Vous aimerez peut-être aussi
- Practical Design of Experiments: DoE Made EasyD'EverandPractical Design of Experiments: DoE Made EasyÉvaluation : 4.5 sur 5 étoiles4.5/5 (7)
- Nonlinear Optimization RoutinesDocument1 pageNonlinear Optimization RoutinesalmerPas encore d'évaluation
- Prog Assign 3 Explained PDFDocument2 pagesProg Assign 3 Explained PDFMoazzam HussainPas encore d'évaluation
- Computer & ITDocument148 pagesComputer & ITMohit GuptaPas encore d'évaluation
- CSEGATEDocument138 pagesCSEGATESaritha CeelaPas encore d'évaluation
- Data Mining PrimerDocument5 pagesData Mining PrimerJoJo BristolPas encore d'évaluation
- Assignment #5: Sorting Lab: Due: Mon, Feb 25 2:15pmDocument5 pagesAssignment #5: Sorting Lab: Due: Mon, Feb 25 2:15pmrahulmnnit_csPas encore d'évaluation
- Ch3 - Structering ML ProjectDocument36 pagesCh3 - Structering ML ProjectamalPas encore d'évaluation
- Introduction-Algorithm Definition Notion of An AlgorithmDocument23 pagesIntroduction-Algorithm Definition Notion of An Algorithmdhosheka123Pas encore d'évaluation
- Chapter 2 - Asymptotic Notation (Notes)Document51 pagesChapter 2 - Asymptotic Notation (Notes)Ren ZxPas encore d'évaluation
- Algorithm Analysis and DesignDocument83 pagesAlgorithm Analysis and DesignkalaraijuPas encore d'évaluation
- F20BC - CW - 2020 - Biologically InspiredDocument6 pagesF20BC - CW - 2020 - Biologically InspiredNouman RasheedPas encore d'évaluation
- Laboratory Practice, Testing, and Reporting: Time-Honored Fundamentals for the SciencesD'EverandLaboratory Practice, Testing, and Reporting: Time-Honored Fundamentals for the SciencesPas encore d'évaluation
- ML 19.03 SidenotesDocument30 pagesML 19.03 SidenotesasmaPas encore d'évaluation
- CSEGATEDocument133 pagesCSEGATEDhairya GopalPas encore d'évaluation
- Time and Space Analysis of AlgorithmsDocument5 pagesTime and Space Analysis of AlgorithmsAbhishek MitraPas encore d'évaluation
- Time: 3hours Max - Marks:70 Part-A Is Compulsory Answer One Question From Each Unit of Part-BDocument16 pagesTime: 3hours Max - Marks:70 Part-A Is Compulsory Answer One Question From Each Unit of Part-BRamya PatibandlaPas encore d'évaluation
- Chapter 1Document18 pagesChapter 1DesyilalPas encore d'évaluation
- Benchmark Programs For CPUDocument5 pagesBenchmark Programs For CPUmicutuzPas encore d'évaluation
- Introductory ExampleDocument11 pagesIntroductory ExampleChristianAslanPas encore d'évaluation
- UNIT 4 SeminarDocument10 pagesUNIT 4 SeminarPradeep Chaudhari50% (2)
- Department of Computing Technologies Software Testing and ReliabilityDocument6 pagesDepartment of Computing Technologies Software Testing and ReliabilitySyed EmadPas encore d'évaluation
- DS HandoutDocument110 pagesDS HandoutRewina zerouPas encore d'évaluation
- Analysis and Design of AlgorithmsDocument75 pagesAnalysis and Design of AlgorithmsSiva RajeshPas encore d'évaluation
- Introduction To Algorithms: Unit 1Document42 pagesIntroduction To Algorithms: Unit 1rushanandPas encore d'évaluation
- Introduction To Data Structures and Algorithms AnalysisDocument16 pagesIntroduction To Data Structures and Algorithms AnalysisYihune NegessePas encore d'évaluation
- Complexity Analysis IntroductionDocument3 pagesComplexity Analysis Introductionmadhura480Pas encore d'évaluation
- 1.1 Concept of AlgorithmDocument46 pages1.1 Concept of Algorithmrajat322Pas encore d'évaluation
- Chapter 1Document16 pagesChapter 1hiruttesfay67Pas encore d'évaluation
- Data Structure and Algorithm Chapter 1 - 2Document16 pagesData Structure and Algorithm Chapter 1 - 2eliasferhan2333Pas encore d'évaluation
- DSA NotesDocument87 pagesDSA NotesAtefrachew SeyfuPas encore d'évaluation
- Metrices of The ModelDocument9 pagesMetrices of The ModelNarmathaPas encore d'évaluation
- Chapter 1 - 3Document30 pagesChapter 1 - 3Nuredin AbdumalikPas encore d'évaluation
- 4 DOE Elements of SuccessDocument2 pages4 DOE Elements of SuccesscvenkatasunilPas encore d'évaluation
- Data Structure and AlgoritmsDocument113 pagesData Structure and AlgoritmsAbdissa Abera BachaPas encore d'évaluation
- F1 Score Vs ROC AUC Vs Accuracy Vs PR AUC Which Evaluation Metric Should You Choose - Neptune - AiDocument1 pageF1 Score Vs ROC AUC Vs Accuracy Vs PR AUC Which Evaluation Metric Should You Choose - Neptune - Aicool_spPas encore d'évaluation
- R19 It Iii Year 1 Semester Design and Analysis of Algorithms Unit 1Document39 pagesR19 It Iii Year 1 Semester Design and Analysis of Algorithms Unit 1KaarletPas encore d'évaluation
- Data Structure and AlgoritmsDocument86 pagesData Structure and AlgoritmsasratPas encore d'évaluation
- Roshan AssDocument10 pagesRoshan AssBadavath JeethendraPas encore d'évaluation
- Rajan - Gupta FileDocument5 pagesRajan - Gupta FileRahul GuptaPas encore d'évaluation
- Concept of AlgorithmDocument40 pagesConcept of AlgorithmHari HaraPas encore d'évaluation
- Hands On Machine Learning 3 EditionDocument31 pagesHands On Machine Learning 3 EditionsaharabdoumaPas encore d'évaluation
- Data Structure and AlgoritmsDocument87 pagesData Structure and Algoritmsaklilu YebuzeyePas encore d'évaluation
- Data Structure and AlgoritmsDocument16 pagesData Structure and AlgoritmsMikiyas GetasewPas encore d'évaluation
- IndustryalDocument187 pagesIndustryalMikiyas GetasewPas encore d'évaluation
- A Guide To Singular Value Decomposition For Collaborative FilteringDocument14 pagesA Guide To Singular Value Decomposition For Collaborative FilteringHoàng Công AnhPas encore d'évaluation
- Analysis, Design and Algorithsms (ADA)Document33 pagesAnalysis, Design and Algorithsms (ADA)Caro JudePas encore d'évaluation
- Algorithmic Thinking, Reasoning Flowcharts, Pseudo-Codes. (Lecture-1)Document53 pagesAlgorithmic Thinking, Reasoning Flowcharts, Pseudo-Codes. (Lecture-1)Mubariz Mirzayev100% (1)
- Assessing and Improving Prediction and Classification: Theory and Algorithms in C++D'EverandAssessing and Improving Prediction and Classification: Theory and Algorithms in C++Pas encore d'évaluation
- Data Science Interview Questions (#Day11) PDFDocument11 pagesData Science Interview Questions (#Day11) PDFSahil Goutham100% (1)
- Comparison and SelectionDocument10 pagesComparison and SelectioncruzreyeslauraPas encore d'évaluation
- An Easy To Use Trajectory Optimisation Tool For Launcher DesignDocument8 pagesAn Easy To Use Trajectory Optimisation Tool For Launcher Designperrot louisPas encore d'évaluation
- ANSYS Tutorial Design OptimizationDocument9 pagesANSYS Tutorial Design OptimizationSimulation CAE100% (4)
- Complexity Analysis of Algorithms (Greek For Greek)Document5 pagesComplexity Analysis of Algorithms (Greek For Greek)Nguyệt NguyệtPas encore d'évaluation
- Introduction To Algorithms Md. Asif Bin KhaledDocument26 pagesIntroduction To Algorithms Md. Asif Bin KhaledSharmin Islam ShroddhaPas encore d'évaluation
- Unit: I Fundamentals of Algorithms The Analysis of AlgorithmsDocument12 pagesUnit: I Fundamentals of Algorithms The Analysis of AlgorithmsPrakash SubramanianPas encore d'évaluation
- A Model For Spectra-Based Software DiagnosisDocument37 pagesA Model For Spectra-Based Software DiagnosisInformatika Universitas MalikussalehPas encore d'évaluation
- A Baseline Algorithm ForDocument11 pagesA Baseline Algorithm ForatulnandwalPas encore d'évaluation
- Details of ELDT EDCDocument1 pageDetails of ELDT EDCvasdevharishPas encore d'évaluation
- Chapter 3 OFDM Transmission Over Gaussian Channel - ModifyDocument19 pagesChapter 3 OFDM Transmission Over Gaussian Channel - ModifyvasdevharishPas encore d'évaluation
- TPR GraphDocument5 pagesTPR GraphvasdevharishPas encore d'évaluation
- Chapter 3 OFDM Transmission Over Gaussian Channel - ModifyDocument19 pagesChapter 3 OFDM Transmission Over Gaussian Channel - ModifyvasdevharishPas encore d'évaluation
- Mid Semester Examination - I: Subject Code:-CS-304Document1 pageMid Semester Examination - I: Subject Code:-CS-304vasdevharishPas encore d'évaluation
- User ScriptDocument1 pageUser ScriptvasdevharishPas encore d'évaluation
- Documents MSDSVendors 2014 October 21-08-54!52!236 AMDocument1 pageDocuments MSDSVendors 2014 October 21-08-54!52!236 AMvasdevharishPas encore d'évaluation
- FactoryflowDocument54 pagesFactoryflowh_eijy2743Pas encore d'évaluation
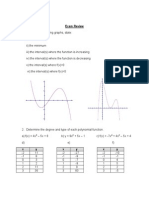
- Exam ReviewDocument8 pagesExam ReviewvasdevharishPas encore d'évaluation
- What Is EvolutionDocument3 pagesWhat Is EvolutionvasdevharishPas encore d'évaluation
- Hysys ManualDocument26 pagesHysys ManualvasdevharishPas encore d'évaluation
- Volvo - Value Chain AnalysisDocument25 pagesVolvo - Value Chain Analysisvasdevharish100% (2)
- Insurance HelpDocument7 pagesInsurance HelpvasdevharishPas encore d'évaluation
- CMake ListsDocument1 pageCMake ListsvasdevharishPas encore d'évaluation
- Gifts From AfarDocument4 pagesGifts From AfarvasdevharishPas encore d'évaluation
- Kid Kustomers by Eric SchlosserDocument3 pagesKid Kustomers by Eric Schlosservasdevharish100% (1)
- Learning (First Job) Reading WorksheetDocument1 pageLearning (First Job) Reading WorksheetvasdevharishPas encore d'évaluation
- Review The Black Death and The Transformation of The WestDocument4 pagesReview The Black Death and The Transformation of The WestvasdevharishPas encore d'évaluation
- New Microsoft PoaaadwerPoint PresentationDocument1 pageNew Microsoft PoaaadwerPoint PresentationvasdevharishPas encore d'évaluation
- ATMOSPHEREDocument3 pagesATMOSPHEREvasdevharishPas encore d'évaluation
- Runge-Kutta 4 Order Method: Example: K DT DDocument10 pagesRunge-Kutta 4 Order Method: Example: K DT DJhun Dhon Mari Abihay100% (1)
- Assignment 1Document4 pagesAssignment 1indgokPas encore d'évaluation
- Cem PDFDocument4 pagesCem PDFJainam JoshiPas encore d'évaluation
- Haerdle W., Kleinow T., Stahl G. - Applied Quantitative Finance-Springer (2002)Document423 pagesHaerdle W., Kleinow T., Stahl G. - Applied Quantitative Finance-Springer (2002)G HeavyPas encore d'évaluation
- @face X 0, Ux 0 @face X Width, " Linear Constraint Equation" @face Y 0, Uy 0 @face Y Width, Uy Is Specified @face Z 0, Uz 0 @face Z Width, " Linear Constraint Equation"Document3 pages@face X 0, Ux 0 @face X Width, " Linear Constraint Equation" @face Y 0, Uy 0 @face Y Width, Uy Is Specified @face Z 0, Uz 0 @face Z Width, " Linear Constraint Equation"VijaybalajiPas encore d'évaluation
- Information Technology Practice QuestionsDocument13 pagesInformation Technology Practice QuestionsChelsea Lawrence100% (1)
- Dynamic Programming Exercises SolutionDocument12 pagesDynamic Programming Exercises Solutionsolomon100% (1)
- BCA First Year SubjectsDocument4 pagesBCA First Year SubjectsKamatchi KartheebanPas encore d'évaluation
- Hamming CodeDocument11 pagesHamming CodeShoubhik Pande75% (4)
- SolidWorks Flow Simulation Solution Adaptive Mesh RefinementDocument5 pagesSolidWorks Flow Simulation Solution Adaptive Mesh RefinementSameeraLakmalWickramathilakaPas encore d'évaluation
- Homework 1 Answers - StudentDocument2 pagesHomework 1 Answers - StudentBeryl ChanPas encore d'évaluation
- C&NS Lab Manual 2021Document64 pagesC&NS Lab Manual 2021nawal 109Pas encore d'évaluation
- M1-3 - Operations On Signals, Transformation of Independent Variable, SamplingDocument16 pagesM1-3 - Operations On Signals, Transformation of Independent Variable, SamplingMANSI BHARDWAJPas encore d'évaluation
- Indian Forest Service (IFoS-IFS) Mains Exam Maths Optional Linear Algebra Previous Year Questions (PYQs) From 2020 To 2009Document9 pagesIndian Forest Service (IFoS-IFS) Mains Exam Maths Optional Linear Algebra Previous Year Questions (PYQs) From 2020 To 2009hshejejPas encore d'évaluation
- Discrete-Time Fourier Methods: M. J. Roberts All Rights Reserved. Edited by Dr. Robert AklDocument72 pagesDiscrete-Time Fourier Methods: M. J. Roberts All Rights Reserved. Edited by Dr. Robert AklvenkatPas encore d'évaluation
- RatioandRegressionMethodofEstimation Lecture7 10Document30 pagesRatioandRegressionMethodofEstimation Lecture7 10mrpakistan444Pas encore d'évaluation
- Extreme Point Method For Linear Programming PDFDocument10 pagesExtreme Point Method For Linear Programming PDFHassan NathaniPas encore d'évaluation
- Close & Open Loop SystemDocument6 pagesClose & Open Loop SystemAdonis NicolasPas encore d'évaluation
- Data Structure SolutionDocument148 pagesData Structure SolutionMohit TiwariPas encore d'évaluation
- B TreeDocument3 pagesB TreeRitwik KumarPas encore d'évaluation
- Turing Machines: Introductory ConceptsDocument2 pagesTuring Machines: Introductory ConceptsAniqua AliPas encore d'évaluation
- Activity Guide - Zombie Prediction: Our DataDocument3 pagesActivity Guide - Zombie Prediction: Our DataAhmed OsmanPas encore d'évaluation
- Skogestad Simple Pid Tuning RulesDocument27 pagesSkogestad Simple Pid Tuning Rulesstathiss11Pas encore d'évaluation
- Jasim AltafDocument53 pagesJasim AltafJasim AltafPas encore d'évaluation
- Image ClassificationDocument3 pagesImage ClassificationSameer AbidiPas encore d'évaluation
- KKJJJJJJJBDocument5 pagesKKJJJJJJJBVigneshRamakrishnanPas encore d'évaluation
- MAS 766: Linear Models: Regression Spring 2020 Team Assignment #3 Due: Wed. Apr 8. 2020Document7 pagesMAS 766: Linear Models: Regression Spring 2020 Team Assignment #3 Due: Wed. Apr 8. 2020Aashna MehtaPas encore d'évaluation
- Cryptography in E-CommerceDocument15 pagesCryptography in E-CommerceMugluuPas encore d'évaluation
- Cryptography Fundamentals Lab Assignment - 5: CodeDocument8 pagesCryptography Fundamentals Lab Assignment - 5: CodeSurya VjkumarPas encore d'évaluation
- Josue Velazquez WP 451Document45 pagesJosue Velazquez WP 451Adrian SerranoPas encore d'évaluation