Vous aimerez peut-être aussi
- PowerScheduler - Build (Q) Results Log - Errors and DefinitionsDocument4 pagesPowerScheduler - Build (Q) Results Log - Errors and DefinitionsMuskegon ISD PowerSchool Support ConsortiumPas encore d'évaluation
- Lab 1 StudentDocument21 pagesLab 1 Studentapi-238878100100% (1)
- Lab 2 - Basic Programming in Java-BESE-10Document9 pagesLab 2 - Basic Programming in Java-BESE-10Waseem AbbasPas encore d'évaluation
- An Overview of AS4678-Earth Retaining StructuresDocument10 pagesAn Overview of AS4678-Earth Retaining StructuressleepyhollowinozPas encore d'évaluation
- Data Preprocessing For PythonDocument3 pagesData Preprocessing For Pythonabdul salamPas encore d'évaluation
- Jupyter LabDocument42 pagesJupyter LabPaul ShaafPas encore d'évaluation
- Data Preparation For Machine Learning Mini CourseDocument19 pagesData Preparation For Machine Learning Mini CourseParinitha B SPas encore d'évaluation
- Assignment 3Document3 pagesAssignment 3Beta WaysPas encore d'évaluation
- Project 1Document4 pagesProject 1aqsa yousafPas encore d'évaluation
- Data Preparation For Machine Learning Mini CourseDocument19 pagesData Preparation For Machine Learning Mini CourseLavanya EaswarPas encore d'évaluation
- Scikit Learn - Quick GuideDocument111 pagesScikit Learn - Quick Guidep7bzsf42bhPas encore d'évaluation
- Dynamics 365 For Field Service Demo Data Loader Fall 2016Document5 pagesDynamics 365 For Field Service Demo Data Loader Fall 2016shorifuli_5Pas encore d'évaluation
- HW2 PDFDocument3 pagesHW2 PDFbakacat1Pas encore d'évaluation
- Scikit-Learn Cookbook Sample ChapterDocument52 pagesScikit-Learn Cookbook Sample ChapterPackt PublishingPas encore d'évaluation
- Homework 3.1 m101jsDocument8 pagesHomework 3.1 m101jsafeukeaqn100% (1)
- CM0427 Assignment 2012Document7 pagesCM0427 Assignment 2012Johnny PricePas encore d'évaluation
- COMP-377 Lab2Document3 pagesCOMP-377 Lab2Rich 1stPas encore d'évaluation
- Regression Week 2: Multiple Linear Regression Assignment 1: If You Are Using Graphlab CreateDocument1 pageRegression Week 2: Multiple Linear Regression Assignment 1: If You Are Using Graphlab CreateSamPas encore d'évaluation
- Python and ML Content For Page 16Document22 pagesPython and ML Content For Page 16Sumaiya KauserPas encore d'évaluation
- Big Data Analytics PracDocument37 pagesBig Data Analytics PracPrince PatilPas encore d'évaluation
- Thesis 2.0 Download FreeDocument6 pagesThesis 2.0 Download Freejennyhillminneapolis100% (2)
- Comp 250 Winter 2023 Final Project UPDATED GetentriesDocument11 pagesComp 250 Winter 2023 Final Project UPDATED GetentrieselyaPas encore d'évaluation
- 1 Data (7 Points) : Img Cv2.imreadDocument2 pages1 Data (7 Points) : Img Cv2.imreadVictor CanoPas encore d'évaluation
- Assignment For C++Document10 pagesAssignment For C++Bhupendra muwalPas encore d'évaluation
- Design Principles & Patterns (S.O.L.I.D Principles)Document17 pagesDesign Principles & Patterns (S.O.L.I.D Principles)Aftab Hakki100% (1)
- Assignment 4Document5 pagesAssignment 4Ahmed HaaPas encore d'évaluation
- DWM Lab ManualDocument92 pagesDWM Lab ManualHemamaliniPas encore d'évaluation
- College For Research and TechnologyDocument8 pagesCollege For Research and TechnologyPatrickBernardoPas encore d'évaluation
- 6.034 Design Assignment 2: 1 Data SetsDocument6 pages6.034 Design Assignment 2: 1 Data Setsupender_kalwaPas encore d'évaluation
- Mongodb DBA HomeworkDocument4 pagesMongodb DBA Homeworkafetuieog100% (1)
- Image Classification: Step-by-step Classifying Images with Python and Techniques of Computer Vision and Machine LearningD'EverandImage Classification: Step-by-step Classifying Images with Python and Techniques of Computer Vision and Machine LearningPas encore d'évaluation
- Lab 1 StudentDocument21 pagesLab 1 StudentyemivesPas encore d'évaluation
- Idrisi TutorialDocument238 pagesIdrisi TutorialsajjanprashantPas encore d'évaluation
- Project Lit Final1Document15 pagesProject Lit Final1poornimaPas encore d'évaluation
- QlikView and Naive BayesDocument10 pagesQlikView and Naive BayesSoumyadeep ChakrabortyPas encore d'évaluation
- Project Manual - Team 591965Document27 pagesProject Manual - Team 591965GameboySmitPas encore d'évaluation
- Riverbed ModelerDocument11 pagesRiverbed ModelerSamuel Lopez RuizPas encore d'évaluation
- Jaq L Exercise 2Document10 pagesJaq L Exercise 2Kanak TripathiPas encore d'évaluation
- Programming ConceptsDocument14 pagesProgramming Conceptstushar rawatPas encore d'évaluation
- Optimizers For NeuralNetworksDocument13 pagesOptimizers For NeuralNetworksAbhishek SainiPas encore d'évaluation
- ML Interview QuestionsDocument146 pagesML Interview QuestionsIndraneelGhoshPas encore d'évaluation
- FAQ For NumPyDocument9 pagesFAQ For NumPyMaisam ElkhalafPas encore d'évaluation
- OOPL Lab ManualDocument51 pagesOOPL Lab ManualRohan ShelarPas encore d'évaluation
- Brief Introduction: Employee Payroll ManagementDocument12 pagesBrief Introduction: Employee Payroll ManagementSiddhant GunjalPas encore d'évaluation
- Class Handout BES320225L Jason BoehningDocument35 pagesClass Handout BES320225L Jason BoehningValentina Coloma ReyesPas encore d'évaluation
- Mini Project ReportDocument10 pagesMini Project ReportVinay KumarPas encore d'évaluation
- Exercise 1 Using Jaql: IBM SoftwareDocument12 pagesExercise 1 Using Jaql: IBM SoftwareKanak TripathiPas encore d'évaluation
- Visual Basic Programming BasicsDocument21 pagesVisual Basic Programming BasicsJavaria MajidPas encore d'évaluation
- Assignment 6 CSCE 155H/RAIK 183H Fall 2016Document2 pagesAssignment 6 CSCE 155H/RAIK 183H Fall 2016s_gamal15Pas encore d'évaluation
- ADSA Lab ManualDocument225 pagesADSA Lab ManualjyothibellaryvPas encore d'évaluation
- hw1 2487155975100812Document6 pageshw1 2487155975100812TrancePas encore d'évaluation
- German Dataset TasksDocument6 pagesGerman Dataset TasksPrateek SinghPas encore d'évaluation
- Advanced Recommender Systems With PythonDocument13 pagesAdvanced Recommender Systems With PythonFabian HafnerPas encore d'évaluation
- Shri Vaishnav Vidyapeeth Vishwavidyalaya, IndoreDocument25 pagesShri Vaishnav Vidyapeeth Vishwavidyalaya, IndoreVishal BagwanPas encore d'évaluation
- Decision Tree-5-5-2021Document31 pagesDecision Tree-5-5-2021RajaPas encore d'évaluation
- Introduction of JavaDocument11 pagesIntroduction of JavaRihan AbalPas encore d'évaluation
- Chapter 1 Introduction To OOPDocument8 pagesChapter 1 Introduction To OOPeyobeshete16Pas encore d'évaluation
- BSIT F21 DS & Algo Lecture 1Document21 pagesBSIT F21 DS & Algo Lecture 1aine hPas encore d'évaluation
- Ee364a Homework SolutionsDocument4 pagesEe364a Homework Solutionsg69f0b2k100% (1)
- Building Java ProgramsDocument94 pagesBuilding Java ProgramsViji RamPas encore d'évaluation
- Mongodb DBA Homework AnswersDocument5 pagesMongodb DBA Homework Answersh41zdb84100% (1)
- Using and Administering Linux: Volume 3: Zero to SysAdmin: Network ServicesD'EverandUsing and Administering Linux: Volume 3: Zero to SysAdmin: Network ServicesPas encore d'évaluation
- Monopoly MemeDocument1 pageMonopoly MemesleepyhollowinozPas encore d'évaluation
- The Office Explains GovernmentDocument1 pageThe Office Explains GovernmentsleepyhollowinozPas encore d'évaluation
- Covid Policies For The LeftDocument1 pageCovid Policies For The LeftsleepyhollowinozPas encore d'évaluation
- Government Health PolicyDocument1 pageGovernment Health PolicysleepyhollowinozPas encore d'évaluation
- As 1418 Cranes (Including Hoists and Winches) - Summary - 1pageDocument1 pageAs 1418 Cranes (Including Hoists and Winches) - Summary - 1pagesleepyhollowinozPas encore d'évaluation
- The Office Explains GovernmentDocument1 pageThe Office Explains GovernmentsleepyhollowinozPas encore d'évaluation
- Covid Policies For The LeftDocument1 pageCovid Policies For The LeftsleepyhollowinozPas encore d'évaluation
- Monopoly MemeDocument1 pageMonopoly MemesleepyhollowinozPas encore d'évaluation
- Solt Washing Machine User Manual ggstlw70rcDocument24 pagesSolt Washing Machine User Manual ggstlw70rcsleepyhollowinozPas encore d'évaluation
- Boosted TreeDocument41 pagesBoosted TreeMic SchPas encore d'évaluation
- Screw Size and ToleranceDocument92 pagesScrew Size and Tolerancenick10686100% (1)
- Javascript Quick ReferenceDocument1 pageJavascript Quick Referencenomaddarcy100% (1)
- What Is HardwareDocument8 pagesWhat Is HardwareMatthew CannonPas encore d'évaluation
- Salesoft Case Analysis: Group 1 - Section BDocument18 pagesSalesoft Case Analysis: Group 1 - Section BSaurabh Singhal100% (2)
- Introduction To Programming Home WORK FOR Y10-01-CT1: Topic 1: Computational ThinkingDocument3 pagesIntroduction To Programming Home WORK FOR Y10-01-CT1: Topic 1: Computational Thinkingmommie magicPas encore d'évaluation
- Lucene RankingDocument13 pagesLucene RankingGayane PetrosyanPas encore d'évaluation
- Extensiones VSCDocument6 pagesExtensiones VSCRefa ChPas encore d'évaluation
- Chapter 05 Finite AutamataDocument22 pagesChapter 05 Finite AutamataMuhammad WaqasPas encore d'évaluation
- Subject: Theory of Autamata & Formal Languages: Kanpur Institute of Technology Kanpur B.Tech (CS) Smester: Iv SemDocument6 pagesSubject: Theory of Autamata & Formal Languages: Kanpur Institute of Technology Kanpur B.Tech (CS) Smester: Iv Semsantkumar333Pas encore d'évaluation
- Lab and Homework 1: Computer Science ClassDocument16 pagesLab and Homework 1: Computer Science ClassPrasad MahajanPas encore d'évaluation
- APIGEE Edge For Private Cloud 4.51.00Document983 pagesAPIGEE Edge For Private Cloud 4.51.00IgnacioPas encore d'évaluation
- EmcoNNECT Your Guide in TechnologyDocument5 pagesEmcoNNECT Your Guide in TechnologyHồ NhậtPas encore d'évaluation
- SPBVNTDocument3 pagesSPBVNTJayakumarPas encore d'évaluation
- All This Premium Accounts by PremiumDocument6 pagesAll This Premium Accounts by PremiumDon MorrisonPas encore d'évaluation
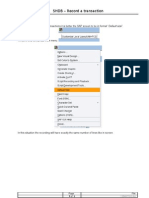
- SHDB Creare RecordingDocument9 pagesSHDB Creare RecordingElena PuscuPas encore d'évaluation
- Failure Modes and EffectFAILURE MODES AND EFFECTS ANALYSIS (FMEA) Analysis (Fmea)Document147 pagesFailure Modes and EffectFAILURE MODES AND EFFECTS ANALYSIS (FMEA) Analysis (Fmea)최재호Pas encore d'évaluation
- R - Manual NICRA ProjectDocument40 pagesR - Manual NICRA Projectherlambang rachmanPas encore d'évaluation
- Final 1Document51 pagesFinal 1jansky37Pas encore d'évaluation
- Instructions For Using Capacity Worksheet: © Satish Thatte, Versionone: Agile Template Set, 3-June-2013Document4 pagesInstructions For Using Capacity Worksheet: © Satish Thatte, Versionone: Agile Template Set, 3-June-2013ActivePas encore d'évaluation
- Patrik PDDL CH2 FHS PDFDocument51 pagesPatrik PDDL CH2 FHS PDFAlFayedArnobPas encore d'évaluation
- DICT Surigao Del Norte Provincial Office, Ferdinand M. Ortiz St. Brgy. Washington, Surigao City Telephone Number: (086) 826-0121Document3 pagesDICT Surigao Del Norte Provincial Office, Ferdinand M. Ortiz St. Brgy. Washington, Surigao City Telephone Number: (086) 826-0121ChinRusSorianoEchevarrePas encore d'évaluation
- Gaussian EleminationDocument7 pagesGaussian EleminationMuhammad RahmandaniPas encore d'évaluation
- Useful SAP System Administration TransactionsDocument7 pagesUseful SAP System Administration TransactionssuperneurexPas encore d'évaluation
- Using The One Page Project Manager 1233449659402110 1Document45 pagesUsing The One Page Project Manager 1233449659402110 1Vapers GombakPas encore d'évaluation
- DBMS Report Mini Project 4Document52 pagesDBMS Report Mini Project 4Prashanth PrashuPas encore d'évaluation
- SEA Open Qualifier - Tournament RulebookDocument11 pagesSEA Open Qualifier - Tournament RulebookFaizal AzmanPas encore d'évaluation
- Using Your Inventory File TemplateDocument15 pagesUsing Your Inventory File TemplateMaria Laura GuzmánPas encore d'évaluation
- Limits & Continuity: Raymond Lapus Mathematics Department, de La Salle UniversityDocument45 pagesLimits & Continuity: Raymond Lapus Mathematics Department, de La Salle UniversitylindamcmaganduirePas encore d'évaluation
- Tobii Pro Spark BrochureDocument2 pagesTobii Pro Spark BrochurenaonedPas encore d'évaluation
- LAB NO 1 PsaDocument3 pagesLAB NO 1 Psashehzad AhmadPas encore d'évaluation