Vous aimerez peut-être aussi
- Public Opinion, Campaign Politics & Media Audiences: New Australian PerspectivesD'EverandPublic Opinion, Campaign Politics & Media Audiences: New Australian PerspectivesPas encore d'évaluation
- The Formula: Game Changing Strategies from Everyday Experts, Volume 2D'EverandThe Formula: Game Changing Strategies from Everyday Experts, Volume 2Pas encore d'évaluation
- Research Methods in Sign Language Studies: A Practical GuideD'EverandResearch Methods in Sign Language Studies: A Practical GuideÉvaluation : 3 sur 5 étoiles3/5 (1)
- News as Culture: Journalistic Practices and the Remaking of Indian Leadership TraditionsD'EverandNews as Culture: Journalistic Practices and the Remaking of Indian Leadership TraditionsPas encore d'évaluation
- Computer Assisted Learning: Selected Proceedings from the CAL 81 Symposium, University of Leeds, 8-10 April 1981D'EverandComputer Assisted Learning: Selected Proceedings from the CAL 81 Symposium, University of Leeds, 8-10 April 1981Évaluation : 5 sur 5 étoiles5/5 (2)
- CSR Corporate Social Responsibility A Complete Guide - 2021 EditionD'EverandCSR Corporate Social Responsibility A Complete Guide - 2021 EditionPas encore d'évaluation
- Media Ethics and Regulation: Insights from AfricaD'EverandMedia Ethics and Regulation: Insights from AfricaPas encore d'évaluation
- The Total Survey Error Approach: A Guide to the New Science of Survey ResearchD'EverandThe Total Survey Error Approach: A Guide to the New Science of Survey ResearchPas encore d'évaluation
- The Business of Innovation: Managing the Corporate Imagination for Maximum ResultsD'EverandThe Business of Innovation: Managing the Corporate Imagination for Maximum ResultsPas encore d'évaluation
- Journalism shrinks, power expands: The second death of public opinionD'EverandJournalism shrinks, power expands: The second death of public opinionPas encore d'évaluation
- Semi Structured Data A Complete Guide - 2020 EditionD'EverandSemi Structured Data A Complete Guide - 2020 EditionPas encore d'évaluation
- Soft News Goes to War: Public Opinion and American Foreign Policy in the New Media AgeD'EverandSoft News Goes to War: Public Opinion and American Foreign Policy in the New Media AgeÉvaluation : 3.5 sur 5 étoiles3.5/5 (2)
- Perspective on Analytical Writing a Focus on Feature and Editorial WritingD'EverandPerspective on Analytical Writing a Focus on Feature and Editorial WritingPas encore d'évaluation
- Prospectus Discussion Notes 33 Ppgs UploadDocument33 pagesProspectus Discussion Notes 33 Ppgs UploadAngela Baker100% (1)
- Tough Love - Power, Culture and Diversity In Negotiations, Mediation & Conflict ResolutionD'EverandTough Love - Power, Culture and Diversity In Negotiations, Mediation & Conflict ResolutionPas encore d'évaluation
- Topological Data Analysis A Complete Guide - 2020 EditionD'EverandTopological Data Analysis A Complete Guide - 2020 EditionPas encore d'évaluation
- The IABC Handbook of Organizational Communication: A Guide to Internal Communication, Public Relations, Marketing, and LeadershipD'EverandThe IABC Handbook of Organizational Communication: A Guide to Internal Communication, Public Relations, Marketing, and LeadershipPas encore d'évaluation
- Tourism Sector Assessment, Strategy, and Road Map for Cambodia, Lao People's Democratic Republic, Myanmar, and Viet Nam (2016-2018)D'EverandTourism Sector Assessment, Strategy, and Road Map for Cambodia, Lao People's Democratic Republic, Myanmar, and Viet Nam (2016-2018)Pas encore d'évaluation
- Plagiarism and Detection Tools: An OverviewDocument6 pagesPlagiarism and Detection Tools: An OverviewResearch Cell: An International Journal of Engineering SciencesPas encore d'évaluation
- Virtual Learning Environment A Complete Guide - 2020 EditionD'EverandVirtual Learning Environment A Complete Guide - 2020 EditionPas encore d'évaluation
- Environmental Finance: A Blueprint for a Sustainable FutureD'EverandEnvironmental Finance: A Blueprint for a Sustainable FuturePas encore d'évaluation
- Social Network Sites for Scientists: A Quantitative SurveyD'EverandSocial Network Sites for Scientists: A Quantitative SurveyPas encore d'évaluation
- The International Health Regulations (IHR) Components of Communication During CrisisDocument1 pageThe International Health Regulations (IHR) Components of Communication During CrisisOWADUGE, StevePas encore d'évaluation
- From Algorithms To Stories.Document49 pagesFrom Algorithms To Stories.Jonathan StrayPas encore d'évaluation
- Public Safety Dispatcher, CHP: Passbooks Study GuideD'EverandPublic Safety Dispatcher, CHP: Passbooks Study GuidePas encore d'évaluation
- Doctoral Students: Attrition, Retention Rates, Motivation, and Financial Constraints: A Comprehensive Research Guide in Helping Graduate School Students Completing Doctoral ProgramsD'EverandDoctoral Students: Attrition, Retention Rates, Motivation, and Financial Constraints: A Comprehensive Research Guide in Helping Graduate School Students Completing Doctoral ProgramsPas encore d'évaluation
- Applying Your Tools to Real-Life Examples: Part II: The Power of Writing WellD'EverandApplying Your Tools to Real-Life Examples: Part II: The Power of Writing WellPas encore d'évaluation
- The Computation of Style: An Introduction to Statistics for Students of Literature and HumanitiesD'EverandThe Computation of Style: An Introduction to Statistics for Students of Literature and HumanitiesPas encore d'évaluation
- Points of Departure: Rethinking Student Source Use and Writing Studies Research MethodsD'EverandPoints of Departure: Rethinking Student Source Use and Writing Studies Research MethodsTricia ServissPas encore d'évaluation
- Language: Social Psychological Perspectives: Selected Papers from the First International Conference on Social Psychology and Language held at the University of Bristol, England, July 1979D'EverandLanguage: Social Psychological Perspectives: Selected Papers from the First International Conference on Social Psychology and Language held at the University of Bristol, England, July 1979Pas encore d'évaluation
- White City OMA AMO ARUP-whitecity01Document46 pagesWhite City OMA AMO ARUP-whitecity01Xshan NnxPas encore d'évaluation
- Kengo Kuma & AssociatesDocument118 pagesKengo Kuma & AssociatesXshan NnxPas encore d'évaluation
- Philosophy Sessional - Urban (Le Corbusier)Document16 pagesPhilosophy Sessional - Urban (Le Corbusier)Xshan NnxPas encore d'évaluation
- District Profile Report SwatDocument31 pagesDistrict Profile Report SwatXshan NnxPas encore d'évaluation
- Pride of Pakistan Nayyar Ali DadaDocument6 pagesPride of Pakistan Nayyar Ali DadaXshan Nnx100% (1)
- DEMOGRAPHIC Analysis of AbbottabadDocument21 pagesDEMOGRAPHIC Analysis of AbbottabadXshan NnxPas encore d'évaluation
- Vocabulary For TOEFL iBTDocument191 pagesVocabulary For TOEFL iBTquevinh94% (48)
- AudioCodes 400HD IP Phones PDFDocument2 pagesAudioCodes 400HD IP Phones PDFalsvrjPas encore d'évaluation
- Using Sockets in PHPDocument7 pagesUsing Sockets in PHPJaNoLeRRoPas encore d'évaluation
- Combined Structural and Piping Analysis Methodology - ANSYSDocument45 pagesCombined Structural and Piping Analysis Methodology - ANSYS2challengersPas encore d'évaluation
- V1000 Programming Manual OYMC 070808Document408 pagesV1000 Programming Manual OYMC 070808circlelinePas encore d'évaluation
- Piping Codes (41-45)Document42 pagesPiping Codes (41-45)Brenda Davis100% (2)
- AS400 Command ListDocument56 pagesAS400 Command ListRandy KoellerPas encore d'évaluation
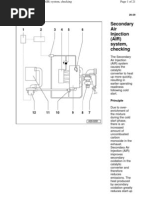
- Audi TT Sec AirDocument21 pagesAudi TT Sec Airdonghungco080% (1)
- Web Services Principles and TechnologyDocument785 pagesWeb Services Principles and TechnologyHira IshaquePas encore d'évaluation
- Track-Type Tractor: XL & LGPDocument20 pagesTrack-Type Tractor: XL & LGPRoussel Florez Zuloaga100% (3)
- Informatica Interview QuestionsDocument11 pagesInformatica Interview Questionsmurari_0454168100% (1)
- Catálogo de Bujias BoschDocument4 pagesCatálogo de Bujias BoschRodrigo Vidal EscrivàPas encore d'évaluation
- AA 3350 Thermal Window: Enhance Your Views With Exceptional Value and PerformanceDocument2 pagesAA 3350 Thermal Window: Enhance Your Views With Exceptional Value and PerformanceMandi MorrisPas encore d'évaluation
- PTA StandardsDocument2 pagesPTA Standardsanamq1Pas encore d'évaluation
- Curriculum Vitae: Career ObjectiveDocument4 pagesCurriculum Vitae: Career ObjectivePrashant KumarPas encore d'évaluation
- Відповіді до ЄвчукDocument8 pagesВідповіді до ЄвчукAnastasijaPas encore d'évaluation
- Essential Practice Books PDFDocument8 pagesEssential Practice Books PDFgskodikara20000% (1)
- SPAC265-3W: AC-DC Switch Mode Power SupplyDocument12 pagesSPAC265-3W: AC-DC Switch Mode Power SupplyradugaPas encore d'évaluation
- ChargersDocument30 pagesChargersDragan100% (1)
- ZTE CRBT SpecificationsDocument10 pagesZTE CRBT SpecificationsMirza Zaheer AhmedPas encore d'évaluation
- Rdbms Lab Manual New SchemeDocument24 pagesRdbms Lab Manual New SchemeSudeep SharmaPas encore d'évaluation
- Fab A: Cpu: System Chipset: Main Memory: On Board DeviceDocument46 pagesFab A: Cpu: System Chipset: Main Memory: On Board DeviceFlavianoSilva100% (1)
- Zte Bts Zxg10Document45 pagesZte Bts Zxg10Yadav Mahesh100% (1)
- En 583-1-1999 PDFDocument14 pagesEn 583-1-1999 PDFNav TalukdarPas encore d'évaluation
- ISO Management Systems Standards 1Document16 pagesISO Management Systems Standards 1John Paul TocolPas encore d'évaluation
- Certificate of Conformance: " Screw Pin ShacklesDocument3 pagesCertificate of Conformance: " Screw Pin ShacklesEMIGDIO RODRIGUEZ IZQUIERDOPas encore d'évaluation
- Motorola 4.4 CLI Reference PDFDocument826 pagesMotorola 4.4 CLI Reference PDFGeorge FărcașPas encore d'évaluation
- Magnification SystemsDocument8 pagesMagnification Systemsgalal2720006810Pas encore d'évaluation
- Ddoocp Ms March2012 FinalDocument11 pagesDdoocp Ms March2012 FinalSarge ChisangaPas encore d'évaluation
- Monico Gen. 2 Gateway DatasheetDocument2 pagesMonico Gen. 2 Gateway DatasheetDavid BaranyaiPas encore d'évaluation
- Utilisation Du RB500 en PDFDocument3 pagesUtilisation Du RB500 en PDFAmro HassaninPas encore d'évaluation