Vous aimerez peut-être aussi
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5795)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (74)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- Audit Checklist For ISO 13485Document6 pagesAudit Checklist For ISO 13485EdPas encore d'évaluation
- Audit Checklist For ISO 13485Document6 pagesAudit Checklist For ISO 13485EdPas encore d'évaluation
- Forecasting Sheet SoltionDocument10 pagesForecasting Sheet SoltionArun kumar rouniyar100% (1)
- Mapping Philippine Vulnerability To Environmental DisastersDocument16 pagesMapping Philippine Vulnerability To Environmental DisastersChristine De San JosePas encore d'évaluation
- Survival of The Fittest - The Process Control ImperativeDocument10 pagesSurvival of The Fittest - The Process Control ImperativeEdPas encore d'évaluation
- Zed Charts Compare Apples and Oranges: Wheeler's WorkshopDocument4 pagesZed Charts Compare Apples and Oranges: Wheeler's WorkshopEdPas encore d'évaluation
- 0.016 USL Process Is NOT StableDocument5 pages0.016 USL Process Is NOT StableEdPas encore d'évaluation
- Applied Technology: by John J. Flaig, PH.DDocument2 pagesApplied Technology: by John J. Flaig, PH.DEdPas encore d'évaluation
- Blind IdentDocument6 pagesBlind IdentEdPas encore d'évaluation
- Quality Human Per ForDocument8 pagesQuality Human Per ForEdPas encore d'évaluation
- Forecasting MethodsDocument30 pagesForecasting MethodsEdPas encore d'évaluation
- Short Run Statistical Process ControlDocument21 pagesShort Run Statistical Process ControlEdPas encore d'évaluation
- A Study of Q Chart For Short Run PDFDocument37 pagesA Study of Q Chart For Short Run PDFEd100% (1)
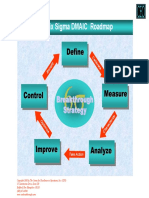
- The Six Sigma DMAIC Roadmap: DefineDocument1 pageThe Six Sigma DMAIC Roadmap: DefineEdPas encore d'évaluation
- Entropy: Increasing The Discriminatory Power of DEA Using Shannon's EntropyDocument15 pagesEntropy: Increasing The Discriminatory Power of DEA Using Shannon's EntropyEdPas encore d'évaluation
- Statistical Process Control FundamentalsDocument32 pagesStatistical Process Control FundamentalsEd100% (1)
- Tolerance Design Using Taguchi MethodsDocument30 pagesTolerance Design Using Taguchi MethodsEdPas encore d'évaluation
- Comparison Between Product Verification and TestingDocument1 pageComparison Between Product Verification and TestingEdPas encore d'évaluation
- Lean Six Sigma Project Charter: Title: Reduce Scrapped Cookies in NW Region BB/GB: B. ThorntonDocument2 pagesLean Six Sigma Project Charter: Title: Reduce Scrapped Cookies in NW Region BB/GB: B. ThorntonEdPas encore d'évaluation
- LSS Final - Report - TemplateDocument9 pagesLSS Final - Report - TemplateEdPas encore d'évaluation
- ApqpDocument11 pagesApqpEdPas encore d'évaluation
- SPC For Correlated Variables PDFDocument15 pagesSPC For Correlated Variables PDFEdPas encore d'évaluation
- Unit: 1 Introduction To Artificial Intelligence and Machine LearningDocument17 pagesUnit: 1 Introduction To Artificial Intelligence and Machine LearningAdnankhanPas encore d'évaluation
- #Book Sumarry Final Exam 3rd SemesterDocument73 pages#Book Sumarry Final Exam 3rd SemesterChusnul AnisaPas encore d'évaluation
- Riyadh WeatherDocument9 pagesRiyadh WeatherSiva SubramaniyanPas encore d'évaluation
- ForecastingDocument82 pagesForecastingYasser IsteitiehPas encore d'évaluation
- Geography 3º E.S.O. Teacher Ms. IsabelDocument26 pagesGeography 3º E.S.O. Teacher Ms. IsabelElisaPas encore d'évaluation
- Extraction of Natural Dye From Flame of Forest Flower: Artificial Neural Network ApproachDocument5 pagesExtraction of Natural Dye From Flame of Forest Flower: Artificial Neural Network ApproachSEP-PublisherPas encore d'évaluation
- Ordinary Kriging RDocument19 pagesOrdinary Kriging Rdisgusting4all100% (1)
- Be Going To and Will: Unit GoalsDocument14 pagesBe Going To and Will: Unit GoalsWilliams M. Gamarra ArateaPas encore d'évaluation
- DepressionDocument72 pagesDepressionMahdi Bordbar100% (2)
- Current Korea Weather ConditionsDocument3 pagesCurrent Korea Weather ConditionsBernard OrtineroPas encore d'évaluation
- Module Week 2 Identifying The Genre of A Material Viewed: Questions Video 1 Video 2Document2 pagesModule Week 2 Identifying The Genre of A Material Viewed: Questions Video 1 Video 2Jerra Ballesteros100% (3)
- Digital Twin GOODDocument31 pagesDigital Twin GOODrahulPas encore d'évaluation
- ESOL - FCE - Use of English 6 With AnswersDocument5 pagesESOL - FCE - Use of English 6 With AnswersBenjamin Ford50% (2)
- Hurricane Prediction ReportDocument12 pagesHurricane Prediction Reportapi-202492975Pas encore d'évaluation
- LiteraryanalysisDocument5 pagesLiteraryanalysisapi-363545415Pas encore d'évaluation
- IELTS Weather Vocabulary PDFDocument3 pagesIELTS Weather Vocabulary PDFArthur GTPas encore d'évaluation
- Rock Strength Parameters From Annular Pressure While Drilling and Dipole Sonic Dispersion AnalysisDocument14 pagesRock Strength Parameters From Annular Pressure While Drilling and Dipole Sonic Dispersion Analysisfajar agung setiawanPas encore d'évaluation
- Baba Vanga: M.Padmasree (Ece 1 Year)Document2 pagesBaba Vanga: M.Padmasree (Ece 1 Year)SanthoshiniRajanPas encore d'évaluation
- Weather Forecast - December 16, 2022 (FRIDAY)Document2 pagesWeather Forecast - December 16, 2022 (FRIDAY)John RamosPas encore d'évaluation
- The Future Tenses, Theory and PracticeDocument3 pagesThe Future Tenses, Theory and PracticeNatalia Cuevas MoralesPas encore d'évaluation
- Bengtsson 2006Document26 pagesBengtsson 2006milk1milk2milk3Pas encore d'évaluation
- Learn More: National Weather ServiceDocument2 pagesLearn More: National Weather Servicedamien boyerPas encore d'évaluation
- VAR, VECM, Impulse Response TheoryDocument12 pagesVAR, VECM, Impulse Response Theorysaeed meo100% (4)
- QUARTER 2 LESSON 5 Pathway of TyphoonDocument17 pagesQUARTER 2 LESSON 5 Pathway of TyphoonJose BundalianPas encore d'évaluation
- I. The Skew-T, Log-P DiagramDocument33 pagesI. The Skew-T, Log-P DiagramkicikibumPas encore d'évaluation
- Bài Tập Thì Tương Lai Đơn Tương Lai GầnDocument3 pagesBài Tập Thì Tương Lai Đơn Tương Lai GầnGút SuPas encore d'évaluation
- FEMA National Warning OpsDocument95 pagesFEMA National Warning OpsjustanothergunnutPas encore d'évaluation
- Lectures 5, 6Document22 pagesLectures 5, 6idleyouthPas encore d'évaluation