Vous aimerez peut-être aussi
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- Qualitative ResearchDocument102 pagesQualitative ResearchBoris Herbas TorricoPas encore d'évaluation
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
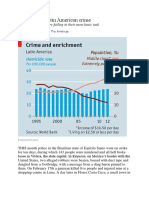
- The Costs of Latin American CrimeDocument3 pagesThe Costs of Latin American CrimeBoris Herbas TorricoPas encore d'évaluation
- Clash of IdeasDocument60 pagesClash of IdeasBoris Herbas TorricoPas encore d'évaluation
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- Alcohol Consumption and CancerDocument7 pagesAlcohol Consumption and CancerBoris Herbas TorricoPas encore d'évaluation
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- Efficiency vs. IPA (Total Quality Management)Document25 pagesEfficiency vs. IPA (Total Quality Management)Boris Herbas TorricoPas encore d'évaluation
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (344)
- Enhance Importance Performance Analysis Through SegmentationDocument17 pagesEnhance Importance Performance Analysis Through SegmentationBoris Herbas TorricoPas encore d'évaluation
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (399)
- Retracing DR - Juran by Dr. KanoDocument11 pagesRetracing DR - Juran by Dr. KanoBoris Herbas TorricoPas encore d'évaluation
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- 2517Document4 pages2517mbmba22Pas encore d'évaluation
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- The Pareto PrincipleDocument6 pagesThe Pareto PrincipleBoris Herbas Torrico100% (1)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- Performance Management in Call CentersDocument8 pagesPerformance Management in Call CentersBoris Herbas TorricoPas encore d'évaluation
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Launchy 1.25 Readme FileDocument10 pagesLaunchy 1.25 Readme Fileagatzebluz100% (1)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- Motion and Time: Check Your Progress Factual QuestionsDocument27 pagesMotion and Time: Check Your Progress Factual QuestionsRahul RajPas encore d'évaluation
- Learner's Material: ScienceDocument27 pagesLearner's Material: ScienceCarlz BrianPas encore d'évaluation
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (73)
- 123456Document4 pages123456Lance EsquivarPas encore d'évaluation
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- Michael M. Lombardo, Robert W. Eichinger - Preventing Derailmet - What To Do Before It's Too Late (Technical Report Series - No. 138g) - Center For Creative Leadership (1989)Document55 pagesMichael M. Lombardo, Robert W. Eichinger - Preventing Derailmet - What To Do Before It's Too Late (Technical Report Series - No. 138g) - Center For Creative Leadership (1989)Sosa VelazquezPas encore d'évaluation
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- StatisticsAllTopicsDocument315 pagesStatisticsAllTopicsHoda HosnyPas encore d'évaluation
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- Group 4 - Regional and Social DialectDocument12 pagesGroup 4 - Regional and Social DialectazizaPas encore d'évaluation
- Abramson, Glenda (Ed.) - Oxford Book of Hebrew Short Stories (Oxford, 1996) PDFDocument424 pagesAbramson, Glenda (Ed.) - Oxford Book of Hebrew Short Stories (Oxford, 1996) PDFptalus100% (2)
- SEW Products OverviewDocument24 pagesSEW Products OverviewSerdar Aksoy100% (1)
- BP TB A2PlusDocument209 pagesBP TB A2PlusTAMER KIRKAYA100% (1)
- Jaimini Astrology and MarriageDocument3 pagesJaimini Astrology and MarriageTushar Kumar Bhowmik100% (1)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- Purposeful Activity in Psychiatric Rehabilitation: Is Neurogenesis A Key Player?Document6 pagesPurposeful Activity in Psychiatric Rehabilitation: Is Neurogenesis A Key Player?Utiru UtiruPas encore d'évaluation
- Veritas CloudPoint Administrator's GuideDocument294 pagesVeritas CloudPoint Administrator's Guidebalamurali_aPas encore d'évaluation
- Adverbs Before AdjectivesDocument2 pagesAdverbs Before AdjectivesJuan Sanchez PrietoPas encore d'évaluation
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- DMemo For Project RBBDocument28 pagesDMemo For Project RBBRiza Guste50% (8)
- EMI - Module 1 Downloadable Packet - Fall 2021Document34 pagesEMI - Module 1 Downloadable Packet - Fall 2021Eucarlos MartinsPas encore d'évaluation
- Weill Cornell Medicine International Tax QuestionaireDocument2 pagesWeill Cornell Medicine International Tax QuestionaireboxeritoPas encore d'évaluation
- Government by Algorithm - Artificial Intelligence in Federal Administrative AgenciesDocument122 pagesGovernment by Algorithm - Artificial Intelligence in Federal Administrative AgenciesRone Eleandro dos SantosPas encore d'évaluation
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (120)
- CGP Module 1 FinalDocument19 pagesCGP Module 1 Finaljohn lexter emberadorPas encore d'évaluation
- FIREXDocument2 pagesFIREXPausPas encore d'évaluation
- L 1 One On A Page PDFDocument128 pagesL 1 One On A Page PDFNana Kwame Osei AsarePas encore d'évaluation
- Logo DesignDocument4 pagesLogo Designdarshan kabraPas encore d'évaluation
- Charles P. Jones, Investments: Analysis and Management, Eleventh Edition, John Wiley & SonsDocument20 pagesCharles P. Jones, Investments: Analysis and Management, Eleventh Edition, John Wiley & SonsRizki AuliaPas encore d'évaluation
- PHD Thesis - Table of ContentsDocument13 pagesPHD Thesis - Table of ContentsDr Amit Rangnekar100% (15)
- Economies of Scale in European Manufacturing Revisited: July 2001Document31 pagesEconomies of Scale in European Manufacturing Revisited: July 2001vladut_stan_5Pas encore d'évaluation
- Chapter 3C Problem Solving StrategiesDocument47 pagesChapter 3C Problem Solving StrategiesnhixolePas encore d'évaluation
- 40+ Cool Good Vibes MessagesDocument10 pages40+ Cool Good Vibes MessagesRomeo Dela CruzPas encore d'évaluation
- Lista Agentiilor de Turism Licentiate Actualizare 16.09.2022Document498 pagesLista Agentiilor de Turism Licentiate Actualizare 16.09.2022LucianPas encore d'évaluation
- 23 East 4Th Street NEW YORK, NY 10003 Orchard Enterprises Ny, IncDocument2 pages23 East 4Th Street NEW YORK, NY 10003 Orchard Enterprises Ny, IncPamelaPas encore d'évaluation
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- Chapter 15 (Partnerships Formation, Operation and Ownership Changes) PDFDocument58 pagesChapter 15 (Partnerships Formation, Operation and Ownership Changes) PDFAbdul Rahman SholehPas encore d'évaluation