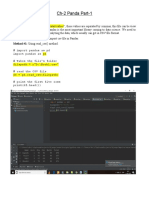
Reading json directly into pandas
http://hayd.github.io/2013/pandas-json/
Andy Hayden
Reading json directly into pandas
12 Jun 2013
New to pandas 0.12 release, is a read_json function (which uses the speedy ujson under the hood).
Andy Hayden
It's as easy as whacking in the path/url/string of a valid json:
Python Data
Hacker
In [1]: df = pd.read_json('https://api.github.com/repos/pydata/pandas/issues?per_page=5'
resume
Let's inspect a few columns to see how we've done:
In [2]: df[['created_at', 'title', 'body', 'comments']]
Out[2]:
created_at
0 2013-06-12 02:54:37
title
DOC add to_datetime to api.rst
1 2013-06-12 01:16:19
ci/after_script.sh missing?
2 2013-06-11 23:07:52
ENH Prefer requests over urllib2
3 2013-06-11 21:12:45
4 2013-06-11 19:50:17
Nothing in docs about io.data
DOC: Clarify quote behavior parameters
Either I'm being thick or `to_da
https://travisAt the moment we
There's nothing on the docs abou
I've been bit many times recentl
The parse_dates argument has a good crack at parsing any columns which look like they're dates, and
it's worked in this example (converting created_at to Timestamps). It looks carefully at the datatype and at
column names (you can pass also pass a column name explicitly to ensure it gets converted) to choose
which to parse.
After you've done some analysis in your favourite data analysis library, the corresponding to_json allows
you can export results to valid json.
In [4]: res = df[['created_at', 'title', 'body', 'comments']].head()
In [5]: res.to_json()
Out[5]: '{"created_at":{"0":1370695148000000000,"1":1370665875000000000,"2":1370656273000000000
Here, orient decides how we should layout the data:
orient : {'split', 'records', 'index', 'columns', 'values'},
default is 'index' for Series, 'columns' for DataFrame
The format of the JSON string
split : dict like
{index -> [index], columns -> [columns], data -> [values]}
records : list like [{column -> value}, ... , {column -> value}]
index : dict like {index -> {column -> value}}
columns : dict like {column -> {index -> value}}
values : just the values array
For example (note times have been exported as epoch, but we could have used iso via):
In [6]: res.to_json(orient='records')
1 de 3
23/12/14 03:17
Reading json directly into pandas
http://hayd.github.io/2013/pandas-json/
Out[6]: '[{"created_at":1370695148000000000,"title":"CLN: refactored url accessing and filepath
Note, our times have been converted to unix timestamps (which also means we'd need to use the same
pd.to_datetime trick when read_json it back in). Also NaNs, NaTs and Nones will be converted to JSON's
null.
And save it to a le:
In [7]: res.to_json(file_name)
Useful.
Warning: read_json requires valid JSON, so doing something like will cause some Exception:
In [8]: pd.read_json("{'0':{'0':1,'1':3},'1':{'0':2,'1':4}}")
# ValueError, since this isn't valid JSON
In [9]: pd.read_json('{"0":{"0":1,"1":3},"1":{"0":2,"1":4}}')
Out[9]:
0
Just as an further example, here I can get all the issues from github (there's a limit of 100 per request), this
is how easy it is to extract data in pandas:
In [10]: page = 1
df = pd.read_json('https://api.github.com/repos/pydata/pandas/issues?page=
while df:
dfs[page] = df
page += 1
df = pd.read_json('https://api.github.com/repos/pydata/pandas/issues?page=
In [11]: dfs.keys() # 7 requests come back with issues
Out[11]: [1, 2, 3, 4, 5, 6, 7]
In [12]: df = pd.concat(dfs, ignore_index=True).set_index('number)
In [13]: df
Out[13]:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 613 entries, 3813 to 39
Data columns (total 18 columns):
2 de 3
assignee
27
body
613
non-null values
closed_at
comments
613
non-null values
comments_url
613
non-null values
created_at
613
non-null values
events_url
html_url
613
613
non-null values
non-null values
id
613
non-null values
labels
labels_url
613
613
non-null values
non-null values
non-null values
non-null values
23/12/14 03:17
Reading json directly into pandas
milestone
pull_request
586
613
non-null values
non-null values
state
613
non-null values
title
613
non-null values
updated_at
613
non-null values
url
613
non-null values
user
613
non-null values
http://hayd.github.io/2013/pandas-json/
dtypes: datetime64[ns](1), int64(2), object(15)
In [14]: df.comments.describe()
Out[14]:
count
613.000000
mean
3.590538
std
min
9.641128
0.000000
25%
50%
0.000000
1.000000
75%
4.000000
max
185.000000
dtype: float64
It deals with fairly moderately sized les fairly eciently, here's a 200Mb le (this is on my 2009 macbook
air, I'd expect times to be may be faster on better hardware e.g. an SSD):
In [15]: %time pd.read_json('citylots.json')
CPU times: user 4.78 s, sys: 684 ms, total: 5.46 s
Wall time: 5.89 s
Thanks to wesm, jreback and Komnomnomnom for putting it together.
Ghostery ha bloqueado los comentarios creados por Disqus.
blog comments powered by Disqus
3 de 3
23/12/14 03:17
Vous aimerez peut-être aussi
- DA0101EN-Review-Introduction - Jupyter NotebookDocument8 pagesDA0101EN-Review-Introduction - Jupyter NotebookSohail DoulahPas encore d'évaluation
- Intro To PandasDocument7 pagesIntro To PandasThe path to AllahPas encore d'évaluation
- Data Wrangling With Python and PandasDocument7 pagesData Wrangling With Python and PandasCarlos Andrés PérezPas encore d'évaluation
- Tensorflow and Keras Apis: 0.1 Computer Vision: Neural Networks and Deep LearningDocument32 pagesTensorflow and Keras Apis: 0.1 Computer Vision: Neural Networks and Deep LearningGuy Anthony NAMA NYAMPas encore d'évaluation
- 1 Pandas BasicsDocument13 pages1 Pandas BasicsBikuPas encore d'évaluation
- Pandas BasicsDocument21 pagesPandas BasicsDhruv BhardwajPas encore d'évaluation
- Ch-2 - Panda - Part-1 - 3rd - DayDocument5 pagesCh-2 - Panda - Part-1 - 3rd - DayRC SharmaPas encore d'évaluation
- PandasDocument41 pagesPandasGabriel ChakhvashviliPas encore d'évaluation
- SESION 10 (Pandas 2)Document120 pagesSESION 10 (Pandas 2)2marlenehh2003Pas encore d'évaluation
- CHP 8 PandasDocument49 pagesCHP 8 PandasHeshalini Raja GopalPas encore d'évaluation
- How To Store Any File Into SQL DatabaseDocument15 pagesHow To Store Any File Into SQL DatabaseAbigail Mayled LausPas encore d'évaluation
- How To Create DataFrame in PythonDocument6 pagesHow To Create DataFrame in PythonaaaaPas encore d'évaluation
- Pandas Dataframe Export The CSV FileDocument9 pagesPandas Dataframe Export The CSV Fileammouna bengPas encore d'évaluation
- PandasDocument16 pagesPandasHoneyPas encore d'évaluation
- Exp1 - Manipulating Datasets Using PandasDocument15 pagesExp1 - Manipulating Datasets Using PandasmnbatrawiPas encore d'évaluation
- Learn Python Pandas For Data Science Quick TutorialExamples For All Primary Operations of DataFramesDocument37 pagesLearn Python Pandas For Data Science Quick TutorialExamples For All Primary Operations of DataFramesJuanito AlimañaPas encore d'évaluation
- MOD-3 DapDocument41 pagesMOD-3 DapVarshitha KnPas encore d'évaluation
- 20BCE1779 - Web Mining - Lab-5Document8 pages20BCE1779 - Web Mining - Lab-5Patel VedantPas encore d'évaluation
- YouTube DownLoaderDocument20 pagesYouTube DownLoaderMackos-GnuPas encore d'évaluation
- Eda Unit 2Document65 pagesEda Unit 260 Vibha Shree.SPas encore d'évaluation
- Pip3 Install JupyterDocument16 pagesPip3 Install Jupyterblah blPas encore d'évaluation
- Pandas DataframeDocument48 pagesPandas DataframeJames PrakashPas encore d'évaluation
- XII - Informatics Practices (LAB MANUAL)Document42 pagesXII - Informatics Practices (LAB MANUAL)ghun assudaniPas encore d'évaluation
- PySpark Transformations TutorialDocument58 pagesPySpark Transformations Tutorialravikumar lanka100% (1)
- CSV File: CSV (Comma-Separated Value) Files Are A Common File Format ForDocument14 pagesCSV File: CSV (Comma-Separated Value) Files Are A Common File Format ForRasik ThapaPas encore d'évaluation
- Python PandasDocument1 pagePython PandasHenish N JainPas encore d'évaluation
- Extjs ZendDocument6 pagesExtjs ZendAndrea AnacletoPas encore d'évaluation
- Howto SortingDocument6 pagesHowto SortingITTeamPas encore d'évaluation
- 5CS037 WS02 PandasForDataAnalysisDocument30 pages5CS037 WS02 PandasForDataAnalysisPankaj MahatoPas encore d'évaluation
- Pandas TutorialDocument21 pagesPandas TutorialKEVIN KUMARPas encore d'évaluation
- PandasDocument82 pagesPandasaacharyadhruv1310Pas encore d'évaluation
- Sorting HOW TO: Guido Van Rossum Fred L. Drake, JR., EditorDocument6 pagesSorting HOW TO: Guido Van Rossum Fred L. Drake, JR., Editordalequenosvamos100% (1)
- SQL Server Interview Questions Answers Set 11Document9 pagesSQL Server Interview Questions Answers Set 11gautam singhPas encore d'évaluation
- Importing Data Into Pandas DataframesDocument5 pagesImporting Data Into Pandas DataframesMano KaviPas encore d'évaluation
- Miscellaneous R Notes: C 2005 Ben Bolker September 15, 2005Document2 pagesMiscellaneous R Notes: C 2005 Ben Bolker September 15, 2005juntujuntuPas encore d'évaluation
- Lecture Material 3Document7 pagesLecture Material 32021me372Pas encore d'évaluation
- Kunj Project 2Document31 pagesKunj Project 2kunj123sharmaPas encore d'évaluation
- Python Data Wrangling Tutorial: Pandas CheatsheetDocument1 pagePython Data Wrangling Tutorial: Pandas CheatsheetRajasPas encore d'évaluation
- How To Pull Data From A Microsoft SQL Database: Pandas PD Sys SqlalchemyDocument4 pagesHow To Pull Data From A Microsoft SQL Database: Pandas PD Sys SqlalchemyMamataMaharanaPas encore d'évaluation
- Mango PerlDocument12 pagesMango Perlraghu4infoPas encore d'évaluation
- 05 Data Loading, Storage and Wrangling-1Document22 pages05 Data Loading, Storage and Wrangling-1FucKerWengiePas encore d'évaluation
- Worksheet - PandasDocument16 pagesWorksheet - PandasDrishtiPas encore d'évaluation
- Improving Performance of SQLite Data 1703882908Document8 pagesImproving Performance of SQLite Data 1703882908James FlintPas encore d'évaluation
- Howto SortingDocument6 pagesHowto SortingJason DavisPas encore d'évaluation
- Pandas PDFDocument2 827 pagesPandas PDFChristopher Paco AliagaPas encore d'évaluation
- Unit-03: Capturing, Preparing and Working With DataDocument41 pagesUnit-03: Capturing, Preparing and Working With DataMubaraka KundawalaPas encore d'évaluation
- Financial Analytics With PythonDocument40 pagesFinancial Analytics With PythonHarshit Singh100% (1)
- 5 Advanced Features of Pandas and How To Use ThemDocument10 pages5 Advanced Features of Pandas and How To Use ThemFecodPas encore d'évaluation
- ML Practical 205160694034Document33 pagesML Practical 20516069403409Samrat Bikram ShahPas encore d'évaluation
- Big Data Analytics in Apache SparkDocument79 pagesBig Data Analytics in Apache SparkArXlan XahirPas encore d'évaluation
- Class Notes: Class: XII Date: 7-Apr-2020 Subject: Informatics Practices Topic: 2. Python PandasDocument4 pagesClass Notes: Class: XII Date: 7-Apr-2020 Subject: Informatics Practices Topic: 2. Python PandasRavi RamrakhaniPas encore d'évaluation
- Python Programming - Pandas: Finn Arup NielsenDocument34 pagesPython Programming - Pandas: Finn Arup NielsenSumanth KumarPas encore d'évaluation
- Principal Component Analysis Notes : InfoDocument22 pagesPrincipal Component Analysis Notes : InfoVALMICK GUHAPas encore d'évaluation
- MongoDB Schema Design BasicsDocument51 pagesMongoDB Schema Design BasicsAlvin John RichardsPas encore d'évaluation
- Pandas Notoes For XII PDFDocument12 pagesPandas Notoes For XII PDFManish JainPas encore d'évaluation
- Howto SortingDocument6 pagesHowto SortingWisdom OkuPas encore d'évaluation
- 2 Python Data ProcessingDocument66 pages2 Python Data ProcessingShaifali Jain100% (2)
- Sorting HOW TO: Guido Van Rossum Fred L. Drake, JR., EditorDocument5 pagesSorting HOW TO: Guido Van Rossum Fred L. Drake, JR., EditorJuan PezPas encore d'évaluation
- Programming With R: Lecture #4Document34 pagesProgramming With R: Lecture #4Shubham PatidarPas encore d'évaluation
- Nº 54 GUTIERREZ-de PAULA La Arquitectura de Bs As en Tiempos de Tamburini-La Arquietctura Oficial en ArgDocument66 pagesNº 54 GUTIERREZ-de PAULA La Arquitectura de Bs As en Tiempos de Tamburini-La Arquietctura Oficial en ArgParra VictorPas encore d'évaluation
- Nº 53 SHMIDT Buschiazzo. Una Profesional Entre La Arquitectura y La ConstrucciónDocument38 pagesNº 53 SHMIDT Buschiazzo. Una Profesional Entre La Arquitectura y La ConstrucciónParra VictorPas encore d'évaluation
- 2015 Jweia BB Yt Car CyclistDocument16 pages2015 Jweia BB Yt Car CyclistParra VictorPas encore d'évaluation
- FBI SecutaryDocument136 pagesFBI SecutaryParra Victor100% (1)
- Test Aerodinamica CiclismoDocument4 pagesTest Aerodinamica CiclismoParra VictorPas encore d'évaluation
- Deshidratación en NataciónDocument13 pagesDeshidratación en NataciónParra VictorPas encore d'évaluation
- Kinematic Analysis SoftwareDocument222 pagesKinematic Analysis SoftwareParra VictorPas encore d'évaluation
- Z Order CurveDocument16 pagesZ Order CurveParra VictorPas encore d'évaluation
- Documentacio Cubes 1.0Document167 pagesDocumentacio Cubes 1.0Parra VictorPas encore d'évaluation
- Mapa Sveta - Pesma Leda I VatreDocument1 pageMapa Sveta - Pesma Leda I VatreuzorićPas encore d'évaluation
- NEHA Class NotesDocument143 pagesNEHA Class Notesritika makhijaPas encore d'évaluation
- Binary Search Tree: Typedef Struct NodeDocument7 pagesBinary Search Tree: Typedef Struct NodeSanjana chowdaryPas encore d'évaluation
- Language Processors-Assembler-Compiler-InterpreterDocument3 pagesLanguage Processors-Assembler-Compiler-InterpreternamitharPas encore d'évaluation
- G.H Gonnet, R. Baeza-Yates - Handbook of Algorithms and Data Structures in Pascal and CDocument439 pagesG.H Gonnet, R. Baeza-Yates - Handbook of Algorithms and Data Structures in Pascal and CShomik ChakrabortyPas encore d'évaluation
- 2.ER Model and NormalizationDocument21 pages2.ER Model and Normalizationtejaswi khandrikaPas encore d'évaluation
- Tia-Pro1 en 01 V14Document517 pagesTia-Pro1 en 01 V14Mario Edgar Pérez PinalPas encore d'évaluation
- CS429: Computer Organization and Architecture: Pipeline IIIDocument27 pagesCS429: Computer Organization and Architecture: Pipeline IIItanyapahwaPas encore d'évaluation
- LECTURE 7 - MANIPULATORS in C++Document22 pagesLECTURE 7 - MANIPULATORS in C++Meena Preethi BPas encore d'évaluation
- Analisis Diskriminan Untuk Validasi Cluster Pada Studi Kasus Pengelompokan Kecamatan Di Kabupaten Jember Berdasarkan Status KemiskinanDocument10 pagesAnalisis Diskriminan Untuk Validasi Cluster Pada Studi Kasus Pengelompokan Kecamatan Di Kabupaten Jember Berdasarkan Status KemiskinanFADHIILA SENJALIANAPas encore d'évaluation
- The Busy Java Developer's Guide To Scala:: Functional Programming For The Object OrientedDocument12 pagesThe Busy Java Developer's Guide To Scala:: Functional Programming For The Object OrientedeBeliBalaPas encore d'évaluation
- Using IIB Embedded Global Cache: IBM Integration BusDocument53 pagesUsing IIB Embedded Global Cache: IBM Integration BusMinh Gia100% (1)
- Lecture Day 1: Introduction To Management Science Linear ProgrammingDocument30 pagesLecture Day 1: Introduction To Management Science Linear Programmingillustra7Pas encore d'évaluation
- Data TypesDocument23 pagesData TypesShaik RasoolPas encore d'évaluation
- Bio Info 2022Document88 pagesBio Info 2022trinbago matramPas encore d'évaluation
- Shubham Jain: B.E, IT 2013Document3 pagesShubham Jain: B.E, IT 2013Vinay PunjabiPas encore d'évaluation
- Gmake TutorialDocument40 pagesGmake TutorialSylvia JanssenPas encore d'évaluation
- AWTDocument86 pagesAWTarunlaldsPas encore d'évaluation
- Industrial Training Report Final Nitin TyagiDocument65 pagesIndustrial Training Report Final Nitin Tyagisatyam jhaPas encore d'évaluation
- Documentation CFC Templates Analog - Rev.01Document10 pagesDocumentation CFC Templates Analog - Rev.01cuongPas encore d'évaluation
- ESB Compliance MatrixDocument22 pagesESB Compliance Matrixreddragon76Pas encore d'évaluation
- (CDL) Design Data Translator's Reference PDFDocument598 pages(CDL) Design Data Translator's Reference PDFAdriana NogueraPas encore d'évaluation
- HCI Lecure 10 Software ProcessDocument58 pagesHCI Lecure 10 Software ProcessdewsfefPas encore d'évaluation
- 3) Linked List (Part 2)Document27 pages3) Linked List (Part 2)budakbaik125Pas encore d'évaluation
- Chapter 1 - MatlabDocument39 pagesChapter 1 - MatlabKute LuciferPas encore d'évaluation
- James M ResumeDocument1 pageJames M Resumeapi-247627264Pas encore d'évaluation
- Pixel Crushers UNity Asset - Introduction To Text TablesDocument8 pagesPixel Crushers UNity Asset - Introduction To Text TablesJanePas encore d'évaluation
- Oo 40Document744 pagesOo 40evaldescPas encore d'évaluation
- Munashe Maponga CV PDFDocument2 pagesMunashe Maponga CV PDFAnonymous icVMooyER8Pas encore d'évaluation
- C Important Questions PDFDocument9 pagesC Important Questions PDFPradeep Kumar Reddy Reddy100% (2)
- Multiple Choice Question Bank (MCQ) Term - I & Term-II: Class - XIIDocument185 pagesMultiple Choice Question Bank (MCQ) Term - I & Term-II: Class - XIINaresh KumawatPas encore d'évaluation
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveD'EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurvePas encore d'évaluation
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldD'EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldÉvaluation : 4.5 sur 5 étoiles4.5/5 (107)
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldD'EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldÉvaluation : 4.5 sur 5 étoiles4.5/5 (55)
- Generative AI: The Insights You Need from Harvard Business ReviewD'EverandGenerative AI: The Insights You Need from Harvard Business ReviewÉvaluation : 4.5 sur 5 étoiles4.5/5 (2)
- Four Battlegrounds: Power in the Age of Artificial IntelligenceD'EverandFour Battlegrounds: Power in the Age of Artificial IntelligenceÉvaluation : 5 sur 5 étoiles5/5 (5)
- 100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziD'Everand100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziPas encore d'évaluation
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewD'EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewÉvaluation : 4.5 sur 5 étoiles4.5/5 (104)
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkD'EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkÉvaluation : 4 sur 5 étoiles4/5 (7)
- Architects of Intelligence: The truth about AI from the people building itD'EverandArchitects of Intelligence: The truth about AI from the people building itÉvaluation : 4.5 sur 5 étoiles4.5/5 (21)
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindD'EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindPas encore d'évaluation
- HBR's 10 Must Reads on AI, Analytics, and the New Machine AgeD'EverandHBR's 10 Must Reads on AI, Analytics, and the New Machine AgeÉvaluation : 4.5 sur 5 étoiles4.5/5 (69)
- The Digital Mind: How Science is Redefining HumanityD'EverandThe Digital Mind: How Science is Redefining HumanityÉvaluation : 4.5 sur 5 étoiles4.5/5 (2)
- Working with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)D'EverandWorking with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)Évaluation : 5 sur 5 étoiles5/5 (5)
- Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsD'EverandYour AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsPas encore d'évaluation
- Artificial Intelligence: A Guide for Thinking HumansD'EverandArtificial Intelligence: A Guide for Thinking HumansÉvaluation : 4.5 sur 5 étoiles4.5/5 (30)
- T-Minus AI: Humanity's Countdown to Artificial Intelligence and the New Pursuit of Global PowerD'EverandT-Minus AI: Humanity's Countdown to Artificial Intelligence and the New Pursuit of Global PowerÉvaluation : 4 sur 5 étoiles4/5 (4)
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessD'EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessPas encore d'évaluation
- Python Machine Learning - Third Edition: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow 2, 3rd EditionD'EverandPython Machine Learning - Third Edition: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow 2, 3rd EditionÉvaluation : 5 sur 5 étoiles5/5 (2)
- Artificial Intelligence & Generative AI for Beginners: The Complete GuideD'EverandArtificial Intelligence & Generative AI for Beginners: The Complete GuideÉvaluation : 5 sur 5 étoiles5/5 (1)
- Make Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryD'EverandMake Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryPas encore d'évaluation
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesD'EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesÉvaluation : 4.5 sur 5 étoiles4.5/5 (13)
- Hands-On System Design: Learn System Design, Scaling Applications, Software Development Design Patterns with Real Use-CasesD'EverandHands-On System Design: Learn System Design, Scaling Applications, Software Development Design Patterns with Real Use-CasesPas encore d'évaluation
- The Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsD'EverandThe Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsPas encore d'évaluation
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)D'EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)Pas encore d'évaluation
- How To: GPT-4 for Financial Freedom: The Entrepreneur's Guide to Thriving in the AI EraD'EverandHow To: GPT-4 for Financial Freedom: The Entrepreneur's Guide to Thriving in the AI EraÉvaluation : 4 sur 5 étoiles4/5 (9)