Vous aimerez peut-être aussi
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (400)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (345)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (74)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (121)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- PE Range Moulded Case Current Transformers: Energy DivisionDocument7 pagesPE Range Moulded Case Current Transformers: Energy DivisionUlfran MedinaPas encore d'évaluation
- A Comparison of Pharmaceutical Promotional Tactics Between HK & ChinaDocument10 pagesA Comparison of Pharmaceutical Promotional Tactics Between HK & ChinaAlfred LeungPas encore d'évaluation
- Minor Project Report Format MCADocument11 pagesMinor Project Report Format MCAAnurag AroraPas encore d'évaluation
- Bank Statement SampleDocument6 pagesBank Statement SampleRovern Keith Oro CuencaPas encore d'évaluation
- OrganometallicsDocument53 pagesOrganometallicsSaman KadambPas encore d'évaluation
- Pro Tools ShortcutsDocument5 pagesPro Tools ShortcutsSteveJones100% (1)
- KrauseDocument3 pagesKrauseVasile CuprianPas encore d'évaluation
- FBW Manual-Jan 2012-Revised and Corrected CS2Document68 pagesFBW Manual-Jan 2012-Revised and Corrected CS2Dinesh CandassamyPas encore d'évaluation
- Heat TreatmentsDocument14 pagesHeat Treatmentsravishankar100% (1)
- ISP Flash Microcontroller Programmer Ver 3.0: M Asim KhanDocument4 pagesISP Flash Microcontroller Programmer Ver 3.0: M Asim KhanSrđan PavićPas encore d'évaluation
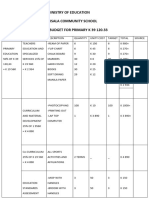
- Ministry of Education Musala SCHDocument5 pagesMinistry of Education Musala SCHlaonimosesPas encore d'évaluation
- Sony SL HF-900 Owners ManualDocument53 pagesSony SL HF-900 Owners ManualThomas Christoph100% (1)
- Sciencedirect: Jad Imseitif, He Tang, Mike Smith Jad Imseitif, He Tang, Mike SmithDocument10 pagesSciencedirect: Jad Imseitif, He Tang, Mike Smith Jad Imseitif, He Tang, Mike SmithTushar singhPas encore d'évaluation
- Project Job Number EngineerDocument2 pagesProject Job Number Engineertekno plus banatPas encore d'évaluation
- Understanding Consumer and Business Buyer BehaviorDocument47 pagesUnderstanding Consumer and Business Buyer BehaviorJia LePas encore d'évaluation
- TP1743 - Kertas 1 Dan 2 Peperiksaan Percubaan SPM Sains 2023-20243Document12 pagesTP1743 - Kertas 1 Dan 2 Peperiksaan Percubaan SPM Sains 2023-20243Felix ChewPas encore d'évaluation
- Proposal For Chemical Shed at Keraniganj - 15.04.21Document14 pagesProposal For Chemical Shed at Keraniganj - 15.04.21HabibPas encore d'évaluation
- MSA Chair's Report 2012Document56 pagesMSA Chair's Report 2012Imaad IsaacsPas encore d'évaluation
- Powerpoint Presentation R.A 7877 - Anti Sexual Harassment ActDocument14 pagesPowerpoint Presentation R.A 7877 - Anti Sexual Harassment ActApple100% (1)
- Ficha Tecnica 320D3 GCDocument12 pagesFicha Tecnica 320D3 GCanahdezj88Pas encore d'évaluation
- Durga Padma Sai SatishDocument1 pageDurga Padma Sai SatishBhaskar Siva KumarPas encore d'évaluation
- Different Software Life Cycle Models: Mini Project OnDocument11 pagesDifferent Software Life Cycle Models: Mini Project OnSagar MurtyPas encore d'évaluation
- Sacmi Vol 2 Inglese - II EdizioneDocument416 pagesSacmi Vol 2 Inglese - II Edizionecuibaprau100% (21)
- Item Description RCVD Unit Price Gross Amt Disc % Ta Amount DeptDocument1 pageItem Description RCVD Unit Price Gross Amt Disc % Ta Amount DeptGustu LiranPas encore d'évaluation
- United States v. Manuel Sosa, 959 F.2d 232, 4th Cir. (1992)Document2 pagesUnited States v. Manuel Sosa, 959 F.2d 232, 4th Cir. (1992)Scribd Government DocsPas encore d'évaluation
- Tindara Addabbo, Edoardo Ales, Ylenia Curzi, Tommaso Fabbri, Olga Rymkevich, Iacopo Senatori - Performance Appraisal in Modern Employment Relations_ An Interdisciplinary Approach-Springer Internationa.pdfDocument278 pagesTindara Addabbo, Edoardo Ales, Ylenia Curzi, Tommaso Fabbri, Olga Rymkevich, Iacopo Senatori - Performance Appraisal in Modern Employment Relations_ An Interdisciplinary Approach-Springer Internationa.pdfMario ChristopherPas encore d'évaluation
- The "Solid Mount": Installation InstructionsDocument1 pageThe "Solid Mount": Installation InstructionsCraig MathenyPas encore d'évaluation
- Beam Deflection by Double Integration MethodDocument21 pagesBeam Deflection by Double Integration MethodDanielle Ruthie GalitPas encore d'évaluation
- UCAT SJT Cheat SheetDocument3 pagesUCAT SJT Cheat Sheetmatthewgao78Pas encore d'évaluation
- Is.14785.2000 - Coast Down Test PDFDocument12 pagesIs.14785.2000 - Coast Down Test PDFVenkata NarayanaPas encore d'évaluation