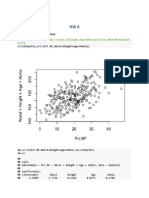
Vous aimerez peut-être aussi
- Liao HW 3: GeneexpressionDocument11 pagesLiao HW 3: GeneexpressioncincinmindyPas encore d'évaluation
- 1 Descriptive Stats RDocument7 pages1 Descriptive Stats RAnonymous d70CGoPas encore d'évaluation
- Topic 1 Numerical MeasureDocument11 pagesTopic 1 Numerical MeasureNedal AbuzwidaPas encore d'évaluation
- Data analysis guideDocument8 pagesData analysis guidepachapPas encore d'évaluation
- Basic Statistics Concepts for Environmental Data AnalysisDocument7 pagesBasic Statistics Concepts for Environmental Data AnalysisAsini Gavinya SirinimalPas encore d'évaluation
- HW 3Document17 pagesHW 3a.galvin13247Pas encore d'évaluation
- Optimal Nutrition Through Linear ProgrammingDocument11 pagesOptimal Nutrition Through Linear ProgrammingJose RacinePas encore d'évaluation
- Modeling Ordinal Categorical Data (Agresti)Document71 pagesModeling Ordinal Categorical Data (Agresti)Davide RadicePas encore d'évaluation
- Measures of VariabilityDocument22 pagesMeasures of VariabilityShex ShamalPas encore d'évaluation
- Bayesian Estimation Supersedes the t-TestDocument15 pagesBayesian Estimation Supersedes the t-Testfcc3Pas encore d'évaluation
- Part C: Analysing A Quantitative DatasetDocument3 pagesPart C: Analysing A Quantitative DatasetKashémPas encore d'évaluation
- Beyond Binary Outcomes: PROC LOGISTIC To Model Ordinal and Nominal Dependent VariablesDocument8 pagesBeyond Binary Outcomes: PROC LOGISTIC To Model Ordinal and Nominal Dependent VariablesEric 'robo' BaafiPas encore d'évaluation
- Multiple Logistic RegressionDocument4 pagesMultiple Logistic RegressionAddhyan PandeyPas encore d'évaluation
- ANOVA Guide for Comparing Means of 3+ SamplesDocument7 pagesANOVA Guide for Comparing Means of 3+ Samplespaok44Pas encore d'évaluation
- IT0089 TB391 Decision Tree RABEDocument6 pagesIT0089 TB391 Decision Tree RABEKim VincerePas encore d'évaluation
- Stat 231 A1Document11 pagesStat 231 A1nathanPas encore d'évaluation
- C1S1 Statistics PacketDocument24 pagesC1S1 Statistics PacketPrathyusha KorrapatiPas encore d'évaluation
- Chapter 6 Chi-squared Test SolutionsDocument5 pagesChapter 6 Chi-squared Test SolutionsDanyValentinPas encore d'évaluation
- Notes For Group (Group Number 1)Document4 pagesNotes For Group (Group Number 1)Saif BakrPas encore d'évaluation
- 3.data Summarizing and Presentation PDFDocument34 pages3.data Summarizing and Presentation PDFIoana CroitoriuPas encore d'évaluation
- SkewnessDocument12 pagesSkewnessHarold Jhay AcobaPas encore d'évaluation
- Homework M2 SolutionDocument9 pagesHomework M2 Solutionbonface mukuvaPas encore d'évaluation
- Q4 LAS 4 Measures of VariabilityDocument34 pagesQ4 LAS 4 Measures of VariabilityErnesto S. Caseres JrPas encore d'évaluation
- Standard DeviationDocument15 pagesStandard DeviationMNMPas encore d'évaluation
- Project 1 - Descriptive StatisticsDocument11 pagesProject 1 - Descriptive StatisticsAna ChikovaniPas encore d'évaluation
- STAT 700 Homework 5Document10 pagesSTAT 700 Homework 5ngyncloudPas encore d'évaluation
- Breiman1996 Article BaggingPredictors PDFDocument18 pagesBreiman1996 Article BaggingPredictors PDFRajesh SunarkaniPas encore d'évaluation
- Part I: Trust and Confidence 1)Document4 pagesPart I: Trust and Confidence 1)Ontiq DeyPas encore d'évaluation
- CHAPTER 1 Descriptive StatisticsDocument5 pagesCHAPTER 1 Descriptive StatisticsOana Şi CosminPas encore d'évaluation
- Solutions - Lab 4 - Assumptions & Multiple Comparisons: Learning OutcomesDocument23 pagesSolutions - Lab 4 - Assumptions & Multiple Comparisons: Learning OutcomesAbery AuPas encore d'évaluation
- Textbook Practice Problems 1Document39 pagesTextbook Practice Problems 1this hihiPas encore d'évaluation
- The Simulation and Analysis by Digital Computer of Biochemical Systems in Terms of Kinetic Models I. The Choice of Integration MethodDocument9 pagesThe Simulation and Analysis by Digital Computer of Biochemical Systems in Terms of Kinetic Models I. The Choice of Integration MethodNélia LimaPas encore d'évaluation
- Symbolic Genetic ProgrammingDocument8 pagesSymbolic Genetic ProgrammingvinhxuannPas encore d'évaluation
- Measures of Variation in DataDocument8 pagesMeasures of Variation in DataNJeric Ligeralde AresPas encore d'évaluation
- Quiz 3 - Nguyen Van ChieuDocument4 pagesQuiz 3 - Nguyen Van ChieuĐoàn Nhâm TânPas encore d'évaluation
- Chapter 9. Multiple Comparisons and Trends Among Treatment MeansDocument21 pagesChapter 9. Multiple Comparisons and Trends Among Treatment MeanskassuPas encore d'évaluation
- Descriptive Descriptive Analysis and Histograms 1.1 Recode 1.2 Select Cases & Split File 2. ReliabilityDocument6 pagesDescriptive Descriptive Analysis and Histograms 1.1 Recode 1.2 Select Cases & Split File 2. Reliabilitydmihalina2988100% (1)
- Factorial Analysis of VarianceDocument20 pagesFactorial Analysis of VarianceRiza Arifianto MarasabessyPas encore d'évaluation
- Mathematical Statistics With Applications 7th Edition, Wackerly CH 1 Solution ManualDocument7 pagesMathematical Statistics With Applications 7th Edition, Wackerly CH 1 Solution ManualaculaatacaPas encore d'évaluation
- Dosis Respuesta RDocument11 pagesDosis Respuesta RjustpoorboyPas encore d'évaluation
- HW 3 SolutionDocument6 pagesHW 3 SolutionkwrdkcPas encore d'évaluation
- Logistic Regression in MinitabDocument4 pagesLogistic Regression in MinitabMario Batista GomesPas encore d'évaluation
- Central TendencyDocument11 pagesCentral Tendencyrchandra2473Pas encore d'évaluation
- BSChem-Statistics in Chemical Analysis PDFDocument6 pagesBSChem-Statistics in Chemical Analysis PDFKENT BENEDICT PERALESPas encore d'évaluation
- Chapter 1 - Solutions of ExercisesDocument4 pagesChapter 1 - Solutions of ExercisesDanyValentinPas encore d'évaluation
- Introduction To BiplotDocument22 pagesIntroduction To BiplotIvan CordovaPas encore d'évaluation
- TN 50 Statistical Analysis of Simple Agricultural ExperimentsDocument20 pagesTN 50 Statistical Analysis of Simple Agricultural ExperimentsIsaiah Gabriel MallariPas encore d'évaluation
- Examples Biostatistics. FinalDocument90 pagesExamples Biostatistics. FinalabdihakemPas encore d'évaluation
- assignment GLMDocument3 pagesassignment GLMjoseeoodhiamboPas encore d'évaluation
- Chapter 04 Dimension Reduction (R)Document27 pagesChapter 04 Dimension Reduction (R)hasanPas encore d'évaluation
- 91 OrdlogisticDocument4 pages91 OrdlogisticChristian Bosch TaylanPas encore d'évaluation
- Mathematical Statistics With Applications Chapter1 SolutionDocument7 pagesMathematical Statistics With Applications Chapter1 Solution정예진Pas encore d'évaluation
- Author(s) Prerequisites Learning Objectives: Measures of VariabilityDocument17 pagesAuthor(s) Prerequisites Learning Objectives: Measures of Variabilityblaze_212Pas encore d'évaluation
- Two-Way ANOVA Exercises Answers: F MS MSE DF DFDocument5 pagesTwo-Way ANOVA Exercises Answers: F MS MSE DF DFBig Rock Farm ResortPas encore d'évaluation
- Modest AdaBoostDocument4 pagesModest AdaBoostLucas GallindoPas encore d'évaluation
- Algebra Secret RevealedComplete Guide to Mastering Solutions to Algebraic EquationsD'EverandAlgebra Secret RevealedComplete Guide to Mastering Solutions to Algebraic EquationsPas encore d'évaluation
- A First Look at Perturbation TheoryD'EverandA First Look at Perturbation TheoryÉvaluation : 4.5 sur 5 étoiles4.5/5 (3)
- Alumni Thank You NoteDocument1 pageAlumni Thank You NotecincinmindyPas encore d'évaluation
- Thesis Presentation 10/14Document20 pagesThesis Presentation 10/14cincinmindyPas encore d'évaluation
- CapeTownPressrelease 2015sept13Document3 pagesCapeTownPressrelease 2015sept13cincinmindyPas encore d'évaluation
- Anso EssayDocument6 pagesAnso EssaycincinmindyPas encore d'évaluation
- Meal Plan MathDocument2 pagesMeal Plan MathcincinmindyPas encore d'évaluation
- Brain Parts Mneumonics PacketDocument35 pagesBrain Parts Mneumonics Packetshivam_newPas encore d'évaluation
- Useless ThingDocument2 pagesUseless ThingcincinmindyPas encore d'évaluation
- Central Limit Theorem SimulationDocument8 pagesCentral Limit Theorem SimulationcincinmindyPas encore d'évaluation
- HW 6Document9 pagesHW 6cincinmindyPas encore d'évaluation
- Bodyfat Revisited, Revisited: Read - Delim With PlotDocument8 pagesBodyfat Revisited, Revisited: Read - Delim With PlotcincinmindyPas encore d'évaluation
- EMT Course ScheduleDocument4 pagesEMT Course SchedulecincinmindyPas encore d'évaluation
- HW 5Document6 pagesHW 5cincinmindyPas encore d'évaluation
- HW 4Document6 pagesHW 4cincinmindyPas encore d'évaluation
- HW 7Document18 pagesHW 7cincinmindyPas encore d'évaluation
- Liao HW 3: Read - DelimDocument7 pagesLiao HW 3: Read - DelimcincinmindyPas encore d'évaluation
- Lab I Assignment: (Continued On Next Page) !Document4 pagesLab I Assignment: (Continued On Next Page) !cincinmindyPas encore d'évaluation
- Using Mplus: In: Using Mplus For Structural Equation Modeling: A Researcher's GuideDocument15 pagesUsing Mplus: In: Using Mplus For Structural Equation Modeling: A Researcher's Guidemesay83Pas encore d'évaluation
- Field2000 (Chapter1) PDFDocument32 pagesField2000 (Chapter1) PDFquaser79Pas encore d'évaluation
- SM 38Document58 pagesSM 38ayushPas encore d'évaluation
- Assignment 01 BSTDocument51 pagesAssignment 01 BSTIshita PandeyPas encore d'évaluation
- Econometrics Project Analysis of P&G Company ProfitsDocument17 pagesEconometrics Project Analysis of P&G Company ProfitsDiana RoșcaPas encore d'évaluation
- Unit 5 Non-Parametric Tests Parametric TestsDocument5 pagesUnit 5 Non-Parametric Tests Parametric TestsMasuma Begam MousumiPas encore d'évaluation
- Sample SizeDocument28 pagesSample SizeDelshad BotaniPas encore d'évaluation
- Descriptive Statistics ToolsDocument21 pagesDescriptive Statistics Toolsvisual3d0% (1)
- Epidemiologi Klinik Dan Biostatistik: Oleh DR Ihsan Satria 20190309183Document11 pagesEpidemiologi Klinik Dan Biostatistik: Oleh DR Ihsan Satria 20190309183reza saka100% (1)
- Critical Values For Pearson's Correlation CoefficientDocument3 pagesCritical Values For Pearson's Correlation CoefficientMark RamirezPas encore d'évaluation
- Statistical MethodsDocument65 pagesStatistical Methodsrecep100% (4)
- CFA and Factor Analysis Techniques for Measuring Latent ConstructsDocument27 pagesCFA and Factor Analysis Techniques for Measuring Latent ConstructsTram AnhPas encore d'évaluation
- CH 13Document112 pagesCH 13Christian Alfred VillenaPas encore d'évaluation
- Predictive Role of Hand and Foot Dimensions in Stature EstimationDocument6 pagesPredictive Role of Hand and Foot Dimensions in Stature EstimationBAYUPas encore d'évaluation
- Community Project: Friedman TestDocument3 pagesCommunity Project: Friedman TestLeah Mae AgustinPas encore d'évaluation
- CourseWork Assessments S1 2019-2020Document6 pagesCourseWork Assessments S1 2019-2020jemimaPas encore d'évaluation
- Besar SampelDocument49 pagesBesar SampelSpartan xxxPas encore d'évaluation
- Discovering Statistics Using Ibm Spss Statistics 5th Edition Field Test BankDocument9 pagesDiscovering Statistics Using Ibm Spss Statistics 5th Edition Field Test Bankdacdonaldnxv1zq92% (24)
- Paper 1research MethodologyDocument2 pagesPaper 1research MethodologySg_manikandanPas encore d'évaluation
- Quiz 5 (Chapter 5 Science Engineering)Document5 pagesQuiz 5 (Chapter 5 Science Engineering)loe missyouPas encore d'évaluation
- AS Project ReportDocument22 pagesAS Project ReportLohitha PakalapatiPas encore d'évaluation
- Section and SolutionDocument4 pagesSection and SolutionFiromsaPas encore d'évaluation
- Testing Differences between Two Population MeansDocument5 pagesTesting Differences between Two Population MeansYolanda DescallarPas encore d'évaluation
- Chap8 HM PDFDocument114 pagesChap8 HM PDFaboudy noureddinePas encore d'évaluation
- Winsorized Modified One Step M-Estimator As A Measure of The Central Tendency in The Alexander-Govern TestDocument13 pagesWinsorized Modified One Step M-Estimator As A Measure of The Central Tendency in The Alexander-Govern Test23222048Pas encore d'évaluation
- Estimating The Economic Model of Crime With Panel Data: June 2019Document12 pagesEstimating The Economic Model of Crime With Panel Data: June 2019aiPas encore d'évaluation
- Active Learning Task 12Document8 pagesActive Learning Task 12haptyPas encore d'évaluation
- (I2h Ad8 Mna) HomewDocument4 pages(I2h Ad8 Mna) HomewPooja JainPas encore d'évaluation
- 2.13.practical Example - Descriptive Statistics Exercise SolutionDocument31 pages2.13.practical Example - Descriptive Statistics Exercise SolutionAbdullah NH67% (3)
- 5950 2019 Assignment 7 Spearman RhoDocument1 page5950 2019 Assignment 7 Spearman RhoNafis SolehPas encore d'évaluation