Vous aimerez peut-être aussi
- 02-Subgrad Method NotesDocument27 pages02-Subgrad Method NotesTifroute MohamedPas encore d'évaluation
- Solving The Dual Subproblem of The Method of Moving Asymptotes Using A Trust-Region SchemeDocument20 pagesSolving The Dual Subproblem of The Method of Moving Asymptotes Using A Trust-Region SchemeTifroute MohamedPas encore d'évaluation
- Lecture Notes in Mathematics: 1133 Krzysztof C. KiwielDocument368 pagesLecture Notes in Mathematics: 1133 Krzysztof C. KiwielTifroute MohamedPas encore d'évaluation
- ASCE Authorship Originality and CTA Form PDFDocument2 pagesASCE Authorship Originality and CTA Form PDFTifroute MohamedPas encore d'évaluation
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (344)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (587)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (73)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (265)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (119)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- BarcodeDocument24 pagesBarcodeChidgana Hegde100% (1)
- User Guide: Esc - 0 EnterDocument12 pagesUser Guide: Esc - 0 EnterLeonardo RomanPas encore d'évaluation
- Implement Ha ProxyDocument10 pagesImplement Ha Proxynguyenhapy92Pas encore d'évaluation
- Email Concurrent Request Output in Oracle Apps Using APIsDocument7 pagesEmail Concurrent Request Output in Oracle Apps Using APIsMarwa GhozPas encore d'évaluation
- Lks Palembang 2014 Modul2Document5 pagesLks Palembang 2014 Modul2Muhammad Riski AkbarPas encore d'évaluation
- CMOS Password RecoveryDocument5 pagesCMOS Password RecoveryAndreea TomaPas encore d'évaluation
- Curriculum Vitae: ObjectiveDocument3 pagesCurriculum Vitae: ObjectiveNew TonPas encore d'évaluation
- How To Convert A .Dat File To ExcelDocument3 pagesHow To Convert A .Dat File To ExcelPrankur SharmaPas encore d'évaluation
- RCF 2Document1 pageRCF 2Jericho MoralesPas encore d'évaluation
- Cryptography Lab Manual-FinalDocument36 pagesCryptography Lab Manual-FinalPraveen TPPas encore d'évaluation
- Headfirst Java 2 ND EditionDocument701 pagesHeadfirst Java 2 ND EditionAndrei Cristian100% (11)
- 1.logic Gates: OR GateDocument70 pages1.logic Gates: OR GateDinesh SharmaPas encore d'évaluation
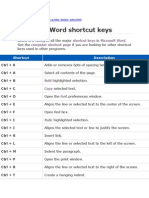
- Shortcut Keys Microsoft Word Computer Shortcut PageDocument11 pagesShortcut Keys Microsoft Word Computer Shortcut PageIRFAN KARIMPas encore d'évaluation
- Railway Welding Certification ApplicationDocument9 pagesRailway Welding Certification ApplicationCarlos Nombela PalaciosPas encore d'évaluation
- How To Configure Your Outlook GMail Account PDFDocument5 pagesHow To Configure Your Outlook GMail Account PDFraveendranPas encore d'évaluation
- Cse Vii Java and J2EE (10cs753) NotesDocument73 pagesCse Vii Java and J2EE (10cs753) NotesAkilesh Parivar100% (1)
- Source of Erros in Numerical MethodsDocument28 pagesSource of Erros in Numerical MethodsGeorge Ezar N. QuiriadoPas encore d'évaluation
- Logical ConnectivesDocument6 pagesLogical ConnectivesrupeshrajPas encore d'évaluation
- MAP Price DocumentsDocument11 pagesMAP Price Documentsmintu771Pas encore d'évaluation
- Regulations With Innovation... : Automatic Scrutiny of Building Plans & Building Plans Approval Management SystemDocument4 pagesRegulations With Innovation... : Automatic Scrutiny of Building Plans & Building Plans Approval Management SystemAlex ChristopherPas encore d'évaluation
- Rubber DurabilityDocument2 pagesRubber DurabilitySrashmiPas encore d'évaluation
- Intrusion Detection Using Decision Tree ApproachDocument28 pagesIntrusion Detection Using Decision Tree ApproachbhattajagdishPas encore d'évaluation
- MVC-2 MySQL exampleDocument19 pagesMVC-2 MySQL exampleGeorgeAntonPas encore d'évaluation
- Management System (DMS) Training: PR Quality Policy and DocumentDocument46 pagesManagement System (DMS) Training: PR Quality Policy and DocumentTommyCasillas-GerenaPas encore d'évaluation
- Math 3215 Intro. Probability & Statistics Summer '14 Homework 1Document4 pagesMath 3215 Intro. Probability & Statistics Summer '14 Homework 1Pei JingPas encore d'évaluation
- Huawei Sne Mobile Phone User Guide - (Emui9.0.1 - 01, En-Uk, Normal)Document68 pagesHuawei Sne Mobile Phone User Guide - (Emui9.0.1 - 01, En-Uk, Normal)FarzadPas encore d'évaluation
- Gasm ManualDocument12 pagesGasm ManualAbhijeet SaPas encore d'évaluation
- IEC 61850 Certificate Level A: Areva T&DDocument1 pageIEC 61850 Certificate Level A: Areva T&DsunitbhaumikPas encore d'évaluation
- PLC BSL BottlingDocument23 pagesPLC BSL BottlingkingmltPas encore d'évaluation
- Creating Delegate NodeDocument26 pagesCreating Delegate NodeRama Krishna BPas encore d'évaluation