Vous aimerez peut-être aussi
- Digital Technologies – an Overview of Concepts, Tools and Techniques Associated with itD'EverandDigital Technologies – an Overview of Concepts, Tools and Techniques Associated with itPas encore d'évaluation
- Telecom Data SheetDocument2 pagesTelecom Data SheetBhupendra JhaPas encore d'évaluation
- Ratecard Ivosights 2021Document21 pagesRatecard Ivosights 2021Somad Rachmat WidhiaPas encore d'évaluation
- Technical Proposal For Libyana GPRS Roaming Solution (V0.2)Document25 pagesTechnical Proposal For Libyana GPRS Roaming Solution (V0.2)صديقكالوفيPas encore d'évaluation
- Jukka Lintusaari IRU Ertico MaaS WorkhopDocument17 pagesJukka Lintusaari IRU Ertico MaaS WorkhopanirudhasPas encore d'évaluation
- Ipsotek VISuite DatasheetDocument2 pagesIpsotek VISuite DatasheetMaria PredanPas encore d'évaluation
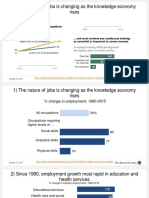
- 1) The Nature of Jobs Is Changing As The Knowledge Economy RisesDocument16 pages1) The Nature of Jobs Is Changing As The Knowledge Economy Risesmeh3rePas encore d'évaluation
- Deep Analytics Services - Ivosights 2021Document19 pagesDeep Analytics Services - Ivosights 2021Elga YulwardianPas encore d'évaluation
- Internet of Things: Iot Protocols - Unit - 2Document135 pagesInternet of Things: Iot Protocols - Unit - 2Manikanta RobbiPas encore d'évaluation
- 5 G Test BedDocument10 pages5 G Test BedAnkur AgarwalPas encore d'évaluation
- Kiosk ManualDocument39 pagesKiosk Manualezlink5Pas encore d'évaluation
- WAPT Generic CheckListDocument6 pagesWAPT Generic CheckListsamsungPas encore d'évaluation
- ITServices SOP OverallOperations2010 - Version1.3Document32 pagesITServices SOP OverallOperations2010 - Version1.3santsj78Pas encore d'évaluation
- Proposal No. Frame Agreement:: XXX/XX - XX.XXXX XX - XX.XXXXDocument3 pagesProposal No. Frame Agreement:: XXX/XX - XX.XXXX XX - XX.XXXXDicu AndreiPas encore d'évaluation
- Wireless Networks: Gates Institute of TechnologyDocument13 pagesWireless Networks: Gates Institute of TechnologyShaik AllabakashPas encore d'évaluation
- Olympic InnovationDocument40 pagesOlympic InnovationBBVA Innovation CenterPas encore d'évaluation
- USSD and SMS Market Review Short Final ReportDocument43 pagesUSSD and SMS Market Review Short Final Reportunknown4080Pas encore d'évaluation
- Strategic Management - Modified Maps - Coloured - February 2020Document11 pagesStrategic Management - Modified Maps - Coloured - February 2020ahmedgelixPas encore d'évaluation
- Calculate, Communicate and Compare Your Cyber Exposure Key BenefitsDocument2 pagesCalculate, Communicate and Compare Your Cyber Exposure Key BenefitsSantiago HuilcamaiguaPas encore d'évaluation
- Understanding Cloud ComputingDocument14 pagesUnderstanding Cloud ComputingPawanPas encore d'évaluation
- Cloud Computing: Helping Financial Institutions Leverage The Cloud To Improve IT EfficiencyDocument15 pagesCloud Computing: Helping Financial Institutions Leverage The Cloud To Improve IT EfficiencyIBMBankingPas encore d'évaluation
- Next Generation Library and Information Services Strategy 2012-2015Document19 pagesNext Generation Library and Information Services Strategy 2012-2015Phyllis StephenPas encore d'évaluation
- Dhrubajit Das's ProjectDocument27 pagesDhrubajit Das's ProjectAnonymous 4MXnnF0NZbPas encore d'évaluation
- 7code PresentationDocument14 pages7code PresentationNicuMardariPas encore d'évaluation
- NIST Cloud Computing Reference Architecture PDFDocument35 pagesNIST Cloud Computing Reference Architecture PDFoswaldofarithPas encore d'évaluation
- IT Sector NewDocument29 pagesIT Sector NewShashank KumarPas encore d'évaluation
- Smart Home: Technology Solutions For Smart BuildingsDocument31 pagesSmart Home: Technology Solutions For Smart Buildingsb01eru84Pas encore d'évaluation
- 4IT As A ServiceDocument2 pages4IT As A ServicerohitPas encore d'évaluation
- How Using Iot Helps To Form Heterogeneous Long and Short-Range Networks For Sensing and Asset TrackingDocument9 pagesHow Using Iot Helps To Form Heterogeneous Long and Short-Range Networks For Sensing and Asset TrackingParesh PatelPas encore d'évaluation
- Common DDoS AttacksDocument6 pagesCommon DDoS AttacksregabriPas encore d'évaluation
- 2015 Hfs Blueprint Iot Services 2015Document56 pages2015 Hfs Blueprint Iot Services 2015Joca Tartuf Emeritus100% (1)
- The State of Dark Data ReportDocument28 pagesThe State of Dark Data ReportgkpalokPas encore d'évaluation
- Comtec IT Infrastructure 2012Document12 pagesComtec IT Infrastructure 2012Paddy BukkettPas encore d'évaluation
- 50 Email Security Best PracticesDocument17 pages50 Email Security Best Practicesjames smithPas encore d'évaluation
- Big Data in Telecommunication OperDocument14 pagesBig Data in Telecommunication OperSHASHIKANTPas encore d'évaluation
- A Study On Big Data Processing Mechanism & Applicability: Byung-Tae Chun and Seong-Hoon LeeDocument10 pagesA Study On Big Data Processing Mechanism & Applicability: Byung-Tae Chun and Seong-Hoon LeeVladimir Calle MayserPas encore d'évaluation
- 2015 Sentiment Analysis of Twitter Data Within Big Data DistributedDocument6 pages2015 Sentiment Analysis of Twitter Data Within Big Data DistributedDeepa BoobalakrishnanPas encore d'évaluation
- Fundamentals of Big Data JUNE 2022Document11 pagesFundamentals of Big Data JUNE 2022Rajni KumariPas encore d'évaluation
- 4 Roychoudhury KulkarniDocument4 pages4 Roychoudhury KulkarniArindam BanerjeePas encore d'évaluation
- 1 Foreword: TerminologyDocument6 pages1 Foreword: TerminologyManikandan K KrishnankuttyPas encore d'évaluation
- Development Framework For Mobile Social Applications: (Despindler, Grossniklaus, Norrie) @inf - Ethz.chDocument15 pagesDevelopment Framework For Mobile Social Applications: (Despindler, Grossniklaus, Norrie) @inf - Ethz.chهيدايو کامارودينPas encore d'évaluation
- Service Level Comparison For Online Shopping Using Data MiningDocument4 pagesService Level Comparison For Online Shopping Using Data MiningIIR indiaPas encore d'évaluation
- Big Data Technology in ConstructionDocument6 pagesBig Data Technology in Constructionsawaf fasaluPas encore d'évaluation
- Exploration On Big Data Oriented Data Analyzing and Processing TechnologyDocument7 pagesExploration On Big Data Oriented Data Analyzing and Processing TechnologyRookie VishwakantPas encore d'évaluation
- 10 Strategic Technological Trends in 2019Document10 pages10 Strategic Technological Trends in 2019Fatma El Zahraa IsmailPas encore d'évaluation
- Growing Smart Cities On An Open-Data-Centric Cyber-Physical PlatformDocument6 pagesGrowing Smart Cities On An Open-Data-Centric Cyber-Physical Platformgonzalo lopezPas encore d'évaluation
- Facebook Crawler As Software Agent For Business Intelligence SystemDocument22 pagesFacebook Crawler As Software Agent For Business Intelligence SystemErickPas encore d'évaluation
- Exploiting Rich Telecom Data For Increased Monetization of Telecom Application StoresDocument6 pagesExploiting Rich Telecom Data For Increased Monetization of Telecom Application Storeszaib29Pas encore d'évaluation
- ATEKO Et Al DEVELOPMENT OF A NEWS DROID AND EVENT REPORTING SYSTEMDocument7 pagesATEKO Et Al DEVELOPMENT OF A NEWS DROID AND EVENT REPORTING SYSTEMBusayo AtekoPas encore d'évaluation
- Mobile 3.0 Mobile Enterprise Application DevelopmentDocument14 pagesMobile 3.0 Mobile Enterprise Application DevelopmentgradybizPas encore d'évaluation
- Ecommendation System For Information Services Adapted Over Terrestrial Digital TelevisionDocument13 pagesEcommendation System For Information Services Adapted Over Terrestrial Digital TelevisioncseijPas encore d'évaluation
- M2M To Iot: 2180709 Prof - Dharmesh G PatelDocument40 pagesM2M To Iot: 2180709 Prof - Dharmesh G PatelTapan ShahPas encore d'évaluation
- Big Data, Cloud Computing, and Mobile TrafficDocument12 pagesBig Data, Cloud Computing, and Mobile TrafficRV devPas encore d'évaluation
- A Novel Big Data Analytics Framework For Smart CitiesDocument30 pagesA Novel Big Data Analytics Framework For Smart Citieseng.emanahmed2014Pas encore d'évaluation
- Automotive Big DataDocument10 pagesAutomotive Big DataravigobiPas encore d'évaluation
- Concept of Delivery System in The Smart City EnvironmentDocument16 pagesConcept of Delivery System in The Smart City EnvironmentJames MorenoPas encore d'évaluation
- Big Data ChallengesDocument10 pagesBig Data ChallengessvuhariPas encore d'évaluation
- Engineering Journal Towards A Framework For Executives and Decision Makers To Discriminate Big Data Projects For International DevelopmentDocument5 pagesEngineering Journal Towards A Framework For Executives and Decision Makers To Discriminate Big Data Projects For International DevelopmentEngineering JournalPas encore d'évaluation
- Raja Sharan CloudDocument6 pagesRaja Sharan CloudRaju PatnaPas encore d'évaluation
- Design of The Low-Cost Business Intelligence System Based On Multi-AgentDocument4 pagesDesign of The Low-Cost Business Intelligence System Based On Multi-AgentShree Krishna ShresthaPas encore d'évaluation
- 2017-AME ProblemsDocument42 pages2017-AME ProblemsJordan YapPas encore d'évaluation
- CGHS FormDocument3 pagesCGHS FormHarpreet SinghPas encore d'évaluation
- Business Proposal SVG BankDocument11 pagesBusiness Proposal SVG BankMd Sazzad KhanPas encore d'évaluation
- GSM Modem PDFDocument2 pagesGSM Modem PDFFalling SkiesPas encore d'évaluation
- New Guide - Stereo To 5-Channel Surround - 2004-05-01 PDFDocument383 pagesNew Guide - Stereo To 5-Channel Surround - 2004-05-01 PDFVisancio Jesús Abreu DelgadoPas encore d'évaluation
- 4th Term PLC Lab ManualDocument8 pages4th Term PLC Lab ManualOPIYO ONYANGOPas encore d'évaluation
- Aris Vs NLRCDocument3 pagesAris Vs NLRCgmelbertmPas encore d'évaluation
- The Revenue CycleDocument36 pagesThe Revenue CycleGerlyn Dasalla ClaorPas encore d'évaluation
- Week 10 - Monitoring and Auditing AIS - PresentationDocument32 pagesWeek 10 - Monitoring and Auditing AIS - PresentationChristian Gundran DiamsePas encore d'évaluation
- Pro Net On Amazon Web Services Guidance and Best Practices For Building and Deployment 1St Edition William Penberthy 2 Full Download ChapterDocument52 pagesPro Net On Amazon Web Services Guidance and Best Practices For Building and Deployment 1St Edition William Penberthy 2 Full Download Chapterraymond.fryar721100% (19)
- Marketing Research ProposalDocument42 pagesMarketing Research ProposalFahmida HaquePas encore d'évaluation
- Oh, What A Day! - Barney Wiki - FandomDocument4 pagesOh, What A Day! - Barney Wiki - FandomchefchadsmithPas encore d'évaluation
- Jurnal Keselamatan Kerja Di LabDocument7 pagesJurnal Keselamatan Kerja Di LabNisa NisaPas encore d'évaluation
- Green Steel AssuranceDocument6 pagesGreen Steel AssuranceRajat SinghPas encore d'évaluation
- BT Roads Sanctioned Under CRR Grant - Telangana State Go MS No 36Document56 pagesBT Roads Sanctioned Under CRR Grant - Telangana State Go MS No 36Srinivas P100% (2)
- Internal Audit & Corporate GovernanceDocument37 pagesInternal Audit & Corporate Governancezlkbelay@yahhoo.com100% (20)
- Insurance Services - Types of Insurers and Marketing SystemDocument44 pagesInsurance Services - Types of Insurers and Marketing SystemnineeshkkPas encore d'évaluation
- Bic Sodio Tongbai Malan MSDSDocument7 pagesBic Sodio Tongbai Malan MSDSFIORELLA VANESSA MAITA MUCHAPas encore d'évaluation
- Disk Cleanup PDFDocument3 pagesDisk Cleanup PDFMohammed Abdul MajeedPas encore d'évaluation
- VARIOline DS Brochure 2462-V1 en Original 44228Document16 pagesVARIOline DS Brochure 2462-V1 en Original 44228Kashif Xahir KhanPas encore d'évaluation
- Stop Order NoticeDocument2 pagesStop Order Noticeapi-37083620% (2)
- H61MGV3 20200405Document4 pagesH61MGV3 20200405Baskoro WidiatmokoPas encore d'évaluation
- Chloride Attack On Stainless SteelDocument7 pagesChloride Attack On Stainless Steelpravin_koyyanaPas encore d'évaluation
- Zebrafish Poster Portrait Eupfi Sep 2106 Final SubmittedDocument1 pageZebrafish Poster Portrait Eupfi Sep 2106 Final Submittedapi-266268510Pas encore d'évaluation
- VSphere Troubleshooting and TricksDocument46 pagesVSphere Troubleshooting and TricksManoj KumarPas encore d'évaluation
- Audit Project - Statutory AuditDocument2 pagesAudit Project - Statutory AuditWessa7Pas encore d'évaluation
- CSWIP Welding Inspection Notes and QuestionsDocument132 pagesCSWIP Welding Inspection Notes and QuestionsfahreezPas encore d'évaluation
- Organizational Behavior 3 0 1st Edition Bauer Test BankDocument30 pagesOrganizational Behavior 3 0 1st Edition Bauer Test BankBryanHensleyyaixg100% (9)
- Readme v9.522Document6 pagesReadme v9.522RTampubolonPas encore d'évaluation
- FX200 - Software Guide - EN - V01 - 2022.10.11-GDocument20 pagesFX200 - Software Guide - EN - V01 - 2022.10.11-GAngel FloresPas encore d'évaluation