Vous aimerez peut-être aussi
- Past Paper 2019Document7 pagesPast Paper 2019Choco CheapPas encore d'évaluation
- Exercise 1 Multiple Regression ModelDocument6 pagesExercise 1 Multiple Regression ModelCarlos Villa AlonsoPas encore d'évaluation
- TextbookQuestionsChap 2Document7 pagesTextbookQuestionsChap 2Eddy CheungPas encore d'évaluation
- Econometrics Problem Set 1Document4 pagesEconometrics Problem Set 1wazaawazaaPas encore d'évaluation
- Problem Set 5Document5 pagesProblem Set 5Sila KapsataPas encore d'évaluation
- Ekonometrika Modellərinin TəhliliDocument16 pagesEkonometrika Modellərinin TəhliliPaul Davis0% (1)
- Midterm 1a SolutionsDocument9 pagesMidterm 1a Solutionskyle.krist13Pas encore d'évaluation
- MA Econometrics II Midterm 2018Document3 pagesMA Econometrics II Midterm 2018akshay patriPas encore d'évaluation
- Fundamental Concepts of Probability and StatisticsDocument3 pagesFundamental Concepts of Probability and StatisticsValentina VelozaPas encore d'évaluation
- Econometrics Assignment 1Document3 pagesEconometrics Assignment 1Peter Chenza50% (2)
- Mid Term UmtDocument4 pagesMid Term Umtfazalulbasit9796Pas encore d'évaluation
- Practice Exam 3 - Fall 2009 - With AnswersDocument6 pagesPractice Exam 3 - Fall 2009 - With AnswerszachPas encore d'évaluation
- Exercise 1Document5 pagesExercise 1Lemi Taye0% (1)
- Past Paper 2015Document7 pagesPast Paper 2015Choco CheapPas encore d'évaluation
- EconometricsDocument7 pagesEconometricsmehrin.morshed1230Pas encore d'évaluation
- Chapter 1 Exercise IVDocument3 pagesChapter 1 Exercise IVLâm ĐoànPas encore d'évaluation
- Mid Term TestDocument6 pagesMid Term Testsilence123444488Pas encore d'évaluation
- Econ301 Final spr22Document12 pagesEcon301 Final spr22Rana AhemdPas encore d'évaluation
- Assignment 2Document2 pagesAssignment 2businesshtrPas encore d'évaluation
- Econometricstutorials Exam QuestionsSelectedAnswersDocument11 pagesEconometricstutorials Exam QuestionsSelectedAnswersFiliz Ertekin100% (1)
- Econometrics Sample QuestionsDocument19 pagesEconometrics Sample QuestionsNoman Moin Ud DinPas encore d'évaluation
- Problem Set 3Document2 pagesProblem Set 3Luca VanzPas encore d'évaluation
- Applied Econometrics Problem Set 3Document4 pagesApplied Econometrics Problem Set 3pablomxrtinPas encore d'évaluation
- ECON 6001 Assignment1 2023Document9 pagesECON 6001 Assignment1 2023雷佳璇Pas encore d'évaluation
- ECN 211 - Key Regression Concepts and Tests in 6 QuestionsDocument7 pagesECN 211 - Key Regression Concepts and Tests in 6 QuestionstargetthisPas encore d'évaluation
- Problem Set 2Document3 pagesProblem Set 2Alejandro álvarez MartínezPas encore d'évaluation
- Exam EmpiricalMethods2SAMPLE 120323Document8 pagesExam EmpiricalMethods2SAMPLE 120323John DoePas encore d'évaluation
- 2326_EC2020_Main EQP v1_FinalDocument19 pages2326_EC2020_Main EQP v1_FinalAryan MittalPas encore d'évaluation
- EDA Final Exam Question PaperDocument2 pagesEDA Final Exam Question Papernipun malikPas encore d'évaluation
- 317 Final ExamDocument6 pages317 Final Examdadu89Pas encore d'évaluation
- Problem Sets (Days 1-6)Document18 pagesProblem Sets (Days 1-6)Harry KwongPas encore d'évaluation
- Review Final ExDocument20 pagesReview Final ExNguyet Tran Thi Thu100% (1)
- On TapDocument6 pagesOn TapVăn QuânPas encore d'évaluation
- Homework 4Document3 pagesHomework 4João Paulo MilaneziPas encore d'évaluation
- Practica 1 (Compatibility Mode) B PDFDocument8 pagesPractica 1 (Compatibility Mode) B PDFRodrigo VelezPas encore d'évaluation
- Final Assignment: 1 InstructionsDocument5 pagesFinal Assignment: 1 InstructionsLanjun ShaoPas encore d'évaluation
- Practice Midterm2 Fall2011Document9 pagesPractice Midterm2 Fall2011truongpham91Pas encore d'évaluation
- MA Econometrics II: Midterm 2019: Instructor: Bipasha Maity Ashoka University Spring Semester 2019 March 13, 2019Document2 pagesMA Econometrics II: Midterm 2019: Instructor: Bipasha Maity Ashoka University Spring Semester 2019 March 13, 2019akshay patriPas encore d'évaluation
- Review 1 SolutionsDocument2 pagesReview 1 SolutionsNgọc Anh Bảo PhướcPas encore d'évaluation
- Homework 02 AnswersDocument12 pagesHomework 02 Answersornelaabegaj_83152390% (1)
- Assignment 2Document5 pagesAssignment 21943361368Pas encore d'évaluation
- Introductory Econometrics Test BankDocument106 pagesIntroductory Econometrics Test BankMinh Hạnhx CandyPas encore d'évaluation
- Econometrics Home Taken ExamDocument2 pagesEconometrics Home Taken Examsabit hussenPas encore d'évaluation
- 7,8-Simple Regression PDFDocument47 pages7,8-Simple Regression PDFKevin HyunPas encore d'évaluation
- Econ5025 Practice ProblemsDocument33 pagesEcon5025 Practice ProblemsTrang Nguyen43% (7)
- HW Econometrics 2Document3 pagesHW Econometrics 2merlinPas encore d'évaluation
- BE Mock Test QuestionsDocument2 pagesBE Mock Test QuestionsCalonneFrPas encore d'évaluation
- Assessing Studies Based On Multiple Regression (SW Ch. 9) : Causal EffectDocument35 pagesAssessing Studies Based On Multiple Regression (SW Ch. 9) : Causal EffectJenningsJingjingXuPas encore d'évaluation
- Econometrics Sheet 2B MR 2024Document5 pagesEconometrics Sheet 2B MR 2024rrrrokayaaashrafPas encore d'évaluation
- Stat5000 HW 1-2Document3 pagesStat5000 HW 1-2vinay kumarPas encore d'évaluation
- ECON209 F2023 - Practice Questions - Midterm 1Document7 pagesECON209 F2023 - Practice Questions - Midterm 1lethihonghahbPas encore d'évaluation
- Suggested Solutions: Problem Set 5: β = (X X) X YDocument7 pagesSuggested Solutions: Problem Set 5: β = (X X) X YqiucumberPas encore d'évaluation
- Solutions - PS5 (DAE)Document23 pagesSolutions - PS5 (DAE)icisanmanPas encore d'évaluation
- Econometrics Final Exam 2012Document13 pagesEconometrics Final Exam 2012james brownPas encore d'évaluation
- Econometrics Problem Set Analyzes Link Between BMI and WagesDocument5 pagesEconometrics Problem Set Analyzes Link Between BMI and Wagespcr123Pas encore d'évaluation
- Understanding Proof: Explanation, Examples and Solutions of Mathematical ProofD'EverandUnderstanding Proof: Explanation, Examples and Solutions of Mathematical ProofPas encore d'évaluation
- Goal SeekDocument3 pagesGoal SeekLutfullah BingolPas encore d'évaluation
- Untitled DocumentDocument1 pageUntitled DocumentLutfullah BingolPas encore d'évaluation
- AD573Document4 pagesAD573Lutfullah BingolPas encore d'évaluation
- TRY Exchange Rate ReportDocument12 pagesTRY Exchange Rate ReportLutfullah BingolPas encore d'évaluation
- Today's Exchange Rate ReportDocument14 pagesToday's Exchange Rate ReportLutfullah BingolPas encore d'évaluation
- Maurice Nicoll The Mark PDFDocument4 pagesMaurice Nicoll The Mark PDFErwin KroonPas encore d'évaluation
- Letter e Lab - HDocument1 pageLetter e Lab - HGladys Grace BorjaPas encore d'évaluation
- Urban LandscapeDocument15 pagesUrban LandscapeAlis Cercel CuciulanPas encore d'évaluation
- Application of The 3Rs Principles For Animals Used For Experiments at The Beginning of The 21st CenturyDocument7 pagesApplication of The 3Rs Principles For Animals Used For Experiments at The Beginning of The 21st CenturySteven BrownPas encore d'évaluation
- Unit 6 Data Presentation and AnalysisDocument85 pagesUnit 6 Data Presentation and AnalysiswossenPas encore d'évaluation
- SCITES Assignment No. 1Document2 pagesSCITES Assignment No. 1Mikealla David100% (1)
- Quiz 6 SolutionsDocument2 pagesQuiz 6 Solutionsrrro0orrrPas encore d'évaluation
- Curiosity and Observation Are The Start of ScienceDocument5 pagesCuriosity and Observation Are The Start of ScienceLorenaPas encore d'évaluation
- Assignment On DataDocument8 pagesAssignment On DataAtikur Rahman100% (1)
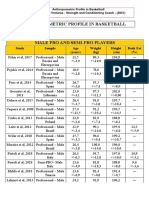
- Basketball: Anthropometric Profile of PlayersDocument6 pagesBasketball: Anthropometric Profile of PlayersAdriano VretarosPas encore d'évaluation
- Research Methods: Content Analysis Field ResearchDocument30 pagesResearch Methods: Content Analysis Field ResearchBeytullah ErdoğanPas encore d'évaluation
- Predictors of Student Performance in Chemistry LabDocument23 pagesPredictors of Student Performance in Chemistry LabGladys Avila100% (1)
- Bourdieu - Public Opinion Does Not ExistDocument7 pagesBourdieu - Public Opinion Does Not ExistmargitajemrtvaPas encore d'évaluation
- Peer Teaching - Laboratory MethodDocument18 pagesPeer Teaching - Laboratory MethodGiri SivaPas encore d'évaluation
- SWU Football Attendance ForecastDocument10 pagesSWU Football Attendance Forecastsonhera sheikhPas encore d'évaluation
- Research Methods SummaryDocument4 pagesResearch Methods SummaryGorishsharmaPas encore d'évaluation
- REVIEW QUESTIONs FOR BRM FINAL EXAMDocument11 pagesREVIEW QUESTIONs FOR BRM FINAL EXAMSang PhanPas encore d'évaluation
- Introduction of HPLCDocument11 pagesIntroduction of HPLCInga Budadoy NaudadongPas encore d'évaluation
- SEMDocument10 pagesSEMshona75Pas encore d'évaluation
- Summary of Kahneman's "Thinking Fast and Slow" - by Mark Looi - MediumDocument10 pagesSummary of Kahneman's "Thinking Fast and Slow" - by Mark Looi - MediumYogeshPas encore d'évaluation
- Mine Black Book ProjectDocument47 pagesMine Black Book ProjectHemal VyasPas encore d'évaluation
- Exercise No 1 FDTDocument3 pagesExercise No 1 FDTCollano M. Noel RogiePas encore d'évaluation
- Punit GhoshDocument4 pagesPunit Ghoshpunit ghoshPas encore d'évaluation
- Practical Research 2 ReviewerDocument3 pagesPractical Research 2 Reviewerlun3l1ght18Pas encore d'évaluation
- Mithcie E.Luntad 9-Our Lady of GuadalupeDocument3 pagesMithcie E.Luntad 9-Our Lady of GuadalupeMitch EnovesoPas encore d'évaluation
- Jurnal Mohammad Anur Faiz 1508E006Document5 pagesJurnal Mohammad Anur Faiz 1508E006Yazta BintaraPas encore d'évaluation
- Self Experminent StudyCaseDocument63 pagesSelf Experminent StudyCasebubblesmPas encore d'évaluation
- What Is Sampling?: PopulationDocument4 pagesWhat Is Sampling?: PopulationFarhaPas encore d'évaluation
- The Aharonov-Bohm Effect in Relativistic Quantum TheoryDocument31 pagesThe Aharonov-Bohm Effect in Relativistic Quantum Theoryfurrygerbil100% (5)
- A. Typologies/dimensions of Research Qualitative and Quantitative Applied Vs BasicDocument5 pagesA. Typologies/dimensions of Research Qualitative and Quantitative Applied Vs BasicJeffrey Es ManzanoPas encore d'évaluation
- Books on fingerprint science and investigationDocument3 pagesBooks on fingerprint science and investigationasb231Pas encore d'évaluation