Vous aimerez peut-être aussi
- Edexcel C4 Cheat SheetDocument8 pagesEdexcel C4 Cheat SheetAbdul Aahad100% (1)
- Module 3 Resource Guide2014 Editionv4Document28 pagesModule 3 Resource Guide2014 Editionv4Surya GowtamPas encore d'évaluation
- Notes 2Document117 pagesNotes 2Mustafiz AhmadPas encore d'évaluation
- Notación TensorialDocument22 pagesNotación TensorialRodrigoGutierrezPas encore d'évaluation
- Lesson 1 Tensor Index NotationDocument16 pagesLesson 1 Tensor Index Notationsimakumari18919Pas encore d'évaluation
- Rota On Multilinear Algebra and GeometryDocument43 pagesRota On Multilinear Algebra and Geometryrasgrn7112Pas encore d'évaluation
- Dirac Notation and Basic Linear Algebra For Quantum ComputingDocument4 pagesDirac Notation and Basic Linear Algebra For Quantum ComputingsarhahhPas encore d'évaluation
- Index NotationDocument8 pagesIndex NotationMahdi BzeihPas encore d'évaluation
- Foundations of Mathematical Physics: Vectors, Tensors and Fields 2009 - 2010Document80 pagesFoundations of Mathematical Physics: Vectors, Tensors and Fields 2009 - 2010devkgunaPas encore d'évaluation
- Geometry in PhysicsDocument79 pagesGeometry in PhysicsParag MahajaniPas encore d'évaluation
- 0 Short Review of Some Mathematics, Nomenclature and NotationDocument14 pages0 Short Review of Some Mathematics, Nomenclature and NotationWong Zam MingYinPas encore d'évaluation
- Linear Algebra Review: CSC2515 - Machine Learning - Fall 2002Document7 pagesLinear Algebra Review: CSC2515 - Machine Learning - Fall 2002Pravin BhandarkarPas encore d'évaluation
- Cmi Linear Algebra Full NotesDocument83 pagesCmi Linear Algebra Full NotesNaveen suryaPas encore d'évaluation
- BasisDocument8 pagesBasisUntung Teguh BudiantoPas encore d'évaluation
- Engg AnalysisDocument117 pagesEngg AnalysisrajeshtaladiPas encore d'évaluation
- A Guide To Solving Simple ODEs - Brian Mullins - Univ of TorontoDocument7 pagesA Guide To Solving Simple ODEs - Brian Mullins - Univ of TorontoAlda EnglandPas encore d'évaluation
- Notes On Transport PhenomenaDocument184 pagesNotes On Transport PhenomenarajuvadlakondaPas encore d'évaluation
- Orthogonal Functions: 3.1 VectorsDocument10 pagesOrthogonal Functions: 3.1 VectorsbbteenagerPas encore d'évaluation
- Vectors Preparation Tips For IIT JEE - askIITiansDocument9 pagesVectors Preparation Tips For IIT JEE - askIITiansaskiitian100% (1)
- Graphical Tensor Notation For Interpretability - LessWrongDocument41 pagesGraphical Tensor Notation For Interpretability - LessWrongmirandowebsPas encore d'évaluation
- Tensors Without TearsDocument12 pagesTensors Without TearsAmber HolmanPas encore d'évaluation
- Understanding Regression With Geometry - by Ravi Charan - MediumDocument20 pagesUnderstanding Regression With Geometry - by Ravi Charan - MediumOmar Enrique Garcia CaicedoPas encore d'évaluation
- Epsilon DeltaDocument6 pagesEpsilon DeltaFate_WeaverPas encore d'évaluation
- A Tutorial On Spectral ClusteringDocument32 pagesA Tutorial On Spectral Clusteringsagar deshpandePas encore d'évaluation
- 53 NotesDocument16 pages53 NotesSeshanPas encore d'évaluation
- Quantum PhysicsDocument50 pagesQuantum PhysicsSahil ChadhaPas encore d'évaluation
- Curve Fitting WZ Zilliam LeeDocument14 pagesCurve Fitting WZ Zilliam LeeFirdaus AzizanPas encore d'évaluation
- 1 Scalars and Vectors: 1.1 What Is A Vector?Document9 pages1 Scalars and Vectors: 1.1 What Is A Vector?Rishi ScifreakPas encore d'évaluation
- Vectors LectureDocument15 pagesVectors LectureAbhinav BajpaiPas encore d'évaluation
- Review Material For Exam 1Document7 pagesReview Material For Exam 1Cecilia DawsonPas encore d'évaluation
- For A Given Vector in 2D Space, Stretching It by A Value of 2 Is CalledDocument23 pagesFor A Given Vector in 2D Space, Stretching It by A Value of 2 Is CalledIgorJales100% (1)
- Iiserb Mm1 Notes Oct 4Document30 pagesIiserb Mm1 Notes Oct 4Shruti ShirolPas encore d'évaluation
- Introduction To Continuum Mechanics Lecture Notes: Jagan M. PadbidriDocument26 pagesIntroduction To Continuum Mechanics Lecture Notes: Jagan M. PadbidriAshmilPas encore d'évaluation
- Big Picture in Focus: Three DimensionsDocument12 pagesBig Picture in Focus: Three DimensionsAlvin GilayPas encore d'évaluation
- VectorsDocument11 pagesVectorsKishan500Pas encore d'évaluation
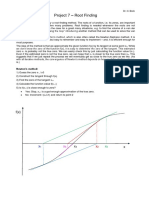
- Project 7 - Root Finding: Newton's MethodDocument4 pagesProject 7 - Root Finding: Newton's Methodhannan1993Pas encore d'évaluation
- Key Machine Learning PreReq - Viewing Linear Algebra Through The Right Lenses - Data Science CentralDocument3 pagesKey Machine Learning PreReq - Viewing Linear Algebra Through The Right Lenses - Data Science CentralrajeshPas encore d'évaluation
- What Is A Vector SpaceDocument7 pagesWhat Is A Vector Spacedaveix3Pas encore d'évaluation
- Complex Numbers WorkshopDocument30 pagesComplex Numbers WorkshopMichelle HsiehPas encore d'évaluation
- Introduction To Continuum Mechanics Lecture Notes: Jagan M. PadbidriDocument33 pagesIntroduction To Continuum Mechanics Lecture Notes: Jagan M. Padbidrivishnu rajuPas encore d'évaluation
- 2 StatesDocument10 pages2 StatesVinayak DuttaPas encore d'évaluation
- Week001 ModuleDocument12 pagesWeek001 ModuleMalik MalikPas encore d'évaluation
- Linear Algebra I: Course No. 100 221 Fall 2006 Michael StollDocument68 pagesLinear Algebra I: Course No. 100 221 Fall 2006 Michael StollDilip Kumar100% (1)
- Deep LearningDocument28 pagesDeep Learning20010700Pas encore d'évaluation
- Luxburg07 Tutorial 4488Document32 pagesLuxburg07 Tutorial 4488diablo_hexPas encore d'évaluation
- Errata - A Most Incomprehensible ThingDocument16 pagesErrata - A Most Incomprehensible ThingAshish JogPas encore d'évaluation
- CalcIII EqnOfPlanesDocument5 pagesCalcIII EqnOfPlaneshendrawan707Pas encore d'évaluation
- Some Mathematical Preliminaries Linear Vector SpacesDocument9 pagesSome Mathematical Preliminaries Linear Vector SpacesjasmonPas encore d'évaluation
- An Algebraic Equation in Which Each ElementDocument3 pagesAn Algebraic Equation in Which Each Elementanjaiah_19945Pas encore d'évaluation
- Block 3 Linear Algebra: Second Order Differential EquationsDocument50 pagesBlock 3 Linear Algebra: Second Order Differential EquationsKrishanPas encore d'évaluation
- Linear RegressionDocument15 pagesLinear RegressionAvika SaraogiPas encore d'évaluation
- Equations of LinesDocument9 pagesEquations of LinesZyra Mae AntidoPas encore d'évaluation
- Intro To TensorsDocument22 pagesIntro To TensorsSumeet KhatriPas encore d'évaluation
- Lecture - I Vector SpaceDocument5 pagesLecture - I Vector SpaceAbhijit Kar GuptaPas encore d'évaluation
- Master the Fundamentals of Electromagnetism and EM-InductionD'EverandMaster the Fundamentals of Electromagnetism and EM-InductionPas encore d'évaluation
- Module 1 Resource Guide2014 Editionv4Document26 pagesModule 1 Resource Guide2014 Editionv4Surya GowtamPas encore d'évaluation
- Module 0 Resource Guide2014 Editionv6Document30 pagesModule 0 Resource Guide2014 Editionv6Surya GowtamPas encore d'évaluation
- Module 0 Resource Guide2014 Editionv6Document30 pagesModule 0 Resource Guide2014 Editionv6Surya GowtamPas encore d'évaluation
- IandF CAA Guide M0 201605Document32 pagesIandF CAA Guide M0 201605Surya GowtamPas encore d'évaluation
- Advanced Engineering Mathematics 4th Ed K StroudDocument1 057 pagesAdvanced Engineering Mathematics 4th Ed K StroudCreanga Florin100% (1)
- Kivy LatestDocument624 pagesKivy LatestDAnn LaraPas encore d'évaluation
- Kivy Framework KoreaDocument14 pagesKivy Framework KoreaSurya GowtamPas encore d'évaluation
- TaDocument138 pagesTaEpic WinPas encore d'évaluation
- Microchip Stack For The ZigBee™ ProtocolDocument40 pagesMicrochip Stack For The ZigBee™ ProtocolprathameshmestryPas encore d'évaluation
- CapgeminiDocument5 pagesCapgeminiSurya GowtamPas encore d'évaluation