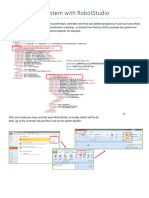
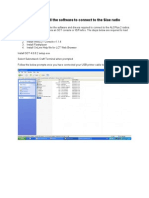
Vous aimerez peut-être aussi
- READ - FIRST - Supplemental Installation Instructions 3.0.1Document4 pagesREAD - FIRST - Supplemental Installation Instructions 3.0.1Daniel AlvaradoPas encore d'évaluation
- Firmware Upgrade Procedure of Storage 6140 From Version 6.x To 7.50 Step by StepDocument8 pagesFirmware Upgrade Procedure of Storage 6140 From Version 6.x To 7.50 Step by Stepvenukumar.LPas encore d'évaluation
- Basic Troubleshooting For Poor Computer (PC) PerformanceDocument6 pagesBasic Troubleshooting For Poor Computer (PC) PerformanceY.NikhilPas encore d'évaluation
- Update Software On A CX300 series/CX500 series/CX700/CX3 Series ArrayDocument13 pagesUpdate Software On A CX300 series/CX500 series/CX700/CX3 Series Arrayliew99Pas encore d'évaluation
- Clean Wipe Revision HistoryDocument7 pagesClean Wipe Revision HistoryorafinconsultantPas encore d'évaluation
- CPU FlowchartsDocument11 pagesCPU FlowchartsVinoth KumarPas encore d'évaluation
- Roubleshooting: If You Want To: Then RunDocument32 pagesRoubleshooting: If You Want To: Then RunThomas A. EDISSONPas encore d'évaluation
- Sun Systems Fault Analysis Workshop Online AssessmentDocument16 pagesSun Systems Fault Analysis Workshop Online AssessmentAshis DasPas encore d'évaluation
- Update Galileos System Software To MS7 - Sirona SupportDocument4 pagesUpdate Galileos System Software To MS7 - Sirona SupportdhfhdtPas encore d'évaluation
- This Guide Deploy SCCM Windows 7Document30 pagesThis Guide Deploy SCCM Windows 7Christian CehPas encore d'évaluation
- Toshiba 232 UpdateInstructions For FirmwareDocument6 pagesToshiba 232 UpdateInstructions For FirmwareMarco DelsaltoPas encore d'évaluation
- READMEV7Document5 pagesREADMEV7alberto_gomez4030Pas encore d'évaluation
- IRC5 System Builder and DownloadDocument7 pagesIRC5 System Builder and DownloadCarlos Roberto SantosPas encore d'évaluation
- MAN-096-0002 A - Patroller II Firmware Upgrade GuideDocument17 pagesMAN-096-0002 A - Patroller II Firmware Upgrade GuideDejan RomićPas encore d'évaluation
- VPLEX - VPLEX Installation and Upgrade Procedures-Install Procedures - Install VPLEX Cluster-9Document5 pagesVPLEX - VPLEX Installation and Upgrade Procedures-Install Procedures - Install VPLEX Cluster-9VijayenNPas encore d'évaluation
- Install & Activation Autodesk 2015 v1.0Document22 pagesInstall & Activation Autodesk 2015 v1.0sarvanPas encore d'évaluation
- Outpost Firewall 4.0: Maintenance GuideDocument19 pagesOutpost Firewall 4.0: Maintenance Guideሰፊነው መኮነንPas encore d'évaluation
- Technical Monitoring Alert ConfigurationDocument36 pagesTechnical Monitoring Alert Configurationmohd4redPas encore d'évaluation
- Network Licensing Installation GuideDocument11 pagesNetwork Licensing Installation GuideKishore SakhilePas encore d'évaluation
- Dell Poweredge-Xeo2650 Service Manual En-UsDocument65 pagesDell Poweredge-Xeo2650 Service Manual En-Ushakep112Pas encore d'évaluation
- Melco Control Panel Software Release 2001-10Document5 pagesMelco Control Panel Software Release 2001-10Cesar EspinozaPas encore d'évaluation
- Install and Configure a Two-Node Solaris ClusterDocument12 pagesInstall and Configure a Two-Node Solaris Clustermanojkumar_nd3Pas encore d'évaluation
- Kaseya Patch Management Best PracticesDocument4 pagesKaseya Patch Management Best PracticesronsconsultingPas encore d'évaluation
- Tangent Hub Installation Manual Rev 21Document16 pagesTangent Hub Installation Manual Rev 21freebooksPas encore d'évaluation
- Troubleshooting XPDocument7 pagesTroubleshooting XPRavi YalalaPas encore d'évaluation
- OpenEMR Installation and Upgrade Quick GuideDocument19 pagesOpenEMR Installation and Upgrade Quick GuideNdri InnocentPas encore d'évaluation
- FAQ (2 of 5) : Force Firmware Update Procedure (Ple... - Buffalo Tech ForumsDocument3 pagesFAQ (2 of 5) : Force Firmware Update Procedure (Ple... - Buffalo Tech ForumsNinjacearense100% (1)
- Test: Sun Systems Fault Analysis Workshop: Online AssessmentDocument10 pagesTest: Sun Systems Fault Analysis Workshop: Online Assessmentulrich nobel kouaméPas encore d'évaluation
- Lumia Devices FlashingDocument3 pagesLumia Devices FlashingSoporte SuministrosPas encore d'évaluation
- 9Document25 pages9Muhd QPas encore d'évaluation
- Pipenet InstallationDocument11 pagesPipenet InstallationMani Kumar0% (1)
- CR-DR Remote and Key Operator Software Upgrade Instructions PDFDocument74 pagesCR-DR Remote and Key Operator Software Upgrade Instructions PDFNiwrad MontillaPas encore d'évaluation
- Error Message: "Fatal Error:Exception Code C0000005": What Is This Error?Document3 pagesError Message: "Fatal Error:Exception Code C0000005": What Is This Error?Jonathan MartinezPas encore d'évaluation
- User Manual for EchoLabTest SoftwareDocument78 pagesUser Manual for EchoLabTest Softwaretchma hichamPas encore d'évaluation
- Unbenannt 4Document3 pagesUnbenannt 4lauraPas encore d'évaluation
- 5-Step Computer Maintenance Tutorial Windows XPDocument24 pages5-Step Computer Maintenance Tutorial Windows XPnitinkr80Pas encore d'évaluation
- 07 - GVBM15 - Troubleshooting v2.0Document81 pages07 - GVBM15 - Troubleshooting v2.0Duy Tô TháiPas encore d'évaluation
- Sun Systems Fault Analysis Workshop OnliDocument23 pagesSun Systems Fault Analysis Workshop OnliLuis AlfredoPas encore d'évaluation
- Create a Default Mac OS X Install for ImagingDocument2 pagesCreate a Default Mac OS X Install for ImagingStefan TomekPas encore d'évaluation
- Manual de Actualizacion de Firmware 452-3511 Download Toshiba EDocument6 pagesManual de Actualizacion de Firmware 452-3511 Download Toshiba Eherico201450% (2)
- Error Message: Explorer - Exe - DLL Initialization Failed... : Email PrintDocument3 pagesError Message: Explorer - Exe - DLL Initialization Failed... : Email PrintAnonymous O0T8aZZPas encore d'évaluation
- ReadmeDocument13 pagesReadmeLalo RuizPas encore d'évaluation
- Glomosim Installation Just Got Much SimplerDocument11 pagesGlomosim Installation Just Got Much SimplerT. M. KarthikeyanPas encore d'évaluation
- Roubleshooting: If You Want To: Then RunDocument36 pagesRoubleshooting: If You Want To: Then RunThomas A. EDISSONPas encore d'évaluation
- Field Communicator Recovery Utility System Software V3 XDocument6 pagesField Communicator Recovery Utility System Software V3 Xmeribout adelPas encore d'évaluation
- Lab 5.6.4: Installing A Driver: Estimated Time: 20 Minutes ObjectiveDocument2 pagesLab 5.6.4: Installing A Driver: Estimated Time: 20 Minutes ObjectiveHamzaSpahijaPas encore d'évaluation
- InstruCalc 7 Network Install InstructionsDocument11 pagesInstruCalc 7 Network Install Instructionsrathnam.pmPas encore d'évaluation
- Ignite BackupDocument7 pagesIgnite BackupAbhishek BarvePas encore d'évaluation
- 11 New Tips For Boosting Windows XP PerformanceDocument5 pages11 New Tips For Boosting Windows XP PerformanceBill PetriePas encore d'évaluation
- Optimization of The Computer and The SystemDocument7 pagesOptimization of The Computer and The SystemcncstepPas encore d'évaluation
- How To Recover UpdateDocument18 pagesHow To Recover UpdatefogstormPas encore d'évaluation
- ESA AsyncOS Upgrade and Troubleshoot Procedure - CiscoDocument5 pagesESA AsyncOS Upgrade and Troubleshoot Procedure - CiscoORLANDO GOZARPas encore d'évaluation
- SOS Install Problem FAQDocument10 pagesSOS Install Problem FAQjose angel luna trinidadPas encore d'évaluation
- Care and feeding of the Mach1 CNC systemDocument68 pagesCare and feeding of the Mach1 CNC systemDejan Filc JelacaPas encore d'évaluation
- Process Analysis Software: Installation and Soft Activation Standalone LicenseDocument22 pagesProcess Analysis Software: Installation and Soft Activation Standalone LicenseDavid GarciaPas encore d'évaluation
- Instalacija Tower Build 1350 I ArmCAD-A Build 1763 Na Win 7 x64 UltimateDocument2 pagesInstalacija Tower Build 1350 I ArmCAD-A Build 1763 Na Win 7 x64 UltimateNikola Zecevic100% (2)
- Inside Officescan 11 Service Pack 1 Upgrade DocumentationD'EverandInside Officescan 11 Service Pack 1 Upgrade DocumentationPas encore d'évaluation
- Make Your PC Stable and Fast: What Microsoft Forgot to Tell YouD'EverandMake Your PC Stable and Fast: What Microsoft Forgot to Tell YouÉvaluation : 4 sur 5 étoiles4/5 (1)
- How To Access SPP On KCDocument1 pageHow To Access SPP On KCliew99Pas encore d'évaluation
- 9092 - Tivoli - Flashcopy - Manager - Update - and - Demonstration PDFDocument36 pages9092 - Tivoli - Flashcopy - Manager - Update - and - Demonstration PDFliew99Pas encore d'évaluation
- Floor Load RequirementsDocument4 pagesFloor Load Requirementsliew99Pas encore d'évaluation
- HKPublic Routemap PDFDocument1 pageHKPublic Routemap PDFliew99Pas encore d'évaluation
- Iesrs 060Document20 pagesIesrs 060liew99Pas encore d'évaluation
- Form Sheeted It Opt DelDocument9 pagesForm Sheeted It Opt Delliew99Pas encore d'évaluation
- GPFS NSD Server Design and Tuning OptimizationDocument6 pagesGPFS NSD Server Design and Tuning Optimizationliew99Pas encore d'évaluation
- Containers Explained: An Easy, Lightweight Virtualized EnvironmentDocument25 pagesContainers Explained: An Easy, Lightweight Virtualized Environmentliew99Pas encore d'évaluation
- Shuttle Bus Collage PDFDocument3 pagesShuttle Bus Collage PDFliew99Pas encore d'évaluation
- Shuttle Bus CollageDocument3 pagesShuttle Bus Collageliew99Pas encore d'évaluation
- SONAS Security Strategy - SecurityDocument38 pagesSONAS Security Strategy - Securityliew99Pas encore d'évaluation
- Snmpmonitor Cluster JoinDocument1 pageSnmpmonitor Cluster Joinliew99Pas encore d'évaluation
- Configuring Authorized Keys For OpenSSHDocument3 pagesConfiguring Authorized Keys For OpenSSHliew99Pas encore d'évaluation
- Vsphere Esxi Vcenter Server 60 Setup Mscs PDFDocument32 pagesVsphere Esxi Vcenter Server 60 Setup Mscs PDFliew99Pas encore d'évaluation
- Vmdsbackup SHDocument5 pagesVmdsbackup SHliew99Pas encore d'évaluation
- Configure Distributed Monitor Email-Home Webex Remote AccessDocument6 pagesConfigure Distributed Monitor Email-Home Webex Remote Accessliew99Pas encore d'évaluation
- CVSTR 800Document16 pagesCVSTR 800liew99Pas encore d'évaluation
- Install/Upgrade Array Health Analyzer: Inaha010 - R001Document2 pagesInstall/Upgrade Array Health Analyzer: Inaha010 - R001liew99Pas encore d'évaluation
- Iesrs 010Document19 pagesIesrs 010liew99Pas encore d'évaluation
- Cable CX3-10c Data Ports To Switch Ports: cnspr170 - R001Document1 pageCable CX3-10c Data Ports To Switch Ports: cnspr170 - R001liew99Pas encore d'évaluation
- SLES 11 SP3 Plasma Cluster Setup Guide v1.0Document23 pagesSLES 11 SP3 Plasma Cluster Setup Guide v1.0C SanchezPas encore d'évaluation
- Pacemaker CookbookDocument4 pagesPacemaker Cookbookliew99Pas encore d'évaluation
- Cable CX600 SPs ports checkDocument1 pageCable CX600 SPs ports checkliew99Pas encore d'évaluation
- Cable CX3-20-Series Data Ports To Switch Ports: cnspr160 - R002Document1 pageCable CX3-20-Series Data Ports To Switch Ports: cnspr160 - R002liew99Pas encore d'évaluation
- Verify and Restore LUN OwnershipDocument1 pageVerify and Restore LUN Ownershipliew99Pas encore d'évaluation
- If Software Update Is Offline Due To ATA Chassis: Path ADocument7 pagesIf Software Update Is Offline Due To ATA Chassis: Path Aliew99Pas encore d'évaluation
- Prepare CX300, 500, 700, and CX3 Series For Update To Release 24 and AboveDocument15 pagesPrepare CX300, 500, 700, and CX3 Series For Update To Release 24 and Aboveliew99Pas encore d'évaluation
- Cable The CX3-20-Series Array To The LAN: Storage System Serial Number (See Note Below)Document2 pagesCable The CX3-20-Series Array To The LAN: Storage System Serial Number (See Note Below)liew99Pas encore d'évaluation
- Chapter 1 - Pic16f887 OverviewDocument38 pagesChapter 1 - Pic16f887 OverviewTung NguyenPas encore d'évaluation
- Elijan Lewis - Clean Architecture Advanced and Effective Strategies Using Clean Architecture Principles (2020)Document123 pagesElijan Lewis - Clean Architecture Advanced and Effective Strategies Using Clean Architecture Principles (2020)Martha Mattena100% (1)
- Report CcnaDocument4 pagesReport CcnaMary V. LopezPas encore d'évaluation
- Fix Command Not Found' Error On VirtualenvDocument2 pagesFix Command Not Found' Error On VirtualenvRahilPas encore d'évaluation
- 7 PDF - 7750 SR-e SERIES ARCHITECTURE AND HARDWARE OVERVIEWDocument20 pages7 PDF - 7750 SR-e SERIES ARCHITECTURE AND HARDWARE OVERVIEWEric OukoPas encore d'évaluation
- Name Description: The File FormatsDocument15 pagesName Description: The File FormatsTimematcherPas encore d'évaluation
- Olympus 07258-1 48.4Y603.0SADocument55 pagesOlympus 07258-1 48.4Y603.0SACarlosPas encore d'évaluation
- Zyxel Es-3124F V3.80 (Aiv.3) C0 Release Note/Manual SupplementDocument13 pagesZyxel Es-3124F V3.80 (Aiv.3) C0 Release Note/Manual SupplementTRỊNH VĂN THIỆNPas encore d'évaluation
- Solaris 11 Zones P3 Brands Templates BeadmDocument11 pagesSolaris 11 Zones P3 Brands Templates Beadms_mullickPas encore d'évaluation
- Ns 2 Manual For KarthikDocument33 pagesNs 2 Manual For Karthikchandru100% (1)
- Open Labs Production Station ManualDocument126 pagesOpen Labs Production Station ManualEduardo Soares GuiaPas encore d'évaluation
- Build Disaster Recovery for VMware & Physical Servers with Azure Site RecoveryDocument49 pagesBuild Disaster Recovery for VMware & Physical Servers with Azure Site Recoverymails4vipsPas encore d'évaluation
- Vishnu Vardhan Resume With RhceDocument3 pagesVishnu Vardhan Resume With RhcePankaj NinganiaPas encore d'évaluation
- CX Programmer Operation ManualDocument536 pagesCX Programmer Operation ManualVefik KaraegePas encore d'évaluation
- Manual-4 3Document288 pagesManual-4 3bobSponge1212Pas encore d'évaluation
- Micro Service ArchitectureDocument32 pagesMicro Service Architectureg007adam759Pas encore d'évaluation
- How to install Siae radio connection softwareDocument18 pagesHow to install Siae radio connection softwareguevaragus100% (2)
- Operating SystemDocument5 pagesOperating SystemAshok PandeyPas encore d'évaluation
- Reversing J2ME ApplicationsDocument9 pagesReversing J2ME Applicationsmanut1135xPas encore d'évaluation
- Bugreport mdh30xlm RKQ1.210420.001 2022 08 31 13 48 38 Dumpstate - Log 23668Document28 pagesBugreport mdh30xlm RKQ1.210420.001 2022 08 31 13 48 38 Dumpstate - Log 23668Edmond SainvalPas encore d'évaluation
- Labview Real-Time 2 Course Manual: SampleDocument17 pagesLabview Real-Time 2 Course Manual: Sampleanubhav yadavPas encore d'évaluation
- Ibm Thinkpad r52 Wistron y Note-6 Rev - 3 SCHDocument71 pagesIbm Thinkpad r52 Wistron y Note-6 Rev - 3 SCHJosé Nelson PatrícioPas encore d'évaluation
- Text FileDocument5 pagesText FileJaid KhanPas encore d'évaluation
- SureMDM LogDocument6 pagesSureMDM LogAditzPas encore d'évaluation
- ProjectResources SNA LBEFDocument8 pagesProjectResources SNA LBEFAaditya JhaPas encore d'évaluation
- Complete Kickstart: How to Save Time Installing LinuxDocument38 pagesComplete Kickstart: How to Save Time Installing LinuxUday ChoudharyPas encore d'évaluation
- Packet Sniffer in Python: Import SocketDocument9 pagesPacket Sniffer in Python: Import SocketRihab BenabdelazizPas encore d'évaluation
- Battery Firmware Hacking: Inside the InnardsDocument38 pagesBattery Firmware Hacking: Inside the InnardscooldamagePas encore d'évaluation
- AltconfigDocument20 pagesAltconfigRiteesh AgrawalPas encore d'évaluation
- SAP Data Archiving Open TextDocument5 pagesSAP Data Archiving Open TextSiva KumarPas encore d'évaluation