Vous aimerez peut-être aussi
- Grade 10 12 Understanding The Principles of MathematicsDocument129 pagesGrade 10 12 Understanding The Principles of MathematicsChristabel C kangoPas encore d'évaluation
- Abstract, LinearDocument100 pagesAbstract, LinearMonty SigmundPas encore d'évaluation
- Statistics Quiz 1 - SolutionsDocument11 pagesStatistics Quiz 1 - SolutionsAndrew LimPas encore d'évaluation
- Maths 4 MGTDocument251 pagesMaths 4 MGTGUDATA ABARAPas encore d'évaluation
- Probabiliy DistributionDocument22 pagesProbabiliy DistributionJakia SultanaPas encore d'évaluation
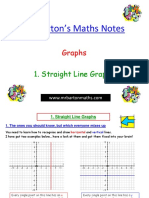
- MR Barton's Maths Notes: GraphsDocument10 pagesMR Barton's Maths Notes: GraphsbaljbaPas encore d'évaluation
- HANDOUT Rvu Maths For BusinessDocument80 pagesHANDOUT Rvu Maths For BusinessGUDATA ABARAPas encore d'évaluation
- Midterm SampleDocument6 pagesMidterm SampleBurakPas encore d'évaluation
- GMAT Chapter 8 - AveragesDocument13 pagesGMAT Chapter 8 - AveragesCambridgeSchool NoidaPas encore d'évaluation
- Linear Programming Formulation ExamplesDocument23 pagesLinear Programming Formulation Examplesseifer898Pas encore d'évaluation
- Multivariate Linear RegressionDocument30 pagesMultivariate Linear RegressionesjaiPas encore d'évaluation
- Measure of Central TendencyDocument113 pagesMeasure of Central TendencyRajdeep DasPas encore d'évaluation
- Assessment Paper and Instructions To CandidatesDocument3 pagesAssessment Paper and Instructions To CandidatesJohn DoePas encore d'évaluation
- Unit Objectives: Unit One Linear Equations and Their Interpretative ApplicationsDocument254 pagesUnit Objectives: Unit One Linear Equations and Their Interpretative ApplicationsJaatooPas encore d'évaluation
- IDIA Maths ModuleDocument174 pagesIDIA Maths ModuleKartikay Agarwal100% (1)
- ARCH ModelDocument26 pagesARCH ModelAnish S.MenonPas encore d'évaluation
- Introduction To MatricesDocument54 pagesIntroduction To MatricesChongMYPas encore d'évaluation
- Tutorial 3 Decision TreeDocument2 pagesTutorial 3 Decision TreeSyaz AmriPas encore d'évaluation
- Chapter 04Document17 pagesChapter 04Ena BorlatPas encore d'évaluation
- Ch8 Confidence Interval Estimation Part1 - Suggested Problems SolutionsDocument4 pagesCh8 Confidence Interval Estimation Part1 - Suggested Problems SolutionsmaxentiussPas encore d'évaluation
- Quantitative Techniques in FinanceDocument31 pagesQuantitative Techniques in FinanceAshraj_16Pas encore d'évaluation
- Unit-3 IGNOU STATISTICSDocument13 pagesUnit-3 IGNOU STATISTICSCarbideman100% (1)
- Multiple Regression: X X, Then The Form of The Model Is Given byDocument12 pagesMultiple Regression: X X, Then The Form of The Model Is Given byezat syafiqPas encore d'évaluation
- To Find The Last Digits of A Large PowerDocument6 pagesTo Find The Last Digits of A Large PowerPrabhanjan MannariPas encore d'évaluation
- Free PDF Modular ArithmeticDocument2 pagesFree PDF Modular ArithmeticGordo0% (1)
- Lecture Notes MTH302 Before MTT MyersDocument88 pagesLecture Notes MTH302 Before MTT MyersAmit KumarPas encore d'évaluation
- Chap 010Document2 pagesChap 010BG Monty 1Pas encore d'évaluation
- SPII - Grade 8 Mathematics - Curriculum REVISEDDocument50 pagesSPII - Grade 8 Mathematics - Curriculum REVISEDJay B Gayle0% (1)
- Measure of DispersionDocument3 pagesMeasure of DispersionKrishnaPas encore d'évaluation
- Chapter One: DebremarkosuniversityDocument110 pagesChapter One: DebremarkosuniversityFaizPas encore d'évaluation
- Matrices UpdateDocument6 pagesMatrices Updateapi-349545585100% (1)
- Centre of EnlargementDocument48 pagesCentre of EnlargementAteef HatifaPas encore d'évaluation
- Karl Pearson's Measure of SkewnessDocument27 pagesKarl Pearson's Measure of SkewnessdipanajnPas encore d'évaluation
- Final Report Business MathematicsDocument70 pagesFinal Report Business MathematicsSifatShoaebPas encore d'évaluation
- Chapter 3, 4Document7 pagesChapter 3, 4Usman JillaniPas encore d'évaluation
- Chicago Booth BUS 41100 Practice Final Exam Fall 2020 SolutionsDocument7 pagesChicago Booth BUS 41100 Practice Final Exam Fall 2020 SolutionsJohnPas encore d'évaluation
- Chapter 2 PowerpointDocument29 pagesChapter 2 Powerpointalii2223Pas encore d'évaluation
- Simple Linear RegressionDocument124 pagesSimple Linear RegressionPratama Yuly NugrahaPas encore d'évaluation
- 2nd Year Honours Syllabus of Finance and BankingDocument8 pages2nd Year Honours Syllabus of Finance and Bankingjewel7ranaPas encore d'évaluation
- Calculus (Test 1 Question)Document5 pagesCalculus (Test 1 Question)Bala GanabathyPas encore d'évaluation
- Digital Unit Plan Template Final 2Document3 pagesDigital Unit Plan Template Final 2api-400093008Pas encore d'évaluation
- 10 - 1 Simplifying Rational Expressions Trout 09Document14 pages10 - 1 Simplifying Rational Expressions Trout 09Vehid KurtićPas encore d'évaluation
- LESSON 1 Introduction To StatisticsDocument39 pagesLESSON 1 Introduction To StatisticsJhay Anne Pearl Menor100% (1)
- D. EquationsDocument39 pagesD. Equationsmumtaz aliPas encore d'évaluation
- Mth-382 Analytical Dynamics: MSC MathematicsDocument51 pagesMth-382 Analytical Dynamics: MSC MathematicsediealiPas encore d'évaluation
- Various Measures of Central Tendenc1Document45 pagesVarious Measures of Central Tendenc1Mohammed Demssie MohammedPas encore d'évaluation
- Day3 - Ratios and ProportionsDocument29 pagesDay3 - Ratios and ProportionsFfrekgtreh FygkohkPas encore d'évaluation
- Integers: Comparing and OrderingDocument19 pagesIntegers: Comparing and OrderingNino-prexy AcdalPas encore d'évaluation
- M132 Tutorial - 1 Ch.1 - Sec.1.1-1.2Document36 pagesM132 Tutorial - 1 Ch.1 - Sec.1.1-1.2AhmadPas encore d'évaluation
- Unit-3 DS StudentsDocument35 pagesUnit-3 DS StudentsHarpreet Singh BaggaPas encore d'évaluation
- Elements of Taxation Elements of Taxatio PDFDocument24 pagesElements of Taxation Elements of Taxatio PDFTuryamureeba JuliusPas encore d'évaluation
- 10 Step Lesson PlanDocument5 pages10 Step Lesson Planapi-325889338Pas encore d'évaluation
- Mathematics: Sindh Textbook Board, JamshoroDocument188 pagesMathematics: Sindh Textbook Board, JamshoroZahid SharPas encore d'évaluation
- IGNOU - Lecture Notes - Linear AlgebraDocument29 pagesIGNOU - Lecture Notes - Linear Algebraruchi21julyPas encore d'évaluation
- Quartiles For Discrete Data Class 7Document2 pagesQuartiles For Discrete Data Class 7afzabbasiPas encore d'évaluation
- Bar Graph-Wps OfficeDocument16 pagesBar Graph-Wps OfficeRahul ParmarPas encore d'évaluation
- Mathematics Form 3 (Staitstics II)Document18 pagesMathematics Form 3 (Staitstics II)ClamentPas encore d'évaluation
- Solution of Assignment # 1Document10 pagesSolution of Assignment # 1Abrar Ul HaqPas encore d'évaluation
- Week 4 Lab Procedure: Part 1 - Polynomial FitDocument8 pagesWeek 4 Lab Procedure: Part 1 - Polynomial FitMark CyrulikPas encore d'évaluation
- Math 1050 Project 3 Linear Least Squares ApproximationDocument9 pagesMath 1050 Project 3 Linear Least Squares Approximationapi-233311543Pas encore d'évaluation
- Course Outline of ComplexDocument3 pagesCourse Outline of ComplexTehreem AyazPas encore d'évaluation
- The Influence of Leadership Styles On Employees Perfromance in Bole Sub City Education Sectors Addis Ababa EthiopiaDocument5 pagesThe Influence of Leadership Styles On Employees Perfromance in Bole Sub City Education Sectors Addis Ababa EthiopiaIJIREMPas encore d'évaluation
- Research MethodsDocument250 pagesResearch MethodsM ZahidPas encore d'évaluation
- ZE+BA (EDUA630-4) Solution - 061837Document5 pagesZE+BA (EDUA630-4) Solution - 061837Mudassir HussainPas encore d'évaluation
- Storytelling To Enhance Speaking and Listening Skills For English Young Learners: A Case Study at Language Centers in Binh Duong ProvinceDocument8 pagesStorytelling To Enhance Speaking and Listening Skills For English Young Learners: A Case Study at Language Centers in Binh Duong ProvinceHai Hau Tran100% (1)
- Research NewDocument34 pagesResearch Newwinstonjohn.isaacPas encore d'évaluation
- Activity 2 Monkey Business !: DiscussionDocument3 pagesActivity 2 Monkey Business !: DiscussionDSAW VALERIOPas encore d'évaluation
- Chapter 9 Measurement and Scaling: Noncomparative Scaling TechniquesDocument22 pagesChapter 9 Measurement and Scaling: Noncomparative Scaling TechniquesTrâm MờPas encore d'évaluation
- Research Methodology by C.R.kothariDocument11 pagesResearch Methodology by C.R.kothariBala Subramaniyam50% (2)
- TFM Ferespe CarolinaGuimaraes FINALDocument60 pagesTFM Ferespe CarolinaGuimaraes FINALAdnanPas encore d'évaluation
- Descriptive StatisticsDocument11 pagesDescriptive StatisticsTeresito AbsalonPas encore d'évaluation
- Swot AnalysisDocument7 pagesSwot AnalysisPrasanth Mattammal100% (3)
- Appreciation Uniquely Predicts Life Satisfaction Above DemographicsDocument5 pagesAppreciation Uniquely Predicts Life Satisfaction Above DemographicsAmrina Husna SalimahPas encore d'évaluation
- Chapter 1 PDFDocument7 pagesChapter 1 PDFJabin shihab0% (1)
- Entrepreneurship Internal Assessment Health Industry IaDocument10 pagesEntrepreneurship Internal Assessment Health Industry IaCalm DownPas encore d'évaluation
- For Unit 1 - Mikkelson Chapter 3Document12 pagesFor Unit 1 - Mikkelson Chapter 3KanakPas encore d'évaluation
- Comparison of ISO 17025Document4 pagesComparison of ISO 17025Susan CarterPas encore d'évaluation
- Math7 q4 w2 Studentsversion v1Document10 pagesMath7 q4 w2 Studentsversion v1Mark Christian Dimson GalangPas encore d'évaluation
- Geografi Tanaman, TerapanDocument279 pagesGeografi Tanaman, TerapanOom Saepul RohmanPas encore d'évaluation
- AGMA 2015 915-1-A02Document108 pagesAGMA 2015 915-1-A02danielk32100% (1)
- Disertasi AkuntansiDocument10 pagesDisertasi AkuntansiEcko Ione PurwantoPas encore d'évaluation
- Research ProjectDocument39 pagesResearch ProjectShaira Mae VelascoPas encore d'évaluation
- 32 586 4 PB PDFDocument10 pages32 586 4 PB PDFJericho F. DelavinPas encore d'évaluation
- Analyze The Challenges and Problems in Air Cargo Operations, Chennai, Tamil NaduDocument5 pagesAnalyze The Challenges and Problems in Air Cargo Operations, Chennai, Tamil Naduarulrajpec2001gmailcomPas encore d'évaluation
- NMC Hospital Abu Dhabi - 2011!06!08Document16 pagesNMC Hospital Abu Dhabi - 2011!06!08Manjul TaklePas encore d'évaluation
- ANNEX B. Form 2a Structured List of PPAs Per Sector (Long List) MEEDODocument3 pagesANNEX B. Form 2a Structured List of PPAs Per Sector (Long List) MEEDODiana Grace100% (1)
- LIMCON Design GuideDocument9 pagesLIMCON Design GuideMatthew JohnstonPas encore d'évaluation
- Historiopreneurship Related Paper 3Document13 pagesHistoriopreneurship Related Paper 3Salah KitaPas encore d'évaluation
- Training and Development in HALDocument58 pagesTraining and Development in HALyoganthmurthy100% (1)
- Worksheet: Qualitative vs. Quantitative Observations w8.SILN.1Document2 pagesWorksheet: Qualitative vs. Quantitative Observations w8.SILN.1Aisaka TaigaPas encore d'évaluation