Vous aimerez peut-être aussi
- QNAPDocument112 pagesQNAPshaggerukPas encore d'évaluation
- CWM Forms PDFDocument8 pagesCWM Forms PDFreemadeponPas encore d'évaluation
- Cap StudyguideDocument145 pagesCap StudyguidebugyourselfPas encore d'évaluation
- The Waking of Willowby HallDocument13 pagesThe Waking of Willowby HallNatt SkapaPas encore d'évaluation
- Design of Tanks For The Storage of Oil and WaterDocument29 pagesDesign of Tanks For The Storage of Oil and Waterjayaraman3Pas encore d'évaluation
- Homework 4 Solution GuidelinesDocument12 pagesHomework 4 Solution GuidelinesSurya AhujaPas encore d'évaluation
- Integrated Approach To Web Performance Testing - A Practitioner's Guide (2006) PDFDocument387 pagesIntegrated Approach To Web Performance Testing - A Practitioner's Guide (2006) PDFshanthan117100% (1)
- Philippine ArenaDocument7 pagesPhilippine ArenaPeachieAndersonPas encore d'évaluation
- Transformation TruthsDocument34 pagesTransformation TruthsbugyourselfPas encore d'évaluation
- Sample Lawson EssayDocument3 pagesSample Lawson EssaybugyourselfPas encore d'évaluation
- M116C 1 EE116C-Midterm2-w15 SolutionDocument8 pagesM116C 1 EE116C-Midterm2-w15 Solutiontinhtrilac100% (1)
- CENG400-Final-Fall 2015Document10 pagesCENG400-Final-Fall 2015Mohamad IssaPas encore d'évaluation
- Indian Institute of Technology, Kharagpur: Mid-Spring Semester 2021-22Document4 pagesIndian Institute of Technology, Kharagpur: Mid-Spring Semester 2021-22Utkarsh PatelPas encore d'évaluation
- Question 1 (50 Points) PipeliningDocument3 pagesQuestion 1 (50 Points) PipeliningMuhammad Zahid iqbalPas encore d'évaluation
- Instructions: Csce 212: Final Exam Spring 2009Document5 pagesInstructions: Csce 212: Final Exam Spring 2009NapsterPas encore d'évaluation
- Sample Problems Pipe&MemoryDocument57 pagesSample Problems Pipe&Memoryacc1444Pas encore d'évaluation
- CSE 332 L 14 Short & 15 - 24th & 26th Sep 2020Document28 pagesCSE 332 L 14 Short & 15 - 24th & 26th Sep 2020Nz SaadPas encore d'évaluation
- CENG3420 Homework 3: SolutionsDocument5 pagesCENG3420 Homework 3: SolutionsJosue David Hernandez ViloriaPas encore d'évaluation
- Computer Architecture hw6Document3 pagesComputer Architecture hw6Jason WheelerPas encore d'évaluation
- hw5 SolnDocument4 pageshw5 SolnThanh TrúcPas encore d'évaluation
- Data HazardsDocument15 pagesData HazardsPetreMaziluPas encore d'évaluation
- Computer Architecture - 09 - Review For MidtermDocument13 pagesComputer Architecture - 09 - Review For Midtermdlwodbs031Pas encore d'évaluation
- SuperpipeliningDocument7 pagesSuperpipeliningBravoYusufPas encore d'évaluation
- COE301 Final Solution 162Document10 pagesCOE301 Final Solution 162Karim IbrahimPas encore d'évaluation
- 2009 CO Midterm - SolDocument11 pages2009 CO Midterm - Solthanhthien07ecePas encore d'évaluation
- 2 UartDocument6 pages2 UartbtssnaPas encore d'évaluation
- Computer Arch TestDocument8 pagesComputer Arch TestCricket Live StreamingPas encore d'évaluation
- Final Spring2011Document6 pagesFinal Spring2011edePas encore d'évaluation
- CompreDocument3 pagesCompreUdai ValluruPas encore d'évaluation
- PARALLELISM VIA INSTRUCTIONS: Pipelining Exploits The Potential Parallelism Among Instructions. This Parallelism IsDocument2 pagesPARALLELISM VIA INSTRUCTIONS: Pipelining Exploits The Potential Parallelism Among Instructions. This Parallelism IsBerkay ÖzerbayPas encore d'évaluation
- Tuesday, October 31, 2023 10:53 PM: Discuss, The Schemes For Dealing With The Pipeline Stalls Caused by Branch HazardsDocument7 pagesTuesday, October 31, 2023 10:53 PM: Discuss, The Schemes For Dealing With The Pipeline Stalls Caused by Branch Hazardskrahul74714Pas encore d'évaluation
- CS G524 2006 C 2011 1Document6 pagesCS G524 2006 C 2011 1Aman AgnihotriPas encore d'évaluation
- Advanced Computer Network Assignment HelpDocument11 pagesAdvanced Computer Network Assignment HelpComputer Network Assignment HelpPas encore d'évaluation
- T5 Fall 2014 SSDocument5 pagesT5 Fall 2014 SSRay TanPas encore d'évaluation
- Int and Float and Print FormatingDocument6 pagesInt and Float and Print FormatingObi InwelegbuPas encore d'évaluation
- Practice Final SolnDocument17 pagesPractice Final SolnJimmie J MshumbusiPas encore d'évaluation
- CMPEN 335 - Computer Organization and Design, Lab 3: 1. PipeliningDocument5 pagesCMPEN 335 - Computer Organization and Design, Lab 3: 1. PipeliningRoberta AndreeaPas encore d'évaluation
- CS3350B Computer Architecture: Lecture 6.3: Instructional Level Parallelism: Advanced TechniquesDocument24 pagesCS3350B Computer Architecture: Lecture 6.3: Instructional Level Parallelism: Advanced TechniquesAsHraf G. ElrawEiPas encore d'évaluation
- 2023 Contoh Soalan Computer Architecture and OrganizationDocument7 pages2023 Contoh Soalan Computer Architecture and OrganizationHarith HiewPas encore d'évaluation
- Computer Science Homework WorksheetDocument5 pagesComputer Science Homework WorksheetEe JianPas encore d'évaluation
- Problem Set 4 SolDocument14 pagesProblem Set 4 SolbsudheertecPas encore d'évaluation
- Ca Final Fa19 BCS 087Document6 pagesCa Final Fa19 BCS 087ahmad razaPas encore d'évaluation
- Project-B-Report v1Document16 pagesProject-B-Report v1api-482323647Pas encore d'évaluation
- 181 CSE313 FinalDocument3 pages181 CSE313 FinalSabbir HossainPas encore d'évaluation
- CS1352 May07Document19 pagesCS1352 May07sridharanc23Pas encore d'évaluation
- Lab ManualDocument82 pagesLab ManualxyzzyzPas encore d'évaluation
- Homework Computer ArchitectureDocument13 pagesHomework Computer ArchitectureMumtahina ParvinPas encore d'évaluation
- COL216 Assignment 4: 1 Problem StatementDocument4 pagesCOL216 Assignment 4: 1 Problem StatementAniket MishraPas encore d'évaluation
- CS 352H: Computer Systems Architecture: Topic 10: Instruction Level Parallelism (ILP) October 6 - 8, 2009Document25 pagesCS 352H: Computer Systems Architecture: Topic 10: Instruction Level Parallelism (ILP) October 6 - 8, 2009Sudip Kumar DeyPas encore d'évaluation
- Lecture 11 COMP2611 Processor Part3Document41 pagesLecture 11 COMP2611 Processor Part3jnfzPas encore d'évaluation
- 78941cdb0e9833460d05ad79c59f6c0c_ed750806804ba7eb09df7f9f332d16c7Document5 pages78941cdb0e9833460d05ad79c59f6c0c_ed750806804ba7eb09df7f9f332d16c7Priyank SharmaPas encore d'évaluation
- Quiz For Chapter 2 With SolutionsDocument7 pagesQuiz For Chapter 2 With Solutionsnvdangdt1k52bk03100% (1)
- Sheet7 SolutionDocument11 pagesSheet7 SolutionMd. Imran AhmedPas encore d'évaluation
- Computer Organization: An Introduction To RISC Hardware: 6.1 An Overview of PipeliningDocument12 pagesComputer Organization: An Introduction To RISC Hardware: 6.1 An Overview of PipeliningAmrendra Kumar MishraPas encore d'évaluation
- 1.estimate The Pararasitics of A Net Whose Fanout Is 7.: Page Sta Evaluation Test 1Document11 pages1.estimate The Pararasitics of A Net Whose Fanout Is 7.: Page Sta Evaluation Test 1Sujit Kumar100% (1)
- cs146 Fall2017 Midterm1xxDocument12 pagescs146 Fall2017 Midterm1xxgrizzyleoPas encore d'évaluation
- EE352 HW3 Nazarian Spring10Document8 pagesEE352 HW3 Nazarian Spring10skdejhloiewPas encore d'évaluation
- EEM 486 Computer Architecture Homework VI 1. Consider The Following Code SequenceDocument2 pagesEEM 486 Computer Architecture Homework VI 1. Consider The Following Code SequenceHalim KorogluPas encore d'évaluation
- Mit VliwDocument30 pagesMit VliwjahPas encore d'évaluation
- Cse590490 HW2Document5 pagesCse590490 HW2Adip ChyPas encore d'évaluation
- Instruction Level Parallelism: PipeliningDocument6 pagesInstruction Level Parallelism: PipeliningkbkkrPas encore d'évaluation
- BFE Final Organization Fall 2014 AnswerDocument8 pagesBFE Final Organization Fall 2014 AnswerArpan DesaiPas encore d'évaluation
- CPE 185 TestDocument16 pagesCPE 185 TestPaul DyePas encore d'évaluation
- UPLOAD - Simile NavasDocument19 pagesUPLOAD - Simile NavasAnonymous VASS3z0wTHPas encore d'évaluation
- N098 - MM - Exp 10Document5 pagesN098 - MM - Exp 10Vedashree ShetyePas encore d'évaluation
- ELEN 468 Advanced Logic Design: MIPS MicroprocessorDocument19 pagesELEN 468 Advanced Logic Design: MIPS MicroprocessorMahendranath CholletiPas encore d'évaluation
- DSP Processors: We Have Seen That The Multiply and Accumulate (MAC) Operation Is Very Prevalent in DSP ComputationDocument9 pagesDSP Processors: We Have Seen That The Multiply and Accumulate (MAC) Operation Is Very Prevalent in DSP ComputationertwertPas encore d'évaluation
- HSC Area of StudyDocument12 pagesHSC Area of StudybugyourselfPas encore d'évaluation
- The Holy Bible - Noah Webster TranslationDocument1 676 pagesThe Holy Bible - Noah Webster TranslationbugyourselfPas encore d'évaluation
- Computer Networks 2 10CS64 Unit 2 NotesDocument29 pagesComputer Networks 2 10CS64 Unit 2 NotesbugyourselfPas encore d'évaluation
- Philips Elite Agro 315W T12Document3 pagesPhilips Elite Agro 315W T12bugyourselfPas encore d'évaluation
- 8.1.4.8 Lab - Identifying IPv4 AddressesDocument4 pages8.1.4.8 Lab - Identifying IPv4 AddressesdotcomblaPas encore d'évaluation
- Basic Math 1 This Is A Real Number 1+1 2Document1 pageBasic Math 1 This Is A Real Number 1+1 2bugyourselfPas encore d'évaluation
- (Name of NEA Installation) (Date)Document1 page(Name of NEA Installation) (Date)bugyourselfPas encore d'évaluation
- (Please State Clearly The Action Recommended) Insert Text HereDocument1 page(Please State Clearly The Action Recommended) Insert Text HerebugyourselfPas encore d'évaluation
- Finesst WayDocument1 pageFinesst WaybugyourselfPas encore d'évaluation
- Eat For LifeDocument1 pageEat For LifebugyourselfPas encore d'évaluation
- LNP ProjectDocument12 pagesLNP ProjectbugyourselfPas encore d'évaluation
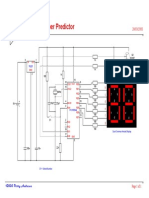
- Lottery Number Predictor: IN OUT GNDDocument1 pageLottery Number Predictor: IN OUT GNDbugyourselfPas encore d'évaluation
- Samsung Magician Manual.v.4.1 (En)Document30 pagesSamsung Magician Manual.v.4.1 (En)bugyourselfPas encore d'évaluation
- Syllabus 3301 Fall 2014Document3 pagesSyllabus 3301 Fall 2014bugyourselfPas encore d'évaluation
- 650017Document85 pages650017bugyourselfPas encore d'évaluation
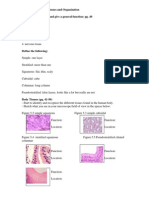
- Human Biology Laboratory 4: Body Tissues and Organization List The 4 Tissue Types and Give A General Function: Pg. 40Document4 pagesHuman Biology Laboratory 4: Body Tissues and Organization List The 4 Tissue Types and Give A General Function: Pg. 40bugyourselfPas encore d'évaluation
- Export Okular Annotations To PDFDocument2 pagesExport Okular Annotations To PDFDanPas encore d'évaluation
- Oral Presentation Guidelines: 1. Audio/Visual & Equipment AvailableDocument2 pagesOral Presentation Guidelines: 1. Audio/Visual & Equipment AvailableNanda SafiraPas encore d'évaluation
- JahangirDocument4 pagesJahangirHimtet HuangzPas encore d'évaluation
- Reinforcement DetailingDocument23 pagesReinforcement Detailingyash khandol100% (1)
- Masonry Information: Masonry Cement: Product Data SheetDocument4 pagesMasonry Information: Masonry Cement: Product Data SheetarylananylaPas encore d'évaluation
- ThinkPad E470 SpecsDocument1 pageThinkPad E470 Specsmuhammad tirta agustaPas encore d'évaluation
- KasthamandapDocument2 pagesKasthamandapHarshita SinghPas encore d'évaluation
- CCNA 2 FinalDocument38 pagesCCNA 2 FinalTuấnPas encore d'évaluation
- Foundation & Column DesignDocument6 pagesFoundation & Column DesignAlbert LuckyPas encore d'évaluation
- Refsheet My Thuan II Bridge ENDocument1 pageRefsheet My Thuan II Bridge ENIndra Nath MishraPas encore d'évaluation
- USB in A NutShellDocument35 pagesUSB in A NutShellSandro Jairzinho Carrascal Ayora100% (1)
- Practical IGCSE Soils Organic MatterDocument5 pagesPractical IGCSE Soils Organic MatterMO62Pas encore d'évaluation
- SOAP Web SecurityDocument0 pageSOAP Web SecurityRei ChelPas encore d'évaluation
- AC O& M City Mall Version 1.0Document12 pagesAC O& M City Mall Version 1.0yewminyun6098Pas encore d'évaluation
- Final PresentationDocument34 pagesFinal PresentationRaj SandhuPas encore d'évaluation
- Gcode AsbakDocument2 356 pagesGcode AsbakArif RahmanPas encore d'évaluation
- MCD Officials Delhi (Mail IDs)Document11 pagesMCD Officials Delhi (Mail IDs)mydearg50% (2)
- Open Channel APHDocument2 pagesOpen Channel APHponmanikandan1Pas encore d'évaluation
- Aspa-ProdDocument78 pagesAspa-ProdKrm ChariPas encore d'évaluation
- LMUKA11510 Reliability EngineerDocument4 pagesLMUKA11510 Reliability EngineerInaya GeorgePas encore d'évaluation
- Daitsu APD12 New ManualDocument26 pagesDaitsu APD12 New ManualGeorge ShanidzePas encore d'évaluation
- Specsheet Etile19m-Fw I5 CpuDocument2 pagesSpecsheet Etile19m-Fw I5 CpuMarisagarcia2014Pas encore d'évaluation
- PDS Sikament®-163Document3 pagesPDS Sikament®-163Anonymous e2wolbeFsPas encore d'évaluation
- Church of Saint Lazarus, LarnacaDocument3 pagesChurch of Saint Lazarus, LarnacaTimyPas encore d'évaluation