Vous aimerez peut-être aussi
- CapmDocument3 pagesCapmkhabiranPas encore d'évaluation
- Dio 22b. Sprečavanje Onečišćenja - Izmjene Jan 2021Document5 pagesDio 22b. Sprečavanje Onečišćenja - Izmjene Jan 2021Samo SpontanostPas encore d'évaluation
- Ocean Internet-of-Things // Networked Blue Economy: C-Accel Track RecommendationDocument12 pagesOcean Internet-of-Things // Networked Blue Economy: C-Accel Track RecommendationkhabiranPas encore d'évaluation
- DavorinDujmovic PaperDavorinDujmovicDocument10 pagesDavorinDujmovic PaperDavorinDujmovickhabiranPas encore d'évaluation
- No. F-14-AAA-0000Document9 pagesNo. F-14-AAA-0000khabiranPas encore d'évaluation
- Landmark Facility Solutions - QuestionsDocument1 pageLandmark Facility Solutions - QuestionsFaig0% (1)
- Quiz - Exercise - Mini-Case Instructions InstructionsDocument1 pageQuiz - Exercise - Mini-Case Instructions InstructionskhabiranPas encore d'évaluation
- HjlinjftsaiDocument13 pagesHjlinjftsaikhabiranPas encore d'évaluation
- Review of Charterer and Owner Relationship PDFDocument15 pagesReview of Charterer and Owner Relationship PDFShanti Prakhar AwasthiPas encore d'évaluation
- ICS Rules & Regulations and GuidanceDocument2 pagesICS Rules & Regulations and GuidancekhabiranPas encore d'évaluation
- Customer Value Chain Analysis For Sustainable Reverse Logistics Implementation: Indonesian Mobile Phone IndustryDocument4 pagesCustomer Value Chain Analysis For Sustainable Reverse Logistics Implementation: Indonesian Mobile Phone IndustrykhabiranPas encore d'évaluation
- United Nations Industrial Development Organization: Single Workstation - Comfar Iii ExpertDocument1 pageUnited Nations Industrial Development Organization: Single Workstation - Comfar Iii ExpertkhabiranPas encore d'évaluation
- Customer Value Chain Analysis For Sustainable Reverse Logistics Implementation: Indonesian Mobile Phone IndustryDocument4 pagesCustomer Value Chain Analysis For Sustainable Reverse Logistics Implementation: Indonesian Mobile Phone IndustrykhabiranPas encore d'évaluation
- Overview of Health, Safety and Environmental Regulation Relating To The Offshore Oil and Gas IndustryDocument16 pagesOverview of Health, Safety and Environmental Regulation Relating To The Offshore Oil and Gas IndustrykhabiranPas encore d'évaluation
- Shell Corrosion Allowance For Aboveground Storage Tanks: Debra Tetteh-Wayoe, P.EngDocument8 pagesShell Corrosion Allowance For Aboveground Storage Tanks: Debra Tetteh-Wayoe, P.Engkhabiran100% (1)
- 20120710ATT48612EN OriginalDocument16 pages20120710ATT48612EN OriginalkhabiranPas encore d'évaluation
- Project Management & Engineering Services To The Submarine Power Cable MarketDocument2 pagesProject Management & Engineering Services To The Submarine Power Cable MarketkhabiranPas encore d'évaluation
- Numerical Simulation of Fluid Added Mass Effect On A Kaplan Turbine Runner With Experimental ValidationDocument9 pagesNumerical Simulation of Fluid Added Mass Effect On A Kaplan Turbine Runner With Experimental ValidationkhabiranPas encore d'évaluation
- DNV GL Adv DP Verfication BC 3 2017Document1 pageDNV GL Adv DP Verfication BC 3 2017khabiranPas encore d'évaluation
- Marine Safety Management Plan: Kendall Bay Sediment Remediation ProjectDocument37 pagesMarine Safety Management Plan: Kendall Bay Sediment Remediation Projectkhabiran100% (1)
- A Brief Review On Ndt&E Methods For Structural Aircraft ComponentsDocument9 pagesA Brief Review On Ndt&E Methods For Structural Aircraft ComponentskhabiranPas encore d'évaluation
- Shell Corrosion Allowance For Aboveground Storage Tanks: Debra Tetteh-Wayoe, P.EngDocument8 pagesShell Corrosion Allowance For Aboveground Storage Tanks: Debra Tetteh-Wayoe, P.Engkhabiran100% (1)
- A Brief Review On Ndt&E Methods For Structural Aircraft ComponentsDocument9 pagesA Brief Review On Ndt&E Methods For Structural Aircraft ComponentskhabiranPas encore d'évaluation
- Nonlinear Analysis of Offshore Structures: Bjo RN Skallerud Jo Rgen AmdahlDocument1 pageNonlinear Analysis of Offshore Structures: Bjo RN Skallerud Jo Rgen AmdahlkhabiranPas encore d'évaluation
- On Design, Modelling, and Analysis of A 10-MW Medium-Speed Drivetrain For Offshore Wind TurbinesDocument1 pageOn Design, Modelling, and Analysis of A 10-MW Medium-Speed Drivetrain For Offshore Wind TurbineskhabiranPas encore d'évaluation
- Smallseotools 1617464053Document1 pageSmallseotools 1617464053khabiranPas encore d'évaluation
- Service Note: ABB Solar Inverter Life Cycle ManagementDocument2 pagesService Note: ABB Solar Inverter Life Cycle ManagementkhabiranPas encore d'évaluation
- Orcaflex Standard Training Course Syllabus: Line TypesDocument3 pagesOrcaflex Standard Training Course Syllabus: Line TypeskhabiranPas encore d'évaluation
- Innovatum Tone GeneratorDocument8 pagesInnovatum Tone GeneratorGleison PrateadoPas encore d'évaluation
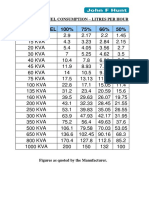
- Average Fuel ConsumptionDocument1 pageAverage Fuel ConsumptionkhabiranPas encore d'évaluation
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (121)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- Project Appendix ADocument16 pagesProject Appendix ASumit KPas encore d'évaluation
- BOLTCALC Is A Specialised Computer ProgramDocument2 pagesBOLTCALC Is A Specialised Computer ProgramAndi BagusPas encore d'évaluation
- AWS Certified Cloud Practitioner Exam - Free Actual Q&As, Page 14 - ExamTopicsDocument2 pagesAWS Certified Cloud Practitioner Exam - Free Actual Q&As, Page 14 - ExamTopicsParag Anil WaniPas encore d'évaluation
- SST Tech Female Model PaperDocument6 pagesSST Tech Female Model PaperNoman ShahPas encore d'évaluation
- Tech Note 1010 - SQL Server Authentication and ArchestrA Network Account Restrictions When Installing Wonderware HistorianDocument8 pagesTech Note 1010 - SQL Server Authentication and ArchestrA Network Account Restrictions When Installing Wonderware Historianprofilemail8Pas encore d'évaluation
- Software Development Guidelines PDFDocument31 pagesSoftware Development Guidelines PDFadeelkhan09Pas encore d'évaluation
- Synopsis: KCES's College of Engineering and Management, JalgaonDocument4 pagesSynopsis: KCES's College of Engineering and Management, JalgaonHitesh DhakePas encore d'évaluation
- ViciDocs Products Features PDFDocument9 pagesViciDocs Products Features PDFSai KumarPas encore d'évaluation
- AP254XINSTDocument194 pagesAP254XINSTovidiu0702Pas encore d'évaluation
- Tips & Tricks For The Success With Azure SQL Managed InstanceDocument41 pagesTips & Tricks For The Success With Azure SQL Managed InstanceDejan Tale MarkovicPas encore d'évaluation
- Product Sheet - Parsys Cloud - Parsys TelemedicineDocument10 pagesProduct Sheet - Parsys Cloud - Parsys TelemedicineChristian Lezama Cuellar100% (1)
- ComsabDocument2 pagesComsababuzer1981Pas encore d'évaluation
- Balancing Volume, Quality and Freshness in Web Crawling: Ricardo Baeza-Yates and Carlos CastilloDocument14 pagesBalancing Volume, Quality and Freshness in Web Crawling: Ricardo Baeza-Yates and Carlos CastilloABHI LIFEPas encore d'évaluation
- DWMS Implementation Case Study 3PLDocument26 pagesDWMS Implementation Case Study 3PLKCSPas encore d'évaluation
- NEX - Teamcenter Superuser Course Presentation - v06 PDFDocument298 pagesNEX - Teamcenter Superuser Course Presentation - v06 PDFcad cadPas encore d'évaluation
- Log Bitcoin Script 2020Document181 pagesLog Bitcoin Script 2020FACKER CHENNALPas encore d'évaluation
- CrontabDocument1 pageCrontabAthzumPas encore d'évaluation
- Cognizant Technology Solutions: Programmer AnalystDocument34 pagesCognizant Technology Solutions: Programmer AnalystVivek RaushanPas encore d'évaluation
- ArcSight Administration TrainigDocument47 pagesArcSight Administration TrainigPradeep KumarPas encore d'évaluation
- 61bdbfaee0419 - Cyber Crime by - Shyam Gopal TimsinaDocument30 pages61bdbfaee0419 - Cyber Crime by - Shyam Gopal TimsinaAnuska ThapaPas encore d'évaluation
- DBMS Assignment 1Document17 pagesDBMS Assignment 1Rohit ChavanPas encore d'évaluation
- B787 A G71!00!00 10B 520A A Engine (Bootstrap Method) - RemovalDocument61 pagesB787 A G71!00!00 10B 520A A Engine (Bootstrap Method) - Removaldonghuizhen2004Pas encore d'évaluation
- Log 20231012 114556Document440 pagesLog 20231012 114556Mayra OlivoPas encore d'évaluation
- Another - Lab - Get Started With Docker ComposeDocument6 pagesAnother - Lab - Get Started With Docker ComposeMed Aziz Ben HahaPas encore d'évaluation
- IT5T1Document2 pagesIT5T1Vyshnavi ThottempudiPas encore d'évaluation
- Project Title:: Online Lost & Found Management SystemDocument15 pagesProject Title:: Online Lost & Found Management SystemÄñí ÎmtìsaalPas encore d'évaluation
- Exotel Manual Get StartedDocument15 pagesExotel Manual Get StartedShekhar KumarPas encore d'évaluation
- Hypertext Markup Language (HTML) : Mendel RosenblumDocument22 pagesHypertext Markup Language (HTML) : Mendel RosenblumSh SamPas encore d'évaluation
- Tizen For DummiesDocument213 pagesTizen For DummiesLuisCriativo100% (2)