula.Carlos EQPas encore d'évaluation
- 4lenguajes FormalesDocument6 pages4lenguajes FormalesKeven S. AltamiranoPas encore d'évaluation
- Silabo 2014-I Informatica ADocument6 pagesSilabo 2014-I Informatica ACarlos EQPas encore d'évaluation
- AnexoDocument1 pageAnexoAnonymous Z0enekPas encore d'évaluation
- 4modelos de Lenguajes de ProgramacionDocument6 pages4modelos de Lenguajes de ProgramacionCarlos EQPas encore d'évaluation
- Oracle Clase 1Document4 pagesOracle Clase 1Carlos EQPas encore d'évaluation
- Practicas TransformadoresDocument12 pagesPracticas TransformadoresJulio Pino MirandaPas encore d'évaluation
- Tru Ji 080215Document103 pagesTru Ji 080215Instituto de Investigación Académica: PraxisPas encore d'évaluation
- Sistemas InformaticosDocument3 pagesSistemas InformaticosCarlos EQPas encore d'évaluation
- Informatica y SociedadDocument5 pagesInformatica y SociedadCarlos EQPas encore d'évaluation
- Npros La Escuela DelDocument7 pagesNpros La Escuela DelCarlos EQPas encore d'évaluation
- Computacion GraficaDocument9 pagesComputacion GraficaCarlos EQPas encore d'évaluation
- Ex EmploDocument5 pagesEx EmploCarlos EQPas encore d'évaluation
- IntroducciónDocument6 pagesIntroducciónAarón Jesús RamosPas encore d'évaluation
- Organizacion de ArchivosDocument5 pagesOrganizacion de ArchivosCarlos EQPas encore d'évaluation
- IntroducciónDocument6 pagesIntroducciónAarón Jesús RamosPas encore d'évaluation
- Sistemas Operativos.Document6 pagesSistemas Operativos.Gabrielito AlejandroPas encore d'évaluation
- Qué son las siglas BIOS y otros conceptos básicos de computaciónDocument8 pagesQué son las siglas BIOS y otros conceptos básicos de computaciónAdministrador Leonardo GarciaPas encore d'évaluation
- Historia de Las Computadoras Trabajo PracticoDocument21 pagesHistoria de Las Computadoras Trabajo PracticoorianaantonelaPas encore d'évaluation
- Alfabetización Tecnológica VenezuelaDocument14 pagesAlfabetización Tecnológica VenezuelaAyoleida Lopez100% (2)
- 2.laboratorio John TejadaDocument20 pages2.laboratorio John TejadaJhonatan MartinezPas encore d'évaluation
- Sistemas Operativos - Introducción - UNSaDocument41 pagesSistemas Operativos - Introducción - UNSaOscar VargasPas encore d'évaluation
- Los Lenguajes de Programacion.Document8 pagesLos Lenguajes de Programacion.Alicia GarciaPas encore d'évaluation
- Unidad 1 - HardwareDocument9 pagesUnidad 1 - HardwareperuggininaiaraPas encore d'évaluation
- Programacion Con ScratchDocument216 pagesProgramacion Con ScratchVictor C. Ccari100% (1)
- Marketing para la inserción laboralDocument5 pagesMarketing para la inserción laboralJaimito Valdivia M'Pas encore d'évaluation
- La Programación en La Ingenieria CivilDocument18 pagesLa Programación en La Ingenieria CivilJose Armando Bautista AntonioPas encore d'évaluation
- Metrología - El Osciloscopio y Generador de FuncionesDocument12 pagesMetrología - El Osciloscopio y Generador de FuncionesPascual Vargas VelasquezPas encore d'évaluation
- FACTUSOL Primeros Pasos 2017Document17 pagesFACTUSOL Primeros Pasos 2017Jose Luis Garcia LopezPas encore d'évaluation
- IPN-ESIME Culhuacán Circuitos Digitales Comparador lógicoDocument8 pagesIPN-ESIME Culhuacán Circuitos Digitales Comparador lógicoAldo David Bonilla SanchezPas encore d'évaluation
- EstilosDocument4 pagesEstilosGonzalo GVPas encore d'évaluation
- Partes de la computadora y su historiaDocument28 pagesPartes de la computadora y su historiaGaby GonzalezPas encore d'évaluation
- SurvCE 1 62 Manual SpanishDocument267 pagesSurvCE 1 62 Manual SpanishCarlos Jhimmi Anze BenitesPas encore d'évaluation
- Sistemas Operativos Por LotesDocument9 pagesSistemas Operativos Por LotesMaicol RaizorPas encore d'évaluation
- QUE ES EL CNC Manual Contruccion CaseraDocument24 pagesQUE ES EL CNC Manual Contruccion CaseraAlex MartinezPas encore d'évaluation
- Proceso de Carga en La Memoria RAMDocument4 pagesProceso de Carga en La Memoria RAMJezuzz Araujoxx ヅPas encore d'évaluation
- ProyectoDocument21 pagesProyectoBrenick RamosPas encore d'évaluation
- Tabla de Las Generaciones de La Educación A Distancia. InstrucciónDocument5 pagesTabla de Las Generaciones de La Educación A Distancia. Instrucciónclaudia veraPas encore d'évaluation
- Capitulo-1.Ingeniería de Software Un Enfoque Desde La Guía SwebokDocument29 pagesCapitulo-1.Ingeniería de Software Un Enfoque Desde La Guía SwebokEver Alfonzo FrancoPas encore d'évaluation
- Estructuras de Datos Con C - TenenbaumLangsamAugensteinDocument240 pagesEstructuras de Datos Con C - TenenbaumLangsamAugensteinDaniel LezcanoPas encore d'évaluation
- Computación e InformáticaDocument17 pagesComputación e InformáticaJulio Cesar KiraPas encore d'évaluation
- Generaciones Del SoftwareDocument9 pagesGeneraciones Del SoftwareAlben Baphomet Pirobus0% (1)
- 1.1. Competencias DigitalesDocument25 pages1.1. Competencias Digitalesedson marin chamanPas encore d'évaluation
- Sistema de Comunicación y Sensorial de Un RobotDocument19 pagesSistema de Comunicación y Sensorial de Un Roboteverret08100% (1)
- 4.2.3.normatividad de SeguridadDocument4 pages4.2.3.normatividad de SeguridadJoshua Velasquez VelasquezPas encore d'évaluation
- Control y Monitoreo de Sesiones de Internet Mediante Un Servidor SQUID en LinuxDocument72 pagesControl y Monitoreo de Sesiones de Internet Mediante Un Servidor SQUID en LinuxINGSAMC7Pas encore d'évaluation