Vous aimerez peut-être aussi
- De Moiver's Theorem (Trigonometry) Mathematics Question BankD'EverandDe Moiver's Theorem (Trigonometry) Mathematics Question BankPas encore d'évaluation
- Lecture 2: Basics of Probability Theory: 1 Axiomatic FoundationsDocument7 pagesLecture 2: Basics of Probability Theory: 1 Axiomatic Foundationsshaan76Pas encore d'évaluation
- Lecture6 Module2 Anova 1Document10 pagesLecture6 Module2 Anova 1Apam BenjaminPas encore d'évaluation
- Wa0193.Document4 pagesWa0193.jagarapuyajnasriPas encore d'évaluation
- Probability - Extra NotesDocument15 pagesProbability - Extra NotesHusam A. LutfiPas encore d'évaluation
- Counting: 1 1 2 2 N N 1 2 N 1 2 NDocument8 pagesCounting: 1 1 2 2 N N 1 2 N 1 2 NHabib RahmanPas encore d'évaluation
- Notes 1Document23 pagesNotes 1Daniel Fortes ManoelPas encore d'évaluation
- CS174: Note12Document5 pagesCS174: Note12juggleninjaPas encore d'évaluation
- Statistical Tests Martin G 161131 V15 UPLOADDocument33 pagesStatistical Tests Martin G 161131 V15 UPLOADAnonymous F8kqoYPas encore d'évaluation
- Unbiased StatisticDocument15 pagesUnbiased StatisticOrYuenyuenPas encore d'évaluation
- Probability StatsDocument39 pagesProbability StatsRenz Anthony Espino100% (1)
- PT - Practice Assignment 1 (With Solutions)Document6 pagesPT - Practice Assignment 1 (With Solutions)Vishnu Bhanderi100% (1)
- hw05 Solution PDFDocument8 pageshw05 Solution PDFsiddharth1kPas encore d'évaluation
- MATH 437/ MATH 535: Applied Stochastic Processes/ Advanced Applied Stochastic ProcessesDocument7 pagesMATH 437/ MATH 535: Applied Stochastic Processes/ Advanced Applied Stochastic ProcessesKashif KhalidPas encore d'évaluation
- Stats ch6Document16 pagesStats ch6Narayan NandedaPas encore d'évaluation
- Module 4 - Fundamentals of ProbabilityDocument50 pagesModule 4 - Fundamentals of ProbabilitybindewaPas encore d'évaluation
- Ps 3Document6 pagesPs 3Anonymous bOvvH4Pas encore d'évaluation
- Regression AnalysisDocument280 pagesRegression AnalysisA.Benhari100% (1)
- Assignment On Chapter-10 (Maths Solved) Business Statistics Course Code - ALD 2104Document32 pagesAssignment On Chapter-10 (Maths Solved) Business Statistics Course Code - ALD 2104Sakib Ul-abrarPas encore d'évaluation
- Geometric Distribution ReportDocument5 pagesGeometric Distribution Reportrinsonlee80Pas encore d'évaluation
- Saharon Shelah - Very Weak Zero One Law For Random Graphs With Order and Random Binary FunctionsDocument11 pagesSaharon Shelah - Very Weak Zero One Law For Random Graphs With Order and Random Binary FunctionsJgfm2Pas encore d'évaluation
- STA286 Problem Set 2 Solutions: Chapter 2 QuestionsDocument7 pagesSTA286 Problem Set 2 Solutions: Chapter 2 QuestionsMD Al-AminPas encore d'évaluation
- Midterm SolutionsDocument5 pagesMidterm SolutionsLinbailuBellaJiangPas encore d'évaluation
- Chi 2Document7 pagesChi 2Apuu Na Juak EhPas encore d'évaluation
- Binomial DistributionDocument22 pagesBinomial DistributionRemelyn AsahidPas encore d'évaluation
- HW 6Document7 pagesHW 6melankolia370Pas encore d'évaluation
- Maths Methods Probability NotesDocument10 pagesMaths Methods Probability NotesAnonymous na314kKjOA100% (1)
- DM Unit II CH 1finalDocument91 pagesDM Unit II CH 1finalKhaja AhmedPas encore d'évaluation
- MTH202 Quiz-3 by Vu Topper RMDocument16 pagesMTH202 Quiz-3 by Vu Topper RMdanish3175040486Pas encore d'évaluation
- January 2016BDocument7 pagesJanuary 2016BjanPas encore d'évaluation
- CH 9 SolDocument6 pagesCH 9 SolFinnigan O'FlahertyPas encore d'évaluation
- TSDT16 20080307 SolDocument3 pagesTSDT16 20080307 SolJayakody NalinPas encore d'évaluation
- Prob Imp THRDocument7 pagesProb Imp THREos MaestroPas encore d'évaluation
- Random Variables: Exercise 2.1 (Uniform Distribution)Document7 pagesRandom Variables: Exercise 2.1 (Uniform Distribution)pseudomotivePas encore d'évaluation
- ST2334 21S2 Tutorial 5Document3 pagesST2334 21S2 Tutorial 5gsdgsdPas encore d'évaluation
- hw1 PDFDocument3 pageshw1 PDF何明涛Pas encore d'évaluation
- Lecture 4Document8 pagesLecture 4Madina SuleimenovaPas encore d'évaluation
- Answer: (A) PR (BDocument14 pagesAnswer: (A) PR (BMohitPas encore d'évaluation
- Binomial/Poisson Distributions Summary Binomial Poisson: Independent Trials, Whereby Each TrialDocument4 pagesBinomial/Poisson Distributions Summary Binomial Poisson: Independent Trials, Whereby Each TrialFaisal RaoPas encore d'évaluation
- Statistical Concepts BasicsDocument17 pagesStatistical Concepts BasicsVeeresha YrPas encore d'évaluation
- Lesson4 Probability of An EventDocument85 pagesLesson4 Probability of An Eventheba elkoulyPas encore d'évaluation
- Imo 2006Document65 pagesImo 2006Vincent LinPas encore d'évaluation
- 1062 X Maths Support Material Key Points HOTS and VBQ 2014 15Document406 pages1062 X Maths Support Material Key Points HOTS and VBQ 2014 15KAPIL SHARMA0% (1)
- EF Exam: Texas A&M Math Contest 23 October, 2010Document2 pagesEF Exam: Texas A&M Math Contest 23 October, 2010rliu27Pas encore d'évaluation
- Statistics For Data SciencesDocument10 pagesStatistics For Data Sciencesgaldo2Pas encore d'évaluation
- Unit 3 Probability Distributions - 21MA41Document17 pagesUnit 3 Probability Distributions - 21MA41luffyuzumaki1003Pas encore d'évaluation
- Assignment 3 SolDocument6 pagesAssignment 3 SolChuah Chian YeongPas encore d'évaluation
- Term 3 Week 6 Revision Exercises - Statistics Suggested SolutionsDocument5 pagesTerm 3 Week 6 Revision Exercises - Statistics Suggested SolutionsWen Berry JiahuiPas encore d'évaluation
- HW4Document7 pagesHW4Pallavi RaiturkarPas encore d'évaluation
- Chapter 02Document14 pagesChapter 02Joe Di NapoliPas encore d'évaluation
- BS UNIT 2 Note # 3Document7 pagesBS UNIT 2 Note # 3Sherona ReidPas encore d'évaluation
- Chapter 2 BFC34303 (Lyy)Document104 pagesChapter 2 BFC34303 (Lyy)Mohamad Ariff100% (1)
- 2003 - Paper IIIDocument6 pages2003 - Paper IIIhmphryPas encore d'évaluation
- Lecture 3Document24 pagesLecture 3Vishal KumarPas encore d'évaluation
- Inclusion ExclusionDocument5 pagesInclusion ExclusionsaiPas encore d'évaluation
- Spring 2006 Final SolutionDocument12 pagesSpring 2006 Final SolutionAndrew ZellerPas encore d'évaluation
- Probability & Statistics BITS WILPDocument174 pagesProbability & Statistics BITS WILPpdparthasarathy03100% (2)
- Mathematical Foundations of Information TheoryD'EverandMathematical Foundations of Information TheoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (9)
- Calc 1141 2Document27 pagesCalc 1141 2BobPas encore d'évaluation
- The Global Financial Crisis: - An Actuarial PerspectiveDocument3 pagesThe Global Financial Crisis: - An Actuarial PerspectiveBobPas encore d'évaluation
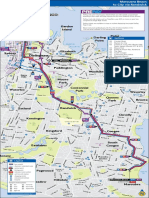
- 376 - 377 Bus MapDocument1 page376 - 377 Bus MapBobPas encore d'évaluation
- ch19 3Document40 pagesch19 3BobPas encore d'évaluation
- Hapter Xercise OlutionsDocument5 pagesHapter Xercise OlutionsBobPas encore d'évaluation
- International: 2020 VisionDocument5 pagesInternational: 2020 VisionBobPas encore d'évaluation
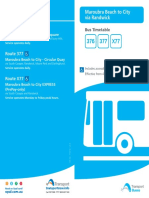
- 376 - 377 Bus Time TableDocument19 pages376 - 377 Bus Time TableBobPas encore d'évaluation
- Takaful: An Islamic Alternative To Conventional Insurance Sees Phenomenal GrowthDocument3 pagesTakaful: An Islamic Alternative To Conventional Insurance Sees Phenomenal GrowthBobPas encore d'évaluation
- Code of Professional Conduct November 2009: IndexDocument10 pagesCode of Professional Conduct November 2009: IndexBobPas encore d'évaluation
- Chapter 3: Professionalism Exercise Sample Solutions Exercise 3.1Document6 pagesChapter 3: Professionalism Exercise Sample Solutions Exercise 3.1BobPas encore d'évaluation
- Is Insurance A Luxury?Document3 pagesIs Insurance A Luxury?BobPas encore d'évaluation
- ch4 5Document37 pagesch4 5BobPas encore d'évaluation
- Draft Standards For The Development of Spreadsheets: 1 Spreadsheets Can Be AssetsDocument5 pagesDraft Standards For The Development of Spreadsheets: 1 Spreadsheets Can Be AssetsBobPas encore d'évaluation
- Pension Benefit Design: Flexibility and The Integration of Insurance Over The Life CycleDocument43 pagesPension Benefit Design: Flexibility and The Integration of Insurance Over The Life CycleBobPas encore d'évaluation
- Signs of Ageing: HealthcareDocument2 pagesSigns of Ageing: HealthcareBobPas encore d'évaluation
- The Uk Actuarial Profession The Actuaries' Code: ApplicationDocument3 pagesThe Uk Actuarial Profession The Actuaries' Code: ApplicationBobPas encore d'évaluation
- Rules of Professional ConductDocument9 pagesRules of Professional ConductBobPas encore d'évaluation
- Code of Conduct For Candidates: Effective December 1, 2008Document2 pagesCode of Conduct For Candidates: Effective December 1, 2008BobPas encore d'évaluation
- Code of Professional Conduct: Section 5Document4 pagesCode of Professional Conduct: Section 5BobPas encore d'évaluation
- Institute of Actuaries of India: Professional Conduct Standards (Referred To As PCS)Document9 pagesInstitute of Actuaries of India: Professional Conduct Standards (Referred To As PCS)BobPas encore d'évaluation
- Doors Of: December 2009/january 2010Document6 pagesDoors Of: December 2009/january 2010BobPas encore d'évaluation
- Chapter 2 Exercises and Solutions: Exercise 2.1Document3 pagesChapter 2 Exercises and Solutions: Exercise 2.1BobPas encore d'évaluation
- Expert Input: On The Current Financial CrisisDocument7 pagesExpert Input: On The Current Financial CrisisBobPas encore d'évaluation
- ORSI Course StructureDocument18 pagesORSI Course Structureanindya_chatterjeePas encore d'évaluation
- Probability - Statistics and Numerical MethodsDocument3 pagesProbability - Statistics and Numerical Methodsreallynilay123Pas encore d'évaluation
- CMU Course ListingDocument8 pagesCMU Course ListingNoor BustamiPas encore d'évaluation
- MAKAUT Mathematics III SyllabusDocument2 pagesMAKAUT Mathematics III SyllabusRTET Plagiarism CheckPas encore d'évaluation
- Statistics HandoutDocument15 pagesStatistics HandoutAnish GargPas encore d'évaluation
- Statistics SyllabusDocument37 pagesStatistics SyllabusXING XINGPas encore d'évaluation
- HistogramDocument12 pagesHistogramamelia99Pas encore d'évaluation
- Test Bank For Essentials of Modern Business Statistics 5th Edition David R AndersonDocument28 pagesTest Bank For Essentials of Modern Business Statistics 5th Edition David R AndersonPhillipRamirezezkyc100% (73)
- Monte Carlo Simulation For Finding PiDocument2 pagesMonte Carlo Simulation For Finding PinithinPas encore d'évaluation
- Commonly Used Statistical TermsDocument4 pagesCommonly Used Statistical TermsMadison Hartfield100% (1)
- 0.6 Out of 0.6 Points: Distribution As 68% Is Typically Used For Normal DistributionDocument5 pages0.6 Out of 0.6 Points: Distribution As 68% Is Typically Used For Normal Distribution高晴汝Pas encore d'évaluation
- Chapter 7 - 7.3, 7.4 Nalanda PDFDocument31 pagesChapter 7 - 7.3, 7.4 Nalanda PDFAman BhatiaPas encore d'évaluation
- Statistics SubjectiveDocument2 pagesStatistics SubjectiveAamirPas encore d'évaluation
- Chapter 1 Survival Distributions and Life TablesDocument14 pagesChapter 1 Survival Distributions and Life TablesAkif Muhammad100% (1)
- Statistical Methods in Data Analysis - W. J. MetzgerDocument278 pagesStatistical Methods in Data Analysis - W. J. MetzgerDavidMarcosPerezMuñozPas encore d'évaluation
- Docslide - Us - Statistics s1 Revision Papers With Answers PDFDocument22 pagesDocslide - Us - Statistics s1 Revision Papers With Answers PDFashiquePas encore d'évaluation
- Statistics and Probability Performance Task Binomial DistributionDocument7 pagesStatistics and Probability Performance Task Binomial DistributionArmandoPas encore d'évaluation
- Supply Chain Key ConceptDocument68 pagesSupply Chain Key ConceptRAHUL DIXITPas encore d'évaluation
- Solution Manual For Statistical Inference Second Edition George Casella Roger L BergerDocument12 pagesSolution Manual For Statistical Inference Second Edition George Casella Roger L Bergervitalizefoothook.x05r100% (26)
- Problem BookletDocument72 pagesProblem BookletEric HePas encore d'évaluation
- Week 5 Worksheet AnswersDocument6 pagesWeek 5 Worksheet AnswersJennifer MoorePas encore d'évaluation
- 2A1 Probability and Statistics L1 Notes Payne PDFDocument62 pages2A1 Probability and Statistics L1 Notes Payne PDFajdhPas encore d'évaluation
- Modeling of Two-Dimensional Random Fields: R. JankowskiDocument7 pagesModeling of Two-Dimensional Random Fields: R. Jankowskiaman guptaPas encore d'évaluation
- Furqan Khan - Assignments - 302 - StatsDocument2 pagesFurqan Khan - Assignments - 302 - Statsfurqan ahmed khanPas encore d'évaluation
- Statistic DLL-W1Document9 pagesStatistic DLL-W1Jovito EspantoPas encore d'évaluation
- Chap 1 - Portfolio Risk and Return Part1Document91 pagesChap 1 - Portfolio Risk and Return Part1eya feguiriPas encore d'évaluation
- ProbabilityDocument21 pagesProbabilityVarshney NitinPas encore d'évaluation
- Normal Distribution TableDocument1 pageNormal Distribution Tablegoi_pin0% (1)
- Handbook of Statistics PK Sen & PrkrisnaiahDocument945 pagesHandbook of Statistics PK Sen & PrkrisnaiahgabsysPas encore d'évaluation
- 03 Probability DistributionDocument3 pages03 Probability DistributionLKS-388Pas encore d'évaluation