Vous aimerez peut-être aussi
- Chapter 5 - Forecasting PDFDocument80 pagesChapter 5 - Forecasting PDFUlaş GüllenoğluPas encore d'évaluation
- Venture Mathematics Worksheets: Bk. A: Algebra and Arithmetic: Blackline masters for higher ability classes aged 11-16D'EverandVenture Mathematics Worksheets: Bk. A: Algebra and Arithmetic: Blackline masters for higher ability classes aged 11-16Pas encore d'évaluation
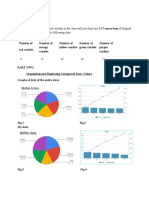
- Statistics Project 17Document13 pagesStatistics Project 17api-271978152Pas encore d'évaluation
- 15 The Welding Simulation Solution GuidelinesDocument152 pages15 The Welding Simulation Solution GuidelinesFelipe ArcePas encore d'évaluation
- Bayes TheoremDocument11 pagesBayes Theoremdhiec100% (2)
- Hypothesis Testing AssignmentDocument12 pagesHypothesis Testing Assignmentضیاء گل مروتPas encore d'évaluation
- Statistics Final Project Summer Semester 2016Document17 pagesStatistics Final Project Summer Semester 2016api-295161880Pas encore d'évaluation
- Total Chloride in Alumina Supported Catalysts by Wavelength Dispersive X-Ray FluorescenceDocument5 pagesTotal Chloride in Alumina Supported Catalysts by Wavelength Dispersive X-Ray FluorescenceJesus Gonzalez GracidaPas encore d'évaluation
- Classification of Educational ResearchDocument60 pagesClassification of Educational ResearchMuhammad Hidayatul Rifqi67% (9)
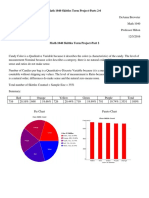
- Kassem Hajj: Math 1040 Skittles Term ProjectDocument10 pagesKassem Hajj: Math 1040 Skittles Term Projectapi-240347922Pas encore d'évaluation
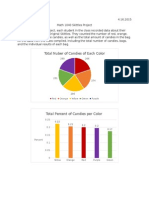
- Skittles Project 1Document7 pagesSkittles Project 1api-299868669100% (2)
- Skittles ProDocument9 pagesSkittles Proapi-241124972Pas encore d'évaluation
- Skittles Project Math 1030Document9 pagesSkittles Project Math 1030api-305867098Pas encore d'évaluation
- Final Math ProjectDocument7 pagesFinal Math Projectapi-316775963Pas encore d'évaluation
- Skittles Project Part 7Document4 pagesSkittles Project Part 7api-454435360Pas encore d'évaluation
- Math 1040 Statistics Term Project: Blake FreemanDocument10 pagesMath 1040 Statistics Term Project: Blake Freemanapi-252919218Pas encore d'évaluation
- Skittles Project FinalDocument5 pagesSkittles Project Finalapi-271348941Pas encore d'évaluation
- Dulces Math 1040Document6 pagesDulces Math 1040api-242193187Pas encore d'évaluation
- Skittles Statistics ProjectDocument9 pagesSkittles Statistics Projectapi-325825295Pas encore d'évaluation
- The Rainbow ReportDocument11 pagesThe Rainbow Reportapi-316991888Pas encore d'évaluation
- Skittle Pareto ChartDocument7 pagesSkittle Pareto Chartapi-272391081Pas encore d'évaluation
- Skittles WordDocument5 pagesSkittles Wordapi-285645725Pas encore d'évaluation
- Math 1040 Skittles Term ProjectDocument9 pagesMath 1040 Skittles Term Projectapi-319881085Pas encore d'évaluation
- Math Project Part B With ConclusionDocument5 pagesMath Project Part B With Conclusionapi-273321131Pas encore d'évaluation
- Emily Gregorio Skittles Project FinalDocument3 pagesEmily Gregorio Skittles Project Finalapi-288933258Pas encore d'évaluation
- Math Skittles Term Project-1Document6 pagesMath Skittles Term Project-1api-241771020Pas encore d'évaluation
- Math 1040 ProjectDocument8 pagesMath 1040 Projectapi-388517702Pas encore d'évaluation
- Math 1040 Term ProjectDocument7 pagesMath 1040 Term Projectapi-340188424Pas encore d'évaluation
- Skittles ProjectDocument9 pagesSkittles Projectapi-242873849Pas encore d'évaluation
- Skittles Project 2Document10 pagesSkittles Project 2api-316655135Pas encore d'évaluation
- Skittles ReportDocument15 pagesSkittles Reportapi-271901299Pas encore d'évaluation
- StatsfinalprojectDocument7 pagesStatsfinalprojectapi-325102852Pas encore d'évaluation
- Skittles ProjectDocument5 pagesSkittles Projectapi-441660843Pas encore d'évaluation
- Term Project SkittlesDocument4 pagesTerm Project Skittlesapi-356003029Pas encore d'évaluation
- Math 1040 Final ProjectDocument3 pagesMath 1040 Final Projectapi-285380759Pas encore d'évaluation
- Term Project Part 8Document9 pagesTerm Project Part 8api-242224172Pas encore d'évaluation
- Final ProjectDocument6 pagesFinal Projectapi-283261340Pas encore d'évaluation
- Final Stats ProjectDocument8 pagesFinal Stats Projectapi-238717717100% (2)
- Skittles Project Part 1Document6 pagesSkittles Project Part 1api-457501806Pas encore d'évaluation
- SkittlesdataclassprojectDocument8 pagesSkittlesdataclassprojectapi-399586872Pas encore d'évaluation
- Skittles Term ProjectDocument10 pagesSkittles Term Projectapi-273060240Pas encore d'évaluation
- SkittlesDocument7 pagesSkittlesapi-244615173Pas encore d'évaluation
- EportfolioDocument12 pagesEportfolioapi-251934892Pas encore d'évaluation
- Skittle ProjectDocument6 pagesSkittle Projectapi-535482544Pas encore d'évaluation
- Skittles Term Project - Kai Galbiso Stat1040Document6 pagesSkittles Term Project - Kai Galbiso Stat1040api-316758771Pas encore d'évaluation
- Skittles Term Project StatsDocument8 pagesSkittles Term Project Statsapi-302549779Pas encore d'évaluation
- Final ProjectDocument3 pagesFinal Projectapi-265661554Pas encore d'évaluation
- Pie Chart For The ProjectDocument7 pagesPie Chart For The Projectapi-325968264Pas encore d'évaluation
- Skittles Proyect Part 5Document7 pagesSkittles Proyect Part 5api-509398997Pas encore d'évaluation
- Skittles Term Project 1-6Document10 pagesSkittles Term Project 1-6api-284733808Pas encore d'évaluation
- TP 2 StatsDocument5 pagesTP 2 Statsapi-240850453Pas encore d'évaluation
- Stats Semester ProjectDocument11 pagesStats Semester Projectapi-276989071Pas encore d'évaluation
- 1040 Skittles ProjectDocument4 pages1040 Skittles Projectapi-279941094Pas encore d'évaluation
- Skittles ProjectDocument9 pagesSkittles Projectapi-252747849Pas encore d'évaluation
- The Skittles Project FinalDocument8 pagesThe Skittles Project Finalapi-316760667Pas encore d'évaluation
- Final ProjectDocument9 pagesFinal Projectapi-262329757Pas encore d'évaluation
- Skittles Project Math 1040Document8 pagesSkittles Project Math 1040api-495044194Pas encore d'évaluation
- Skittles ProjectDocument4 pagesSkittles Projectapi-287735026Pas encore d'évaluation
- Skittles Group E-PortfolioDocument9 pagesSkittles Group E-Portfolioapi-253834649Pas encore d'évaluation
- Skittles Project Stats 1040Document8 pagesSkittles Project Stats 1040api-301336765Pas encore d'évaluation
- Skittle Term ProjectDocument15 pagesSkittle Term Projectapi-260271892Pas encore d'évaluation
- Stats StuffDocument7 pagesStats Stuffapi-242298926Pas encore d'évaluation
- Term Project ReportDocument9 pagesTerm Project Reportapi-238585685Pas encore d'évaluation
- Skittles Term Project 11 9 14Document5 pagesSkittles Term Project 11 9 14api-192489685Pas encore d'évaluation
- Term Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1Document8 pagesTerm Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1api-303044832Pas encore d'évaluation
- Research Methods in Education Research Methods in Education: Dr. Zaheer Ahmad Dr. Zaheer AhmadDocument22 pagesResearch Methods in Education Research Methods in Education: Dr. Zaheer Ahmad Dr. Zaheer AhmadNoumanKabirPas encore d'évaluation
- Statistics and ProbabilityDocument12 pagesStatistics and Probability11 ICT-2 ESPADA JR., NOEL A.Pas encore d'évaluation
- Research DesignDocument35 pagesResearch DesignHruday ChandPas encore d'évaluation
- Varela 1999 - First-Person MethodsDocument12 pagesVarela 1999 - First-Person MethodsEliana ReisPas encore d'évaluation
- ANOVA T - TestDocument19 pagesANOVA T - Testmilrosebatilo2012Pas encore d'évaluation
- Kuhfeld (2010) Discrete Choice - mr2010fDocument379 pagesKuhfeld (2010) Discrete Choice - mr2010fMargalidaPas encore d'évaluation
- Estimation of ParametersDocument37 pagesEstimation of ParametersReflecta123Pas encore d'évaluation
- The M4 Competition-100,000 Time Series and 61 Forecasting Methods PDFDocument21 pagesThe M4 Competition-100,000 Time Series and 61 Forecasting Methods PDFUmer QamaruddinPas encore d'évaluation
- Final LAS 13 16 Methods of ResearchDocument6 pagesFinal LAS 13 16 Methods of ResearchprintsbyarishaPas encore d'évaluation
- The Significance of Critical Thinking Liz G. Ammerman SOC 213-620 Ms. Jacque Freeman September 15, 2010Document5 pagesThe Significance of Critical Thinking Liz G. Ammerman SOC 213-620 Ms. Jacque Freeman September 15, 2010Liz Lewis-AmmermanPas encore d'évaluation
- NAVEED StatisticsDocument4 pagesNAVEED Statisticsyusha habibPas encore d'évaluation
- Assignment / Tugasan - Marketing ResearchDocument12 pagesAssignment / Tugasan - Marketing ResearchzabedahibrahimPas encore d'évaluation
- 01 - IE3120 Forecasting HandoutDocument29 pages01 - IE3120 Forecasting HandoutGabrielPas encore d'évaluation
- Action Research ManualDocument6 pagesAction Research ManualKevin Rey CaballedaPas encore d'évaluation
- Physical GeographyDocument10 pagesPhysical GeographyRafael Getsemani Oseguera MarroquínPas encore d'évaluation
- Introduction To BRMDocument3 pagesIntroduction To BRMAnubin SajiPas encore d'évaluation
- Loyalty Pada Konsumen Pertamax/ Pertamax Plus Di KotaDocument15 pagesLoyalty Pada Konsumen Pertamax/ Pertamax Plus Di KotaradityawillmanPas encore d'évaluation
- Module 1 ITE Elective 1 New - CurriculumDocument10 pagesModule 1 ITE Elective 1 New - CurriculumGarry PenoliarPas encore d'évaluation
- BM AssignmentDocument6 pagesBM AssignmentAsifa YounasPas encore d'évaluation
- Full Download Test Bank For Essential Environment The Science Behind The Stories 4th Edition Withgott PDF Full ChapterDocument27 pagesFull Download Test Bank For Essential Environment The Science Behind The Stories 4th Edition Withgott PDF Full Chaptermilreis.cunettew2ncs100% (15)
- An Introduction To Meta-Analysis: Statistics For ResearchersDocument8 pagesAn Introduction To Meta-Analysis: Statistics For ResearchersPROF. ERWIN M. GLOBIO, MSITPas encore d'évaluation
- Physics: Teacher Guide Grade 11Document168 pagesPhysics: Teacher Guide Grade 11DanielPas encore d'évaluation
- Quantitative Methods Problems Explanation 11 20 2012Document13 pagesQuantitative Methods Problems Explanation 11 20 2012jmo502100% (7)