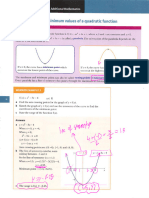
Vous aimerez peut-être aussi
- Cambridge Mathematics AS and A Level Course: Second EditionD'EverandCambridge Mathematics AS and A Level Course: Second EditionPas encore d'évaluation
- Graph quadratic functions and determine equations from graphsDocument60 pagesGraph quadratic functions and determine equations from graphsBrishti AroraPas encore d'évaluation
- Factoring and Algebra - A Selection of Classic Mathematical Articles Containing Examples and Exercises on the Subject of Algebra (Mathematics Series)D'EverandFactoring and Algebra - A Selection of Classic Mathematical Articles Containing Examples and Exercises on the Subject of Algebra (Mathematics Series)Pas encore d'évaluation
- C 03 Quadratic RelationshipsDocument68 pagesC 03 Quadratic Relationshipsmilk shakePas encore d'évaluation
- Solving Quadratic EquationsDocument17 pagesSolving Quadratic EquationsaabhushanPas encore d'évaluation
- Solving Quadratic EquationsDocument17 pagesSolving Quadratic EquationsaabhushanPas encore d'évaluation
- Lecture 20 Row Space NullspaceDocument35 pagesLecture 20 Row Space Nullspacenizad dardPas encore d'évaluation
- Lecture Notes For Chapters 4 & 5: 1 Matrix AlgebraDocument25 pagesLecture Notes For Chapters 4 & 5: 1 Matrix AlgebraRashidAliPas encore d'évaluation
- 331 Notes MatrixDocument15 pages331 Notes MatrixSharifullah ShamimPas encore d'évaluation
- Matrices and Determinants ProjectDocument5 pagesMatrices and Determinants ProjectkunjapPas encore d'évaluation
- 2) C1 Quadratic FunctionsDocument33 pages2) C1 Quadratic FunctionsIshy HerePas encore d'évaluation
- Inverse of MatrixDocument10 pagesInverse of Matrixdx19729510Pas encore d'évaluation
- Vidyarthiplus equation solverDocument174 pagesVidyarthiplus equation solverJatinder KumarPas encore d'évaluation
- Grade 9 Math Q1 M1Document12 pagesGrade 9 Math Q1 M1Renny Romero Luzada100% (2)
- 3NML4Document29 pages3NML4abdulrazaq bibinuPas encore d'évaluation
- Equations Tranformable To Quadratic EquationsDocument6 pagesEquations Tranformable To Quadratic EquationsLiomer Zabala-Mubo CredoPas encore d'évaluation
- Algebraic EquationDocument5 pagesAlgebraic EquationpundekPas encore d'évaluation
- Quadratic EquationDocument35 pagesQuadratic EquationKeerthivasan MohanPas encore d'évaluation
- 09: Quadratic Equations: Key Terms Concept MapDocument1 page09: Quadratic Equations: Key Terms Concept MapVikas MisraPas encore d'évaluation
- Math9 (Pivot)Document24 pagesMath9 (Pivot)Patrick MorgadoPas encore d'évaluation
- Math 9 Lesson 1 Quadratic EquationDocument15 pagesMath 9 Lesson 1 Quadratic EquationJosielyn ValladolidPas encore d'évaluation
- Project in Math: Fourth QuarterDocument2 pagesProject in Math: Fourth QuarterJiyahnBayPas encore d'évaluation
- MAT101 Algebra & Complex NumbersDocument17 pagesMAT101 Algebra & Complex NumbersOussama NaouiPas encore d'évaluation
- Caie as Level Mathematics 9709 Pure 1 v5Document22 pagesCaie as Level Mathematics 9709 Pure 1 v5Karim OsmanPas encore d'évaluation
- Learn Quadratic EquationsDocument7 pagesLearn Quadratic EquationsLance GabrielPas encore d'évaluation
- Algebra and Analytic GeometryDocument14 pagesAlgebra and Analytic GeometryGar PenoliarPas encore d'évaluation
- CEMC's Open Courseware - Enrichment, Extension, and ApplicationDocument2 pagesCEMC's Open Courseware - Enrichment, Extension, and ApplicationMr. Math & SciencePas encore d'évaluation
- Brown and White Doodle Creative Kids Workshop Brochure 1Document2 pagesBrown and White Doodle Creative Kids Workshop Brochure 1dhanliecordovezPas encore d'évaluation
- Topic 4-Modulus FunctionDocument3 pagesTopic 4-Modulus Functionmaths_w_mr_tehPas encore d'évaluation
- CH 2 Form BDocument2 pagesCH 2 Form Bwokofi9784Pas encore d'évaluation
- You Need To Be Able To Plot Graphs of Quadratic Equations.: ExampleDocument11 pagesYou Need To Be Able To Plot Graphs of Quadratic Equations.: ExampleWandaPas encore d'évaluation
- Meridian JC Math PaperDocument8 pagesMeridian JC Math PaperNg Shu QingPas encore d'évaluation
- The coefficient of the linear term is always twice the constant termDocument78 pagesThe coefficient of the linear term is always twice the constant termRaymund PesidasPas encore d'évaluation
- Sat Oc4 May30Document3 pagesSat Oc4 May30Ayan KhanPas encore d'évaluation
- Math 354 Homework Solutions Convex Sets HyperplanesDocument2 pagesMath 354 Homework Solutions Convex Sets HyperplanesRajeshwar SinghPas encore d'évaluation
- Solution Manual For Calculus Hybrid Early Transcendental Functions 6Th Edition by Larson and Edwards Isbn 1285777026 9781285777023 Full Chapter PDFDocument36 pagesSolution Manual For Calculus Hybrid Early Transcendental Functions 6Th Edition by Larson and Edwards Isbn 1285777026 9781285777023 Full Chapter PDFjoseph.parker496100% (12)
- Math Grade 9: Learning Activity Sheet Week 3 and 4 Quarter 1Document13 pagesMath Grade 9: Learning Activity Sheet Week 3 and 4 Quarter 1Sapanta, Junrel R.Pas encore d'évaluation
- Add Math Quadratic FunctionDocument11 pagesAdd Math Quadratic Functionkamil muhammad100% (1)
- Solving Quadratic EquationsDocument16 pagesSolving Quadratic EquationsZlata OsypovaPas encore d'évaluation
- Quantitative Aptitude Inequality (WWW - Freeupscmaterials.wordpress - Com)Document8 pagesQuantitative Aptitude Inequality (WWW - Freeupscmaterials.wordpress - Com)k.palrajPas encore d'évaluation
- AlgebraDocument10 pagesAlgebraneriv65946Pas encore d'évaluation
- More About Equations (Q)Document32 pagesMore About Equations (Q)Kenneth ChiuPas encore d'évaluation
- Play With Math: BhagalpurDocument4 pagesPlay With Math: Bhagalpuryogesh amitPas encore d'évaluation
- The Hindu Senior Secondary School.: Model Papers - Iii Mathematics Class - XiiDocument3 pagesThe Hindu Senior Secondary School.: Model Papers - Iii Mathematics Class - XiiabiPas encore d'évaluation
- Ma214 S23 Part05Document12 pagesMa214 S23 Part05PrateekPas encore d'évaluation
- 11 Maths Sample Papers 2018 2019 Set 3 PDFDocument13 pages11 Maths Sample Papers 2018 2019 Set 3 PDFSARVODAYA GROUPPas encore d'évaluation
- General Instructions:: Guess Paper - 2010 Subject - Maths Class - XIIDocument3 pagesGeneral Instructions:: Guess Paper - 2010 Subject - Maths Class - XIIjnvdwdPas encore d'évaluation
- HW2414Document6 pagesHW2414AlokPas encore d'évaluation
- The Quadratic FunctionDocument4 pagesThe Quadratic FunctionCharalampidis DimitrisPas encore d'évaluation
- SVB Xi Public PreparationDocument49 pagesSVB Xi Public Preparationksivaprasanth0706Pas encore d'évaluation
- Trigonometry Coursebook Explains Essential ConceptsDocument264 pagesTrigonometry Coursebook Explains Essential ConceptsMestreLouPas encore d'évaluation
- Trigbook PDFDocument264 pagesTrigbook PDFsouvikbesu89Pas encore d'évaluation
- CBSE Class 12 Maths Paper 1Document5 pagesCBSE Class 12 Maths Paper 1Ha HiPas encore d'évaluation
- Module1 Intro To Rational FunctionsDocument5 pagesModule1 Intro To Rational FunctionsDaisy Javier AnchetaPas encore d'évaluation
- Term -1 WorksheetDocument3 pagesTerm -1 WorksheetAADHYA KHANNAPas encore d'évaluation
- LONG Dokumen Pub Cambridge Igcse and o Level Additional MathematicsDocument5 pagesLONG Dokumen Pub Cambridge Igcse and o Level Additional MathematicsOmar HamwiPas encore d'évaluation
- 2 - Quadratic FunctionsDocument19 pages2 - Quadratic Functionsjual rumahPas encore d'évaluation
- Solving Quadratic Equations by GraphingDocument21 pagesSolving Quadratic Equations by Graphingariane mylesPas encore d'évaluation
- L XX HJley WT 4 WF 9 Ym VWXHDocument25 pagesL XX HJley WT 4 WF 9 Ym VWXHronakkchawla8Pas encore d'évaluation
- EE 340 Power TransformersDocument59 pagesEE 340 Power TransformersNizar TayemPas encore d'évaluation
- Chap 2 SolutionsDocument8 pagesChap 2 SolutionsNizar TayemPas encore d'évaluation
- 13 - HarmonicsDocument53 pages13 - HarmonicsKurniadi Setyanto50% (2)
- Matlab Finite Element Modeling For Materials Engineers Using MATLABDocument74 pagesMatlab Finite Element Modeling For Materials Engineers Using MATLABPujara ManishPas encore d'évaluation
- Document of DM Zero Eq Liza RDocument52 pagesDocument of DM Zero Eq Liza RNizar TayemPas encore d'évaluation
- Harmonic EspritDocument9 pagesHarmonic EspritNizar TayemPas encore d'évaluation
- Homework 1dc 1Document1 pageHomework 1dc 1Nizar TayemPas encore d'évaluation
- BSC117Document5 pagesBSC117Nizar TayemPas encore d'évaluation
- MIT6 02F12 Lec08Document26 pagesMIT6 02F12 Lec08Nizar TayemPas encore d'évaluation
- Knight Math221 PaperDocument34 pagesKnight Math221 PaperNizar TayemPas encore d'évaluation
- Final Exam Control-System2014aDocument10 pagesFinal Exam Control-System2014aNizar TayemPas encore d'évaluation
- Mobile Robot Control LabDocument21 pagesMobile Robot Control LabNizar TayemPas encore d'évaluation
- Sensors 14 04225rfidDocument14 pagesSensors 14 04225rfidNizar TayemPas encore d'évaluation
- Eece251 - Set1 - 1up DDDocument110 pagesEece251 - Set1 - 1up DDNizar TayemPas encore d'évaluation
- Lecture 1 Circuit 1Document96 pagesLecture 1 Circuit 1Nizar TayemPas encore d'évaluation
- Understanding Steady-State Error in Control SystemsDocument31 pagesUnderstanding Steady-State Error in Control SystemsNizar TayemPas encore d'évaluation
- An Efficient Numerical Method For Computing Eigenvalue Sensitivity WithDocument8 pagesAn Efficient Numerical Method For Computing Eigenvalue Sensitivity With21-08523Pas encore d'évaluation
- MMME 21 1st Long Exam Lecture NotesDocument74 pagesMMME 21 1st Long Exam Lecture NotesGraver lumiousPas encore d'évaluation
- Numerical Methods: System of Linear EquationsDocument63 pagesNumerical Methods: System of Linear EquationsSadek AhmedPas encore d'évaluation
- Stability Analysis of Boiling Water Nuclear Reactors Using Parallel Computing ParadigmsDocument46 pagesStability Analysis of Boiling Water Nuclear Reactors Using Parallel Computing ParadigmsManu RakeshPas encore d'évaluation
- Matrix ComputationsDocument180 pagesMatrix ComputationsheyheyworldPas encore d'évaluation
- Review in Matrix and Determinants PDFDocument89 pagesReview in Matrix and Determinants PDFJan ValentonPas encore d'évaluation
- Linear AlgebraDocument438 pagesLinear AlgebraconkatenatePas encore d'évaluation
- Department of Science & Humanities: Scilab Manual Linear Algebra-Ue15Ma251Document40 pagesDepartment of Science & Humanities: Scilab Manual Linear Algebra-Ue15Ma251NABIL HUSSAIN100% (1)
- CSC336 Assignment 4Document5 pagesCSC336 Assignment 4yellowmoogPas encore d'évaluation
- MIT Numerical Fluid Mechanics Problem SetDocument5 pagesMIT Numerical Fluid Mechanics Problem SetAman JalanPas encore d'évaluation
- Assign 1Document5 pagesAssign 1Yiming LiuPas encore d'évaluation
- Sryedida CFD LecturesDocument132 pagesSryedida CFD LecturesAjay VasanthPas encore d'évaluation
- Morosanu, MosneaguDocument20 pagesMorosanu, MosneaguCalin MorosanuPas encore d'évaluation
- Gaussian Elimination and Lu DecompositionDocument4 pagesGaussian Elimination and Lu DecompositionapuroopmPas encore d'évaluation
- Lecture Notes On Numerical AnalysisDocument152 pagesLecture Notes On Numerical AnalysisospinabustamantePas encore d'évaluation
- Unit IVDocument20 pagesUnit IVapi-352822682Pas encore d'évaluation
- Multiple Choice Answer LinksDocument10 pagesMultiple Choice Answer LinksJoseph RefuerzoPas encore d'évaluation
- TAUCS Developer's ReferenceDocument30 pagesTAUCS Developer's ReferenceMiodrag MarkovicPas encore d'évaluation
- Simultaneous Linear EquationsDocument37 pagesSimultaneous Linear EquationsAnonymous J1Plmv8Pas encore d'évaluation
- Numerical Methods BIT203Document6 pagesNumerical Methods BIT203Yogendra KshetriPas encore d'évaluation
- Eigen Values, Eigen Vectors - Afzaal - 1Document81 pagesEigen Values, Eigen Vectors - Afzaal - 1syedabdullah786Pas encore d'évaluation
- 0.0 Overall Note PDFDocument42 pages0.0 Overall Note PDFNur Hazirah SadonPas encore d'évaluation
- ScientificComputing2eHeath SolutionDocument161 pagesScientificComputing2eHeath SolutionFrederick Melanson100% (10)
- Introduction To Numerical Methods: Jeffrey R. ChasnovDocument63 pagesIntroduction To Numerical Methods: Jeffrey R. ChasnovBaljinder Kamboj100% (1)
- Bempong Kwasi Gyimah 5862816 Assignment 2Document8 pagesBempong Kwasi Gyimah 5862816 Assignment 2Kwasi BempongPas encore d'évaluation
- Advanced Mathematics Module 3: Systems of Linear Equations: Prepared byDocument13 pagesAdvanced Mathematics Module 3: Systems of Linear Equations: Prepared byJohn Steven LlorcaPas encore d'évaluation
- Gill Saunders Shinnerl 1996Document12 pagesGill Saunders Shinnerl 1996mamentxu84Pas encore d'évaluation
- Comp Mech LAB 01Document61 pagesComp Mech LAB 01Lorenzo CampaniniPas encore d'évaluation
- UMFPACK Version 5.5.0 Quick Start GuideDocument19 pagesUMFPACK Version 5.5.0 Quick Start GuidexolraxPas encore d'évaluation
- Hem Raj Pandey Faculty of Science and Technology, School of EngineeringDocument43 pagesHem Raj Pandey Faculty of Science and Technology, School of EngineeringlalitbickPas encore d'évaluation
- Calculus Made Easy: Being a Very-Simplest Introduction to Those Beautiful Methods of Reckoning Which are Generally Called by the Terrifying Names of the Differential Calculus and the Integral CalculusD'EverandCalculus Made Easy: Being a Very-Simplest Introduction to Those Beautiful Methods of Reckoning Which are Generally Called by the Terrifying Names of the Differential Calculus and the Integral CalculusÉvaluation : 4.5 sur 5 étoiles4.5/5 (2)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsD'EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsÉvaluation : 5 sur 5 étoiles5/5 (2)
- Making and Tinkering With STEM: Solving Design Challenges With Young ChildrenD'EverandMaking and Tinkering With STEM: Solving Design Challenges With Young ChildrenPas encore d'évaluation
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeD'EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeÉvaluation : 4 sur 5 étoiles4/5 (2)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingD'EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingÉvaluation : 4.5 sur 5 étoiles4.5/5 (21)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormD'EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormÉvaluation : 5 sur 5 étoiles5/5 (5)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)D'EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)Pas encore d'évaluation
- Psychology Behind Mathematics - The Comprehensive GuideD'EverandPsychology Behind Mathematics - The Comprehensive GuidePas encore d'évaluation
- A Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathD'EverandA Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathÉvaluation : 5 sur 5 étoiles5/5 (1)
- Mental Math Secrets - How To Be a Human CalculatorD'EverandMental Math Secrets - How To Be a Human CalculatorÉvaluation : 5 sur 5 étoiles5/5 (3)
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldD'EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldÉvaluation : 3 sur 5 étoiles3/5 (79)
- Math Magic: How To Master Everyday Math ProblemsD'EverandMath Magic: How To Master Everyday Math ProblemsÉvaluation : 3.5 sur 5 étoiles3.5/5 (15)
- How Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsD'EverandHow Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsÉvaluation : 3.5 sur 5 étoiles3.5/5 (9)
- Classroom-Ready Number Talks for Kindergarten, First and Second Grade Teachers: 1,000 Interactive Activities and Strategies that Teach Number Sense and Math FactsD'EverandClassroom-Ready Number Talks for Kindergarten, First and Second Grade Teachers: 1,000 Interactive Activities and Strategies that Teach Number Sense and Math FactsPas encore d'évaluation
- Strategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceD'EverandStrategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidencePas encore d'évaluation
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.D'EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Évaluation : 5 sur 5 étoiles5/5 (1)
- Limitless Mind: Learn, Lead, and Live Without BarriersD'EverandLimitless Mind: Learn, Lead, and Live Without BarriersÉvaluation : 4 sur 5 étoiles4/5 (6)