Vous aimerez peut-être aussi
- Quanto Options: Uwe Wystup Mathfinance Ag Waldems, GermanyDocument12 pagesQuanto Options: Uwe Wystup Mathfinance Ag Waldems, Germanyshubg87Pas encore d'évaluation
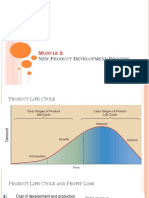
- Module 2Document7 pagesModule 2Jacob PopcornsPas encore d'évaluation
- Quantitative Methods 1 (Juice Notes)Document17 pagesQuantitative Methods 1 (Juice Notes)Paras Arora100% (1)
- Time SeriesDocument63 pagesTime SeriesMegan SpitzerPas encore d'évaluation
- Chapter 2 Market Demand AnalysisDocument58 pagesChapter 2 Market Demand Analysiswossen67% (3)
- Sales ForecastingDocument28 pagesSales ForecastingNash ArbilPas encore d'évaluation
- Sliding Controller Design For Non Linear SystemsDocument15 pagesSliding Controller Design For Non Linear SystemsBhaskar BiswasPas encore d'évaluation
- Part I: Time Series Forecasting ModelsDocument52 pagesPart I: Time Series Forecasting ModelsVenkat Vardhan100% (1)
- Lecture Note: Analysis of Financial Time SeriesDocument12 pagesLecture Note: Analysis of Financial Time Seriestestuser132546Pas encore d'évaluation
- Statistical ForecastingDocument328 pagesStatistical ForecastingRakyPas encore d'évaluation
- Hu - Time Series AnalysisDocument149 pagesHu - Time Series AnalysisMadMinarchPas encore d'évaluation
- Chapter 3Document48 pagesChapter 3RenithaTalariPas encore d'évaluation
- 1982 - Holographic Antenna Measurements Further Technical ConsiderationsDocument20 pages1982 - Holographic Antenna Measurements Further Technical Considerationszan wang100% (1)
- Analysis of Financial Time SeriesDocument13 pagesAnalysis of Financial Time SeriesZacharia Ombati NyabutoPas encore d'évaluation
- TS Chapter1Document8 pagesTS Chapter1Shahrukh Abdur RehmanPas encore d'évaluation
- Introduction To Time Series Analysis, LecturesDocument49 pagesIntroduction To Time Series Analysis, LecturesnumenorePas encore d'évaluation
- 1314sem1 ST3233Document13 pages1314sem1 ST3233jiashengroxPas encore d'évaluation
- Analisis de Series de Tiempo en R PDFDocument20 pagesAnalisis de Series de Tiempo en R PDFAndre Edy Ramos PeñaPas encore d'évaluation
- Stationarity, Non Stationarity, Unit Roots and Spurious RegressionDocument26 pagesStationarity, Non Stationarity, Unit Roots and Spurious RegressionNuur AhmedPas encore d'évaluation
- Formula SheetDocument15 pagesFormula Sheetsiddhartha-misra-1498Pas encore d'évaluation
- Persamaan TerbitanDocument31 pagesPersamaan TerbitanWan Habib100% (2)
- Calculating Double IntegralsDocument94 pagesCalculating Double IntegralsSameh HelmyPas encore d'évaluation
- PHY CK: Attern (Document5 pagesPHY CK: Attern (Pradyumna MukherjeePas encore d'évaluation
- Autoregressive Conditional Heteroskedasticity (ARCH) : Volatility ClusteringDocument9 pagesAutoregressive Conditional Heteroskedasticity (ARCH) : Volatility ClusteringLyana ZainolPas encore d'évaluation
- Assignment No 01Document2 pagesAssignment No 01mallikarjunbpatilPas encore d'évaluation
- Time Series AnalysisDocument66 pagesTime Series AnalysisShiv Ganesh SPas encore d'évaluation
- Econometrics Chapter 1 UNAVDocument38 pagesEconometrics Chapter 1 UNAVRachael VazquezPas encore d'évaluation
- X .% - y R N N+L n+1 N N+Z n+2 N x-1: Iterating The Product of Shifted DigitsDocument8 pagesX .% - y R N N+L n+1 N N+Z n+2 N x-1: Iterating The Product of Shifted DigitsCharlie PinedoPas encore d'évaluation
- Chapter 1 - Lecture SlidesDocument53 pagesChapter 1 - Lecture SlidesJoel Tan Yi JiePas encore d'évaluation
- A Generalization of The Stirling NumbersDocument11 pagesA Generalization of The Stirling Numbersdavid_bhattPas encore d'évaluation
- Chapter 02Document10 pagesChapter 02seanwu95Pas encore d'évaluation
- Wavelets: 1. A Brief Summary 2. Vanishing Moments 3. 2d-Wavelets 4. Compression 5. De-NoisingDocument24 pagesWavelets: 1. A Brief Summary 2. Vanishing Moments 3. 2d-Wavelets 4. Compression 5. De-Noisingac.diogo487Pas encore d'évaluation
- State Space AnalysisDocument26 pagesState Space AnalysisWilson TanPas encore d'évaluation
- 1 s2.0 S0166218X01003080 Main PDFDocument7 pages1 s2.0 S0166218X01003080 Main PDFLvaPas encore d'évaluation
- Zivot+Yollin R ForecastingDocument90 pagesZivot+Yollin R ForecastingLamchochiya MahaanPas encore d'évaluation
- SLV 2010 MerillLynchDocument77 pagesSLV 2010 MerillLynchStone SunPas encore d'évaluation
- Laplace BookDocument51 pagesLaplace BookAjankya SinghaniaPas encore d'évaluation
- Analytic Solution of Nonlinear Black-Scholes EquationDocument10 pagesAnalytic Solution of Nonlinear Black-Scholes Equationjawad HussainPas encore d'évaluation
- Chapter01 2130Document15 pagesChapter01 2130Ricardo Henrique BuzolinPas encore d'évaluation
- Ch7 1laplace Transform 1Document15 pagesCh7 1laplace Transform 1Meor AimanPas encore d'évaluation
- Signals and SystemsDocument37 pagesSignals and SystemsMadhu TellakuklaPas encore d'évaluation
- Transfer Matrix Method For Dual Chamber by MihaiDocument7 pagesTransfer Matrix Method For Dual Chamber by MihaiaruatscribdPas encore d'évaluation
- Proakis ProblemsDocument4 pagesProakis ProblemsJoonsung Lee0% (1)
- The Optimal Control Chart ProceduřeDocument10 pagesThe Optimal Control Chart ProceduřeAnonymous FfIxH2o9Pas encore d'évaluation
- Applied Time Series AnalysisDocument340 pagesApplied Time Series Analysisgenlovesmusic09Pas encore d'évaluation
- Kty 10Document11 pagesKty 10Adriana VasovićPas encore d'évaluation
- Asl FormDocument5 pagesAsl FormRicardo Rorry Salinas EscobarPas encore d'évaluation
- Lindberg1996 PDFDocument9 pagesLindberg1996 PDFMolinaEstefanyPas encore d'évaluation
- + 4 + 2 + I I 1 + I I 2 + 3: University of Santa Clara, Santa Clara CA 95053Document5 pages+ 4 + 2 + I I 1 + I I 2 + 3: University of Santa Clara, Santa Clara CA 95053Charlie PinedoPas encore d'évaluation
- Second-Order LTI Systems: T B T y K T y K T yDocument9 pagesSecond-Order LTI Systems: T B T y K T y K T ySonia Butt100% (1)
- Sandstorm Streaming Valuation - Connor HaleyDocument6 pagesSandstorm Streaming Valuation - Connor HaleyAAOI2Pas encore d'évaluation
- Evolutional Equations of Parabolic Type, Hiroki Tanabe, 1961Document4 pagesEvolutional Equations of Parabolic Type, Hiroki Tanabe, 1961Fis MatPas encore d'évaluation
- ': T:ffi N" ( (: ProbabilityDocument9 pages': T:ffi N" ( (: ProbabilityVibhorkmrPas encore d'évaluation
- Signal Processing Assignment: Donald Carr May 18, 2005Document39 pagesSignal Processing Assignment: Donald Carr May 18, 2005sshebiPas encore d'évaluation
- Nec 303Document4 pagesNec 303Jane MuliPas encore d'évaluation
- Ch7 Laplace TransformDocument15 pagesCh7 Laplace TransformumerPas encore d'évaluation
- The Precision Screw R-C - Brooks - 3-1989 - AppendixDocument442 pagesThe Precision Screw R-C - Brooks - 3-1989 - AppendixZyberstormPas encore d'évaluation
- rijketube_carrierDocument13 pagesrijketube_carrierShikshit NawaniPas encore d'évaluation
- DS1800 Temperature ScaleDocument12 pagesDS1800 Temperature Scalekishan1234Pas encore d'évaluation
- Mathematical Tables: Tables of in G [z] for Complex ArgumentD'EverandMathematical Tables: Tables of in G [z] for Complex ArgumentPas encore d'évaluation
- Ten-Decimal Tables of the Logarithms of Complex Numbers and for the Transformation from Cartesian to Polar Coordinates: Volume 33 in Mathematical Tables SeriesD'EverandTen-Decimal Tables of the Logarithms of Complex Numbers and for the Transformation from Cartesian to Polar Coordinates: Volume 33 in Mathematical Tables SeriesPas encore d'évaluation
- Tables of Coulomb Wave Functions: Whittaker FunctionsD'EverandTables of Coulomb Wave Functions: Whittaker FunctionsPas encore d'évaluation
- Ion Beams for Materials AnalysisD'EverandIon Beams for Materials AnalysisR. Curtis BirdPas encore d'évaluation
- Lesson 11Document45 pagesLesson 11Ashwani VermaPas encore d'évaluation
- Forecast F&N Share PriceDocument11 pagesForecast F&N Share PricePramget KaurPas encore d'évaluation
- Causal Inference in Empirical Archival Financial Accounting ResearchDocument27 pagesCausal Inference in Empirical Archival Financial Accounting Researchstudentul86Pas encore d'évaluation
- FALLSEM2019-20 MGT1035 TH VL2019201002844 Reference Material I 26-Jul-2019 Module 2Document93 pagesFALLSEM2019-20 MGT1035 TH VL2019201002844 Reference Material I 26-Jul-2019 Module 2Shivam KenchePas encore d'évaluation
- Time Series Analysis IntroductionDocument54 pagesTime Series Analysis IntroductionPrawan SinghPas encore d'évaluation
- Morgenstern Probabilistic Slope Stability Analysis For PracticeDocument19 pagesMorgenstern Probabilistic Slope Stability Analysis For PracticeburlandPas encore d'évaluation
- Forecast Calculations ExamplesDocument30 pagesForecast Calculations ExamplesFernando Sainz de AjaPas encore d'évaluation
- MTH302 Quiz3Document13 pagesMTH302 Quiz3shahaan786100% (4)
- Jo Wood (1996), The Geomorphological Characterisation of Digital Elevation ModelsDocument30 pagesJo Wood (1996), The Geomorphological Characterisation of Digital Elevation ModelsFlori PaizsPas encore d'évaluation
- Forecasting GDP Growth with Regression ModelsDocument28 pagesForecasting GDP Growth with Regression ModelsjyottsnaPas encore d'évaluation
- Recipes For State Space Models in R Paul TeetorDocument27 pagesRecipes For State Space Models in R Paul Teetoralexa_sherpyPas encore d'évaluation
- Cpa 4 Qa 2018Document364 pagesCpa 4 Qa 2018antony omondi100% (1)
- Qualitative ForecastDocument3 pagesQualitative Forecastermiyas tesfayePas encore d'évaluation
- Lab4 Orthogonal Contrasts and Multiple ComparisonsDocument14 pagesLab4 Orthogonal Contrasts and Multiple ComparisonsjorbelocoPas encore d'évaluation
- Past 3 ManualDocument225 pagesPast 3 ManualFrancisco Javier Parra NavarretePas encore d'évaluation
- TREND User GuideDocument29 pagesTREND User GuidekardraPas encore d'évaluation
- Mcgraw Hill/IrwinDocument28 pagesMcgraw Hill/IrwinJoel DwiyantoPas encore d'évaluation
- Capacity Planning A Case Study From Cigarette Production PDFDocument15 pagesCapacity Planning A Case Study From Cigarette Production PDFRizal Adiwangsa100% (1)
- 4 4Document14 pages4 4Fherry LeonheartPas encore d'évaluation
- Forecast Pro V8 Statistical Reference ManualDocument62 pagesForecast Pro V8 Statistical Reference Manualgacastroh81Pas encore d'évaluation
- ForcastingDocument85 pagesForcastingUcca AmandaPas encore d'évaluation
- Nureg-Cr-6823 HB Param EstDocument294 pagesNureg-Cr-6823 HB Param EstDennis BleyPas encore d'évaluation
- New CMA Part 1 Section ADocument114 pagesNew CMA Part 1 Section AMichael SumpayPas encore d'évaluation
- Curve FittingDocument48 pagesCurve FittingNi Putu Indira MelilaPas encore d'évaluation
- Navidi Ch07 4e Linear RegressionDocument68 pagesNavidi Ch07 4e Linear RegressionAmin ZaquanPas encore d'évaluation





























































![Mathematical Tables: Tables of in G [z] for Complex Argument](https://imgv2-1-f.scribdassets.com/img/word_document/282615796/149x198/febb728e8d/1699542561?v=1)