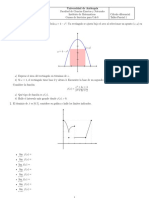
Vous aimerez peut-être aussi
- Clase3 2 28Document27 pagesClase3 2 28ricardoPas encore d'évaluation
- Lab04 521230 2018 PDFDocument10 pagesLab04 521230 2018 PDFAndres LPas encore d'évaluation
- HOLADocument10 pagesHOLAnahomyPas encore d'évaluation
- 00 00 Problemario CalculoDocument41 pages00 00 Problemario Calculojuliho.castilloPas encore d'évaluation
- Guia de Estudio 1Document3 pagesGuia de Estudio 1christo206244Pas encore d'évaluation
- Examen de Métodos NuméricosDocument17 pagesExamen de Métodos NuméricosEdgar MurilloPas encore d'évaluation
- Tema 4 EjerciciosDocument3 pagesTema 4 Ejerciciosmkarygames22Pas encore d'évaluation
- Ejercicios MétodosDocument36 pagesEjercicios MétodosDaniel Espin GarciaPas encore d'évaluation
- Tarea 3Document3 pagesTarea 3Sara NieblesPas encore d'évaluation
- 2.1 Introduction To Matlab 2021-2Document35 pages2.1 Introduction To Matlab 2021-2brayan virguezPas encore d'évaluation
- T05 DistribucionesDocument25 pagesT05 DistribucionesAlfonso Perez RodriguezPas encore d'évaluation
- Caos DeterministaDocument16 pagesCaos DeterministaMARIO MÁIQUEZ GARCÍAPas encore d'évaluation
- Maria Camila LeonDocument17 pagesMaria Camila LeonAngiePas encore d'évaluation
- Funciones y AplicacionesDocument7 pagesFunciones y AplicacionesAntonio Chumpitaz JulcaPas encore d'évaluation
- Guia FuncionesDocument11 pagesGuia FuncionesAlejandra DíazPas encore d'évaluation
- Guia 10Document5 pagesGuia 10FREDI PASTEN APABLAZAPas encore d'évaluation
- Guia Funciones 2009-01Document7 pagesGuia Funciones 2009-01enfermeria_unab_011Pas encore d'évaluation
- 1 Curvas y Funciones Vectoriales de Una Variable RealDocument9 pages1 Curvas y Funciones Vectoriales de Una Variable RealElder Cortez Bueno0% (1)
- Dinámica de VueloDocument83 pagesDinámica de VueloMarvin TorresPas encore d'évaluation
- Funciones Con Valores VectorialesDocument9 pagesFunciones Con Valores VectorialesVan de KampPas encore d'évaluation
- TP 2Document4 pagesTP 2Número De OroPas encore d'évaluation
- Examenes Amat IIDocument2 pagesExamenes Amat IIluis mendietaPas encore d'évaluation
- Acti - Apre. No. 1 IntegraciónDocument7 pagesActi - Apre. No. 1 IntegraciónErik Martinez ValeroPas encore d'évaluation
- Simulacion Matematica EspolDocument62 pagesSimulacion Matematica EspolRon Rc100% (1)
- Problemas PET 2009 1Document2 pagesProblemas PET 2009 1luisRuben medinaPas encore d'évaluation
- Tarea-4 Estudiante1Document11 pagesTarea-4 Estudiante1felipe sanchezPas encore d'évaluation
- Separata 4Document2 pagesSeparata 4Carlos Anthony Quispe PérezPas encore d'évaluation
- Estadística para Ingeniería - Variable AleatoriaDocument36 pagesEstadística para Ingeniería - Variable AleatoriaHarold Arones OrtegaPas encore d'évaluation
- Tarea 1 Calculo Multivariado Aporte 1Document6 pagesTarea 1 Calculo Multivariado Aporte 1Juan Sebastian RestrepoPas encore d'évaluation
- Tarea 1 Calculo Multivariado Aporte 1Document6 pagesTarea 1 Calculo Multivariado Aporte 1Juan Sebastian RestrepoPas encore d'évaluation
- Calculo Multivariado Tarea 1 Funciones de VariablesDocument39 pagesCalculo Multivariado Tarea 1 Funciones de VariablesIvan BolañoPas encore d'évaluation
- Guía 5. Funciones de Varias Variables MateDocument11 pagesGuía 5. Funciones de Varias Variables MateRodrigo BazánPas encore d'évaluation
- Paso 2 - Muestreo, Cuantizacion y TDFDocument11 pagesPaso 2 - Muestreo, Cuantizacion y TDFROBINSON PRADO VILLEGASPas encore d'évaluation
- Guia2 Scilab 2019Document6 pagesGuia2 Scilab 2019Enrique ProfesorPas encore d'évaluation
- Complementos de MatemáticasDocument5 pagesComplementos de Matemáticasjax21esPas encore d'évaluation
- Practicas Lab1Document5 pagesPracticas Lab1Jarixander Perez RomeroPas encore d'évaluation
- Guia 2 Calculo1 Derivada de Una FunciónDocument18 pagesGuia 2 Calculo1 Derivada de Una FunciónRicardo LopezPas encore d'évaluation
- Prob VAleatoriasDocument8 pagesProb VAleatoriasElMisterioDeCalendaPas encore d'évaluation
- Trabajo UD3Document1 pageTrabajo UD3Harold BarrePas encore d'évaluation
- Metodo de Newton RaphsonDocument11 pagesMetodo de Newton RaphsonDR. JUAN JESÚS SORIA QUIJAITE50% (2)
- Regrsión Lineal Múltiple. ANOVA. R2. Predicciones.Document6 pagesRegrsión Lineal Múltiple. ANOVA. R2. Predicciones.JosmiPas encore d'évaluation
- Optimizacion VectorialDocument32 pagesOptimizacion VectorialjoelPas encore d'évaluation
- Taller 1Document6 pagesTaller 1Kelvin Parco FelicesPas encore d'évaluation
- Cal 2Document13 pagesCal 2Jose Eduardo Barriga RuaPas encore d'évaluation
- Ejercicios Calculo-DiferencialDocument6 pagesEjercicios Calculo-DiferencialJose Martin Serrano TorresPas encore d'évaluation
- Taller Parcial 1Document5 pagesTaller Parcial 1Cristian Camilo Sanin VillamilPas encore d'évaluation
- Hoja 4 - 1Document2 pagesHoja 4 - 1alterlaboroPas encore d'évaluation
- ValeatoriasDocument2 pagesValeatoriasMiguel NaupayPas encore d'évaluation
- Exercícios de Cálculo 3Document6 pagesExercícios de Cálculo 3Fabricio Alves OliveiraPas encore d'évaluation
- Apuntes Metodos Numericos Sistema de Ecuaciones No LinealesDocument30 pagesApuntes Metodos Numericos Sistema de Ecuaciones No LinealesCris TurínPas encore d'évaluation
- Laboratorio4 PDFDocument4 pagesLaboratorio4 PDFconsueloriquelme1Pas encore d'évaluation
- 11111111111Document18 pages11111111111Kriz MolinaPas encore d'évaluation
- Calculo Diferencial Victor PDFDocument57 pagesCalculo Diferencial Victor PDFSergioPas encore d'évaluation
- TALLER # 1 Matemáticas 2Document41 pagesTALLER # 1 Matemáticas 2An GeLaPas encore d'évaluation
- I3 Año AnteriorDocument4 pagesI3 Año AnteriorMatías RoaPas encore d'évaluation
- Trabajo Calculo DiferencialDocument15 pagesTrabajo Calculo DiferencialJuan IdrovoPas encore d'évaluation
- Practica 4Document3 pagesPractica 4shauwnPas encore d'évaluation
- Unidad 6.2-Ecuaciones Diferenciales OrdinariasDocument4 pagesUnidad 6.2-Ecuaciones Diferenciales OrdinariasAndres MontoyaPas encore d'évaluation
- Quiz 1Document11 pagesQuiz 1MAGDAFERNANDAPas encore d'évaluation
- Probabilidad y EstadisticaDocument165 pagesProbabilidad y Estadisticafrja513424324Pas encore d'évaluation
- Ajustar Distribuciones DatosDocument24 pagesAjustar Distribuciones DatosJuan Paredes CamposPas encore d'évaluation
- La EstadísticaDocument3 pagesLa Estadísticancabeza227Pas encore d'évaluation
- Quiz 1Document7 pagesQuiz 1Julieth Alexandra GuarinPas encore d'évaluation
- S04.s1-PRUEBA DE HIPOTESIS - UTP FINALDocument14 pagesS04.s1-PRUEBA DE HIPOTESIS - UTP FINALSantiag CzPas encore d'évaluation
- 4 - Diseño en Bloque Completamente AleatorizadoDocument19 pages4 - Diseño en Bloque Completamente AleatorizadoMarcelo Rodriguez Gallardo100% (4)
- ESTADISTICADocument21 pagesESTADISTICAAlfonso Enrique Mendoza BenavidesPas encore d'évaluation
- Teorema de ChebyshevDocument13 pagesTeorema de ChebyshevP David Bautista Lopez0% (1)
- Distribución BinomialDocument12 pagesDistribución BinomialDamianPas encore d'évaluation
- Ejercicios Arboles de Decisión para PetroleosDocument10 pagesEjercicios Arboles de Decisión para PetroleosHernan Soler Jaramillo100% (2)
- Segundo Taller Estadistica InferencialDocument3 pagesSegundo Taller Estadistica InferencialsanpornuPas encore d'évaluation
- Trabajo Final Estadistica 2Document18 pagesTrabajo Final Estadistica 2esthel rutPas encore d'évaluation
- PROBABILIDADESDocument13 pagesPROBABILIDADESEstefany MontoyaPas encore d'évaluation
- Taller EstadisticaDocument8 pagesTaller EstadisticaNohemy Quijano ArdilaPas encore d'évaluation
- Taller #1 AmpliadaDocument17 pagesTaller #1 AmpliadaOlga Lucia Martinez HoyosPas encore d'évaluation
- Tipos de Muestreo y Tipos de PreguntasDocument7 pagesTipos de Muestreo y Tipos de PreguntasJOSE. M.GPas encore d'évaluation
- Domimguez Naomy Actividad#1Document6 pagesDomimguez Naomy Actividad#1Naomy DominguezPas encore d'évaluation
- Examen PracticoDocument8 pagesExamen PracticoEmmanuel VenegasPas encore d'évaluation
- Martello El MuestreoDocument5 pagesMartello El MuestreoKaren BustamantePas encore d'évaluation
- Ejercicios 3Document3 pagesEjercicios 3kers merinoPas encore d'évaluation
- Ejemplos de Ejercicios BernoulliDocument8 pagesEjemplos de Ejercicios BernoulliMagaly BenaventePas encore d'évaluation
- Funcion de Distribución NormalDocument41 pagesFuncion de Distribución NormalTanía FrítzPas encore d'évaluation
- Ejercicios EstadisticaDocument29 pagesEjercicios EstadisticaAndresNarea100% (1)
- Curso - Estadística IDocument13 pagesCurso - Estadística IFRANCISCO MACUARANPas encore d'évaluation
- Estadistica 5 EjerciciosDocument3 pagesEstadistica 5 EjerciciosOswaldo DuranPas encore d'évaluation
- Evaluacion Final - Escenario 8 - SEGUNDO BLOQUE-CIENCIAS BASICASTADISTICA II - (GRUPO13)Document11 pagesEvaluacion Final - Escenario 8 - SEGUNDO BLOQUE-CIENCIAS BASICASTADISTICA II - (GRUPO13)David BarretoPas encore d'évaluation
- 5test de Hipotesis Dos Muestras PDFDocument48 pages5test de Hipotesis Dos Muestras PDFNicolas SilvaPas encore d'évaluation
- FórmulasDocument2 pagesFórmulasIt's SilviaPas encore d'évaluation
- Técnicas de Muestreo e Inspección Aplicadas A Los Alimentos - Manuel Blanco - PresnetacionDocument65 pagesTécnicas de Muestreo e Inspección Aplicadas A Los Alimentos - Manuel Blanco - PresnetacionKiko SalvadorPas encore d'évaluation