Vous aimerez peut-être aussi
- Stats Cheat SheetDocument3 pagesStats Cheat SheetEdriana Isabel Bougrat Fermin50% (4)
- Review QuestionsDocument9 pagesReview Questionsacr2944Pas encore d'évaluation
- Introduction To Statistical Learning: With Applications in RDocument13 pagesIntroduction To Statistical Learning: With Applications in RAnuar YeraliyevPas encore d'évaluation
- CH 3 Statistical EstimationDocument13 pagesCH 3 Statistical EstimationManchilot Tilahun100% (1)
- MODULE 7 Discrete Probability DistributionsDocument16 pagesMODULE 7 Discrete Probability DistributionsMini Cabalquinto33% (12)
- Enneagram Test With Instinctual Variant ResultsDocument2 pagesEnneagram Test With Instinctual Variant ResultsAmmarPlumberPas encore d'évaluation
- ISLRDocument9 pagesISLRAnuar YeraliyevPas encore d'évaluation
- CH 4 Multiple Regression ModelsDocument28 pagesCH 4 Multiple Regression Modelspkj009Pas encore d'évaluation
- Hypothesis TestingDocument23 pagesHypothesis TestingNidhiPas encore d'évaluation
- Insppt 6Document21 pagesInsppt 6Md Talha JavedPas encore d'évaluation
- Sas Notes Module 4-Categorical Data Analysis Testing Association Between Categorical VariablesDocument16 pagesSas Notes Module 4-Categorical Data Analysis Testing Association Between Categorical VariablesNISHITA MALPANI100% (1)
- Predective Analytics or Inferential StatisticsDocument27 pagesPredective Analytics or Inferential StatisticsMichaella PurgananPas encore d'évaluation
- STAT1301 Notes: Steps For Scientific StudyDocument31 pagesSTAT1301 Notes: Steps For Scientific StudyjohnPas encore d'évaluation
- Basic Statistics: Basic Statistical Interview QuestionDocument5 pagesBasic Statistics: Basic Statistical Interview QuestionDipti KamblePas encore d'évaluation
- Ordinary Least SquaresDocument21 pagesOrdinary Least SquaresRahulsinghooooPas encore d'évaluation
- Econometrics PracticalDocument13 pagesEconometrics Practicalakashit21a854Pas encore d'évaluation
- Probit Logit InterpretationDocument26 pagesProbit Logit InterpretationNomun Bukh-OchirPas encore d'évaluation
- Basic Regression AnalysisDocument5 pagesBasic Regression AnalysisAnantha VijayanPas encore d'évaluation
- Stat 473-573 NotesDocument139 pagesStat 473-573 NotesArkadiusz Michael BarPas encore d'évaluation
- ECONOMETRICSDocument4 pagesECONOMETRICSAlix MuratetPas encore d'évaluation
- Term End Examination: Descriptive Answer ScriptDocument5 pagesTerm End Examination: Descriptive Answer ScriptAbhishek ChoudharyPas encore d'évaluation
- AP Stats ReviewDocument16 pagesAP Stats ReviewJinhui ZhengPas encore d'évaluation
- P1.T2. Quantitative AnalysisDocument23 pagesP1.T2. Quantitative Analysisruthbadoo54Pas encore d'évaluation
- Simple Linear Regression and Correlation (Continue..,)Document30 pagesSimple Linear Regression and Correlation (Continue..,)Lan Anh BuiPas encore d'évaluation
- Chapter 3 NotesDocument5 pagesChapter 3 NotesPete Jacopo Belbo CayaPas encore d'évaluation
- Jimma University: M.SC in Economics (Industrial Economics) Regular Program Individual Assignment: EconometricsDocument20 pagesJimma University: M.SC in Economics (Industrial Economics) Regular Program Individual Assignment: Econometricsasu manPas encore d'évaluation
- Multicollinearity Assignment April 5Document10 pagesMulticollinearity Assignment April 5Zeinm KhenPas encore d'évaluation
- Multiple Linear Regression: y BX BX BXDocument14 pagesMultiple Linear Regression: y BX BX BXPalaniappan SellappanPas encore d'évaluation
- LogregDocument26 pagesLogregroy royPas encore d'évaluation
- CH II - Statistical EstimationsDocument17 pagesCH II - Statistical EstimationsadsbPas encore d'évaluation
- Summary of Previous Lecture Assumptions of CLRM Standard Error or Precision of Estimates Co VarianceDocument17 pagesSummary of Previous Lecture Assumptions of CLRM Standard Error or Precision of Estimates Co VarianceSheraz AhmedPas encore d'évaluation
- 9.1. Prob - StatsDocument19 pages9.1. Prob - StatsAnkit KabiPas encore d'évaluation
- SPSS Regression Spring 2010Document9 pagesSPSS Regression Spring 2010fuad_h05Pas encore d'évaluation
- ArunRangrejDocument5 pagesArunRangrejArun RangrejPas encore d'évaluation
- Instalinotes - PREVMED IIDocument24 pagesInstalinotes - PREVMED IIKenneth Cuballes100% (1)
- Multiple Linear Regression in Data MiningDocument14 pagesMultiple Linear Regression in Data Miningakirank1100% (1)
- ML Exam BHT Tough H BeeeeeeeeeDocument10 pagesML Exam BHT Tough H BeeeeeeeeeRasika DeshpandePas encore d'évaluation
- Econometrics: Two Variable Regression: The Problem of EstimationDocument28 pagesEconometrics: Two Variable Regression: The Problem of EstimationsajidalirafiquePas encore d'évaluation
- Psych Stat Reviewer MidtermsDocument10 pagesPsych Stat Reviewer MidtermsROSEFEL GARNETT AGORPas encore d'évaluation
- Regression and Multiple Regression AnalysisDocument21 pagesRegression and Multiple Regression AnalysisRaghu NayakPas encore d'évaluation
- Chapter Two: Bivariate Regression ModeDocument54 pagesChapter Two: Bivariate Regression ModenahomPas encore d'évaluation
- 5.multiple RegressionDocument17 pages5.multiple Regressionaiman irfanPas encore d'évaluation
- Lecture 6Document19 pagesLecture 6Shehzad AlumPas encore d'évaluation
- Statstic SlideDocument24 pagesStatstic SlideQATRUN NADIRA BINTI BAHARIN MoePas encore d'évaluation
- Data Science Interview PreparationDocument113 pagesData Science Interview PreparationReva V100% (1)
- Violations of OLSDocument64 pagesViolations of OLSOisín Ó CionaoithPas encore d'évaluation
- WelcomeDocument19 pagesWelcomeSharath sharuPas encore d'évaluation
- Number of Observations: It: Number of Variables Plus 1'. Here We Want To Estimate For 1 Variable Only, So Number ofDocument3 pagesNumber of Observations: It: Number of Variables Plus 1'. Here We Want To Estimate For 1 Variable Only, So Number ofQuynh Ngoc DangPas encore d'évaluation
- Data Science 03 - Regression PDFDocument32 pagesData Science 03 - Regression PDFlomeroaiaPas encore d'évaluation
- Serial Correlation:: ST STDocument7 pagesSerial Correlation:: ST STThyra Lindberg WysockiPas encore d'évaluation
- Bio2 Module 4 - Multiple Linear RegressionDocument20 pagesBio2 Module 4 - Multiple Linear Regressiontamirat hailuPas encore d'évaluation
- Basic - Statistics 30 Sep 2013 PDFDocument20 pagesBasic - Statistics 30 Sep 2013 PDFImam Zulkifli S100% (1)
- Level 2 Quants NotesDocument7 pagesLevel 2 Quants NotesMunna ChoudharyPas encore d'évaluation
- Interpret Standard Deviation Outlier Rule: Using Normalcdf and Invnorm (Calculator Tips)Document12 pagesInterpret Standard Deviation Outlier Rule: Using Normalcdf and Invnorm (Calculator Tips)maryrachel713Pas encore d'évaluation
- Question 4 (A) What Are The Stochastic Assumption of The Ordinary Least Squares? Assumption 1Document9 pagesQuestion 4 (A) What Are The Stochastic Assumption of The Ordinary Least Squares? Assumption 1yaqoob008Pas encore d'évaluation
- SMMDDocument10 pagesSMMDAnuj AgarwalPas encore d'évaluation
- Regression ANOVADocument42 pagesRegression ANOVAJamal AbdullahPas encore d'évaluation
- Dav Exp3 66Document4 pagesDav Exp3 66godizlatanPas encore d'évaluation
- Estadística Clase 7Document24 pagesEstadística Clase 7Andres GaortPas encore d'évaluation
- Amlfs Exp 1 ADocument6 pagesAmlfs Exp 1 Aojdsouza16Pas encore d'évaluation
- Schaum's Easy Outline of Probability and Statistics, Revised EditionD'EverandSchaum's Easy Outline of Probability and Statistics, Revised EditionPas encore d'évaluation
- Properties of Expected Values and Variance: Christopher CrokeDocument48 pagesProperties of Expected Values and Variance: Christopher CrokeYash VarunPas encore d'évaluation
- Fundamental Theories of PhysicsDocument881 pagesFundamental Theories of Physicscibercafejava100% (4)
- Basics of Hypothesis TestingDocument36 pagesBasics of Hypothesis TestingRoyal MechanicalPas encore d'évaluation
- The Standard Model of Quantum Physics in Clifford AlgebraDocument240 pagesThe Standard Model of Quantum Physics in Clifford AlgebraWalid ZiziPas encore d'évaluation
- Quantum Mechanics Notes-Part 2Document20 pagesQuantum Mechanics Notes-Part 2aman bhatiaPas encore d'évaluation
- Anderson TransitionsDocument63 pagesAnderson TransitionsDanang Suto WijoyoPas encore d'évaluation
- Addition of Angular MomentaDocument6 pagesAddition of Angular MomentajulanoPas encore d'évaluation
- Minimal Sufficient StatisticsDocument6 pagesMinimal Sufficient StatisticsneodrexPas encore d'évaluation
- Marxist Perspective On EducationDocument15 pagesMarxist Perspective On EducationMel BoochoonPas encore d'évaluation
- 2nd QTR PeTa 2Document4 pages2nd QTR PeTa 2Matthew Spencer HoPas encore d'évaluation
- Quiz - GRP ADocument2 pagesQuiz - GRP ASAURABH PANDEYPas encore d'évaluation
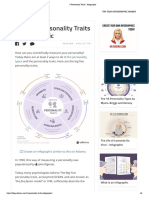
- Big Five Personality Traits - Infographic: LatestDocument6 pagesBig Five Personality Traits - Infographic: LatestsdPas encore d'évaluation
- Hypothesis Testing For One Population Parameter - SamplesDocument68 pagesHypothesis Testing For One Population Parameter - SamplesMary Grace Caguioa AgasPas encore d'évaluation
- Quantum Information and FoundationsDocument510 pagesQuantum Information and FoundationsBrent AlliePas encore d'évaluation
- Kelly'S Attribution Theory of PerceptionDocument15 pagesKelly'S Attribution Theory of PerceptionRahul Dawar100% (1)
- Chyla, J. - Quarks, Partons and QCDDocument210 pagesChyla, J. - Quarks, Partons and QCDMarco FrascaPas encore d'évaluation
- The Special Theory of Relativity. Anadijiban DasDocument225 pagesThe Special Theory of Relativity. Anadijiban DasMarioPas encore d'évaluation
- Maths MCQ 1&2Document7 pagesMaths MCQ 1&25026 SHIBU MPas encore d'évaluation
- Chapter 17Document19 pagesChapter 17mehdiPas encore d'évaluation
- HW1 2014Document2 pagesHW1 2014Protik DasPas encore d'évaluation
- One Way ANOVA in 4 PagesDocument8 pagesOne Way ANOVA in 4 PagesbsetiawanyPas encore d'évaluation
- Notes On Relativistic Quantum Field Theory: A Course Given by Dr. Tobias OsborneDocument97 pagesNotes On Relativistic Quantum Field Theory: A Course Given by Dr. Tobias Osbornedaniel_teivelisPas encore d'évaluation
- 8.325: Relativistic Quantum Field Theory III Problem Set 2Document1 page8.325: Relativistic Quantum Field Theory III Problem Set 2belderandover09Pas encore d'évaluation
- Stochastic Simulation IntroductionDocument122 pagesStochastic Simulation IntroductionTuany R. CassianoPas encore d'évaluation
- AP Biology Name - Date - : ActivityDocument4 pagesAP Biology Name - Date - : ActivityIdris IbrahimovPas encore d'évaluation
- Summative Test Q3 Statistics and ProbabilityDocument2 pagesSummative Test Q3 Statistics and ProbabilityJOHN FRITS GERARD MOMBAY100% (1)
- Pa-4 1649Document4 pagesPa-4 1649Soham GuptaPas encore d'évaluation