Vous aimerez peut-être aussi
- Automata, Grammars and Languages: Example: We describe a finite state machine with two input symbols (σ, σ) ,Document4 pagesAutomata, Grammars and Languages: Example: We describe a finite state machine with two input symbols (σ, σ) ,Joanna Mary LopezPas encore d'évaluation
- Finite State Machines With Output (Mealy and Moore Machines)Document17 pagesFinite State Machines With Output (Mealy and Moore Machines)Satish AripakaPas encore d'évaluation
- Iq AsmDocument5 pagesIq AsmalbertPas encore d'évaluation
- Algorithmic State Machine (ASM) : UnitDocument10 pagesAlgorithmic State Machine (ASM) : Unitateeq mughalPas encore d'évaluation
- FA Transition GraphsDocument9 pagesFA Transition Graphsadeelmurtaza5730Pas encore d'évaluation
- Lecture 4Document44 pagesLecture 4suitunivPas encore d'évaluation
- Asm 1Document5 pagesAsm 1Jagan RajendiranPas encore d'évaluation
- Unit - 1 DSDDocument56 pagesUnit - 1 DSDultimatekp144Pas encore d'évaluation
- Lab 11Document3 pagesLab 11Ab AbPas encore d'évaluation
- Week 12 - Module 10 Finite State Machines 1Document7 pagesWeek 12 - Module 10 Finite State Machines 1Ben GwenPas encore d'évaluation
- Finite State MachinesDocument16 pagesFinite State MachinesAKASH PALPas encore d'évaluation
- 14 Finite StateDocument35 pages14 Finite Statenani10Pas encore d'évaluation
- FSM Worksheet PDFDocument8 pagesFSM Worksheet PDFabuzar raoPas encore d'évaluation
- Sequential Mealy Machines VHDLSession8 EnotesDocument16 pagesSequential Mealy Machines VHDLSession8 EnotessaravananpaulchamyPas encore d'évaluation
- Finite State MachinesDocument21 pagesFinite State MachinesHayan FadhilPas encore d'évaluation
- FSM SlidesDocument37 pagesFSM SlidesSahil Sharma0% (1)
- Switching and Finite Automata Theory, 3rd Ed by Kohavi, K. Jha Sample From Ch10Document3 pagesSwitching and Finite Automata Theory, 3rd Ed by Kohavi, K. Jha Sample From Ch10alberteinstein407Pas encore d'évaluation
- Asgnmt6 (522) Tawab SirDocument11 pagesAsgnmt6 (522) Tawab SirDil NawazPas encore d'évaluation
- The Synthesis of Finite State Machines by Using A Combined Meely and Moore ModelDocument6 pagesThe Synthesis of Finite State Machines by Using A Combined Meely and Moore ModelValery SalauyouPas encore d'évaluation
- Automata Moore MealyMachineDocument6 pagesAutomata Moore MealyMachineratna.patilPas encore d'évaluation
- 2 Chapter 12 Algorithmic State MachineDocument16 pages2 Chapter 12 Algorithmic State MachinekaosadPas encore d'évaluation
- Computer - New - Automata Theory Lecture 6 Equivalence and Reduction of Finite State MachinesDocument35 pagesComputer - New - Automata Theory Lecture 6 Equivalence and Reduction of Finite State MachinesBolarinwa OwuogbaPas encore d'évaluation
- VHDL FSM UNIT 5 ET&T 7th SemDocument22 pagesVHDL FSM UNIT 5 ET&T 7th SemDEEPA KUNWARPas encore d'évaluation
- Warford Fig 7 17Document4 pagesWarford Fig 7 17Abhaydeep singhPas encore d'évaluation
- Sample Q. PaperDocument3 pagesSample Q. PaperApoorv SinghPas encore d'évaluation
- MIT6004 S 09 Tutor 07 SolDocument15 pagesMIT6004 S 09 Tutor 07 SolAbhijith RanguduPas encore d'évaluation
- HOMEWORK 5 Solution: ICS 151 - Digital Logic DesignDocument10 pagesHOMEWORK 5 Solution: ICS 151 - Digital Logic DesignWindy Ford100% (1)
- 10 1 1 37 307Document50 pages10 1 1 37 307Oluponmile AdeolaPas encore d'évaluation
- FSMsDocument15 pagesFSMsSANDEEP KUMARPas encore d'évaluation
- Unit 6 - FinalDocument24 pagesUnit 6 - Finalsuniljain007Pas encore d'évaluation
- LECTURE B 1 FSM Minimization IntroDocument18 pagesLECTURE B 1 FSM Minimization IntroSathish KumarPas encore d'évaluation
- Automata & Complexity Theory Cosc3025: Chapter OneDocument27 pagesAutomata & Complexity Theory Cosc3025: Chapter Oneabebaw atalelePas encore d'évaluation
- Quiz 6 SolutionsDocument9 pagesQuiz 6 SolutionsAmreshAmanPas encore d'évaluation
- DD Slides6Document57 pagesDD Slides6tanay.s1Pas encore d'évaluation
- Finite State Machines (FSMS)Document16 pagesFinite State Machines (FSMS)Nithin KumarPas encore d'évaluation
- 101 2 Digitalsystems Chap 05 2Document34 pages101 2 Digitalsystems Chap 05 2thivyadharshiniPas encore d'évaluation
- Moore Mealy Machine Lecture-1Document15 pagesMoore Mealy Machine Lecture-1ali yousafPas encore d'évaluation
- Moore Mealy Machine Lecture-1Document15 pagesMoore Mealy Machine Lecture-1ali yousafPas encore d'évaluation
- LECTURE B 1 FSM Minimization IntroDocument18 pagesLECTURE B 1 FSM Minimization IntroBharadwaja PisupatiPas encore d'évaluation
- Info 2950 FSM Part1Document29 pagesInfo 2950 FSM Part1John SmithPas encore d'évaluation
- Slides-L6 4up PsDocument2 pagesSlides-L6 4up PsHussain52532012Pas encore d'évaluation
- Maths Turing MachinesDocument5 pagesMaths Turing MachinesBhasinee ManagePas encore d'évaluation
- Finite State MachinesDocument8 pagesFinite State MachinesHnd FinalPas encore d'évaluation
- Implementing FSM VerilogDocument8 pagesImplementing FSM VerilogAdil AhmedPas encore d'évaluation
- Auto Mata Chapter6Document24 pagesAuto Mata Chapter6MypdfsitePas encore d'évaluation
- FSM LinhbunddddDocument13 pagesFSM LinhbunddddlinhddddPas encore d'évaluation
- Use of Genetic Algorithm To Resolve The Problem of Finite State Machine ConstructionDocument18 pagesUse of Genetic Algorithm To Resolve The Problem of Finite State Machine ConstructionDevendra SharmaPas encore d'évaluation
- Chapter Two Regular ExpressionDocument41 pagesChapter Two Regular Expressionhachalu50Pas encore d'évaluation
- Digital Circuits - Finite State MachinesDocument3 pagesDigital Circuits - Finite State Machinesyasar saleemPas encore d'évaluation
- Moore and Mearly MachineDocument65 pagesMoore and Mearly MachineJibran ElahiPas encore d'évaluation
- Finite Automata With Output: Lecture ObjectiveDocument6 pagesFinite Automata With Output: Lecture ObjectiveAyazPas encore d'évaluation
- Recap Lecture 20: Recap Theorem, Example, Finite Automaton With Output, Moore Machine, ExamplesDocument22 pagesRecap Lecture 20: Recap Theorem, Example, Finite Automaton With Output, Moore Machine, ExamplesMuhammad SaifalPas encore d'évaluation
- FSM DesignDocument24 pagesFSM DesignNazim Ali100% (1)
- Specification Journal 014: 3.4.2 Finite State MachinesDocument4 pagesSpecification Journal 014: 3.4.2 Finite State MachinesSyamkumar Manikonda.v.jPas encore d'évaluation
- CS2001 Week 3 Tutorial: Finite State SystemsDocument1 pageCS2001 Week 3 Tutorial: Finite State SystemsAbhishek GambhirPas encore d'évaluation
- Lab Session # 9 Finite State Machines (FSMS) : W), and Produces A Set of Outputs (Z)Document7 pagesLab Session # 9 Finite State Machines (FSMS) : W), and Produces A Set of Outputs (Z)Ahmad M. HammadPas encore d'évaluation
- An Iot Based Smart Energy Management of Hvac SystemDocument9 pagesAn Iot Based Smart Energy Management of Hvac SystemRagini GuptaPas encore d'évaluation
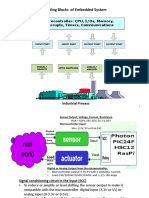
- Basic Building Blocks of Embedded System: Microcontroller: CPU, I/Os, Memory, Interrupts, Timers, CommunicationsDocument23 pagesBasic Building Blocks of Embedded System: Microcontroller: CPU, I/Os, Memory, Interrupts, Timers, CommunicationsRagini GuptaPas encore d'évaluation
- Code-Based Testing of Extended Finite State Machine Models - PPT - v4Document36 pagesCode-Based Testing of Extended Finite State Machine Models - PPT - v4Ragini GuptaPas encore d'évaluation
- Camera PresentationDocument11 pagesCamera PresentationRagini GuptaPas encore d'évaluation
- 7-Raspberry Pi Camera Interface-Final PDFDocument27 pages7-Raspberry Pi Camera Interface-Final PDFRagini Gupta100% (1)
- AR-Raspberry Pi Slides CompleteDocument21 pagesAR-Raspberry Pi Slides CompleteRagini GuptaPas encore d'évaluation
- 02 PIC ADC Final PDFDocument68 pages02 PIC ADC Final PDFRagini GuptaPas encore d'évaluation
- 03 Timers Slides PDFDocument69 pages03 Timers Slides PDFRagini GuptaPas encore d'évaluation
- Algorithms: The Basic Methods Instance-Based Learning: Data ScienceDocument17 pagesAlgorithms: The Basic Methods Instance-Based Learning: Data ScienceRagini GuptaPas encore d'évaluation
- Running Head: Are Cell Phones Modern-Day Drugs Amoung Students? 1Document13 pagesRunning Head: Are Cell Phones Modern-Day Drugs Amoung Students? 1Ragini GuptaPas encore d'évaluation
- Solution 1 - DFADocument5 pagesSolution 1 - DFARagini GuptaPas encore d'évaluation
- Running Head: Cell Phones Drugs Amoung Students 1Document12 pagesRunning Head: Cell Phones Drugs Amoung Students 1Ragini GuptaPas encore d'évaluation
- RF Engineer - Small Cell Design (Ibwave) - Job DescriptionDocument2 pagesRF Engineer - Small Cell Design (Ibwave) - Job Descriptionmansoor 31 shaikhPas encore d'évaluation
- Common Examples and Applications of Copolymers. Acrylonitrile Butadiene Styrene (ABS)Document4 pagesCommon Examples and Applications of Copolymers. Acrylonitrile Butadiene Styrene (ABS)Yashi SrivastavaPas encore d'évaluation
- Certification For 4 Hyton Crescent, KewDocument1 pageCertification For 4 Hyton Crescent, KewWaelElMeligiPas encore d'évaluation
- Design Report For Proposed 3storied ResidentialbuildingDocument35 pagesDesign Report For Proposed 3storied ResidentialbuildingMohamed RinosPas encore d'évaluation
- YWNC Piranhas Individual Meet Results - Standard: TUSSDocument12 pagesYWNC Piranhas Individual Meet Results - Standard: TUSSymcawncPas encore d'évaluation
- ELEG 270 Electronics: Dr. Ali BostaniDocument25 pagesELEG 270 Electronics: Dr. Ali BostanigigiPas encore d'évaluation
- Johnloomis Org Ece563 Notes Geom Resize ImresizeDocument10 pagesJohnloomis Org Ece563 Notes Geom Resize ImresizeAdrian Jose Costa OspinoPas encore d'évaluation
- Zener DiodeDocument3 pagesZener DiodeAde MurtalaPas encore d'évaluation
- SWP Grinder Bench AS520Document1 pageSWP Grinder Bench AS520Tosif AliPas encore d'évaluation
- IEEE Recommended Practice For Exc. Sys Models 2Document4 pagesIEEE Recommended Practice For Exc. Sys Models 2Emmanuel ZamoranoPas encore d'évaluation
- Little Book of RubyDocument104 pagesLittle Book of RubynoboPas encore d'évaluation
- In ThoseDocument2 pagesIn ThoseanggiePas encore d'évaluation
- CFRD 05 - BayardoDocument23 pagesCFRD 05 - BayardodiegofernandodiazsepPas encore d'évaluation
- KX Tde600 FeatureDocument460 pagesKX Tde600 Featureabg121Pas encore d'évaluation
- Uncoated SteelDocument2 pagesUncoated SteelBui Chi TamPas encore d'évaluation
- Specification For Piping MaterialDocument9 pagesSpecification For Piping MaterialAgus SupriadiPas encore d'évaluation
- Plan Holders ReportDocument8 pagesPlan Holders ReportSusan KunklePas encore d'évaluation
- Electric Power TransmissionDocument16 pagesElectric Power Transmissionsattar28Pas encore d'évaluation
- br604 PDFDocument5 pagesbr604 PDFmartinpellsPas encore d'évaluation
- FrictionDocument4 pagesFrictionMuzafar ahmadPas encore d'évaluation
- Crystal StructuresDocument54 pagesCrystal StructuresyashvantPas encore d'évaluation
- Institute of Technology & Engineering, Malegaon BK.: Lesson Teaching Plan (LTP)Document3 pagesInstitute of Technology & Engineering, Malegaon BK.: Lesson Teaching Plan (LTP)Pramod DhaigudePas encore d'évaluation
- Design of Well FoundationDocument31 pagesDesign of Well FoundationAshish Karki97% (32)
- Redseer Consulting Report On Vernacular LanguagesDocument36 pagesRedseer Consulting Report On Vernacular LanguagesMalavika SivagurunathanPas encore d'évaluation
- Articles TurbineDocument442 pagesArticles TurbineKevin RichardPas encore d'évaluation
- Huawei Antenna and Antenna Line Products Catalogue (General Version) 2014 01 (20131228)Document380 pagesHuawei Antenna and Antenna Line Products Catalogue (General Version) 2014 01 (20131228)Rizky JuliadiPas encore d'évaluation
- Cable Ties CatalogDocument60 pagesCable Ties CatalogRvPas encore d'évaluation
- LogcatDocument3 139 pagesLogcatvatsavai swathiPas encore d'évaluation
- BMW COMMON RAIL Injection Systems PDFDocument22 pagesBMW COMMON RAIL Injection Systems PDFEnd1y1Pas encore d'évaluation
- Larsen and Toubro RVNL Bid Document Rock Bolts PDFDocument240 pagesLarsen and Toubro RVNL Bid Document Rock Bolts PDFSubhash Kedia100% (1)